Download as PDF, PPTX














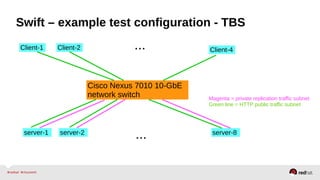

![RHS performance monitoring
•Start with network
•Are there hot spots on the servers or clients?
•Gluster volume profile your-volume [ start | info ]
•Perf. Copilot plugin
•Gluster volume top your-volume [ read | write | opendir | readdir ]
•Perf-copilot demo](https://image.slidesharecdn.com/redhatstorageserveradministrationdeepdive-140513143938-phpapp01/85/Red-Hat-Storage-Server-Administration-Deep-Dive-29-320.jpg)


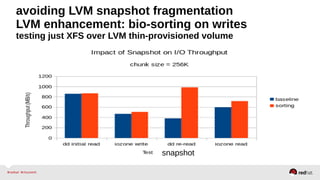
![LVM thin-p + snapshot testing
XFS file system
LVM thin-p volume
LVM pool built from LVM PV
RAID6 12-drive volume
LSI MegaRAID controller
Snapshot[1] Snapshot[n]
...](https://image.slidesharecdn.com/redhatstorageserveradministrationdeepdive-140513143938-phpapp01/85/Red-Hat-Storage-Server-Administration-Deep-Dive-32-320.jpg)
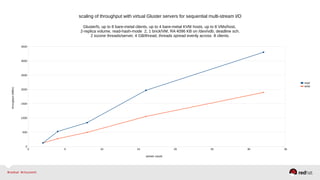
![Scalability using virtual RHS servers
RHSS VM[1]
3 GB RAM, 2 cores
...
RHSS VM[8]
3 GB RAM, 2 cores
RHSS VM[1]
3 GB RAM, 2 cores
...
RHSS VM[8]
3 GB RAM, 2 cores
...
KVM host 1 KVM host N
10-GbE Switch
Client[1] Client[2] Client[2n]...](https://image.slidesharecdn.com/redhatstorageserveradministrationdeepdive-140513143938-phpapp01/85/Red-Hat-Storage-Server-Administration-Deep-Dive-34-320.jpg)
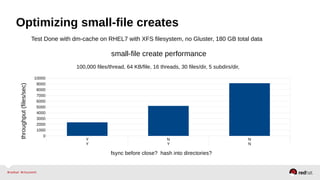
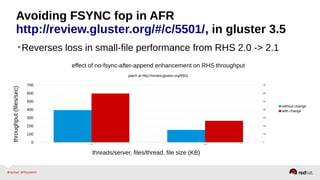


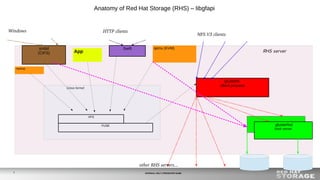
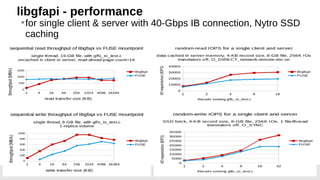
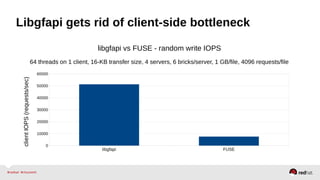
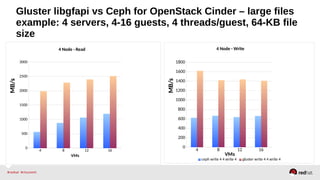
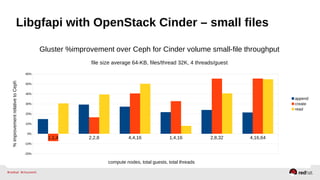
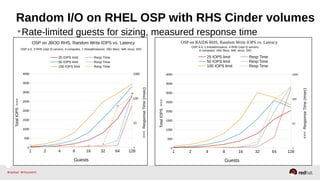
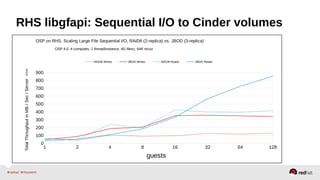
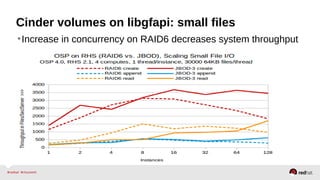
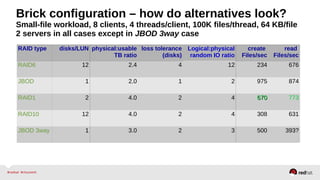
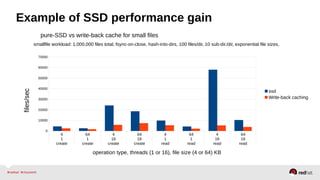
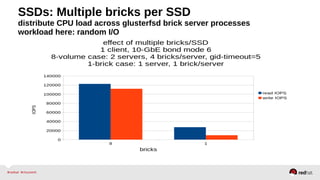
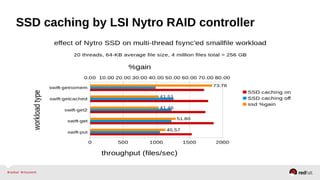
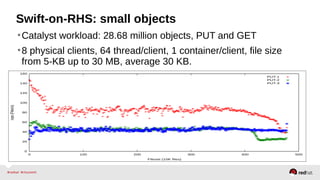
The document outlines the advancements in Red Hat Storage (RHS) performance since the 2013 Summit and details the improvements made in libgfapi, which increases performance for high-IOPS applications by eliminating bottlenecks. It discusses the configuration alternatives for optimal storage and compares the performance of libgfapi against other storage solutions like Ceph in various scenarios, particularly for OpenStack Cinder volumes. Future directions for RHS performance include enhancements in thin provisioning, snapshot capabilities, small-file optimizations, and overall scalability.








































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














