Download as PDF, PPTX





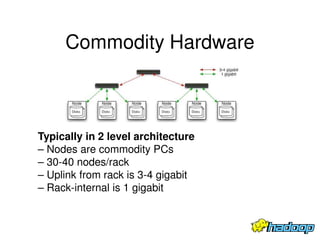

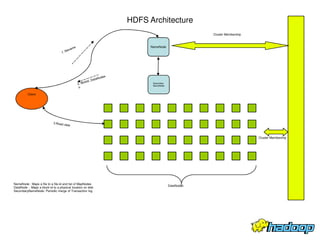

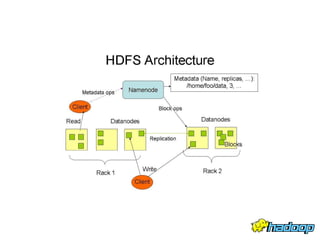















The document summarizes Apache Hadoop, an open-source software framework for distributed storage and processing of large datasets across clusters of computers. It describes the key components of Hadoop including the Hadoop Distributed File System (HDFS) which stores data reliably across commodity hardware, and the MapReduce programming model which allows distributed processing of large datasets in parallel. The document provides an overview of HDFS architecture, data flow, fault tolerance, and other aspects to enable reliable storage and access of very large files across clusters.























































































