

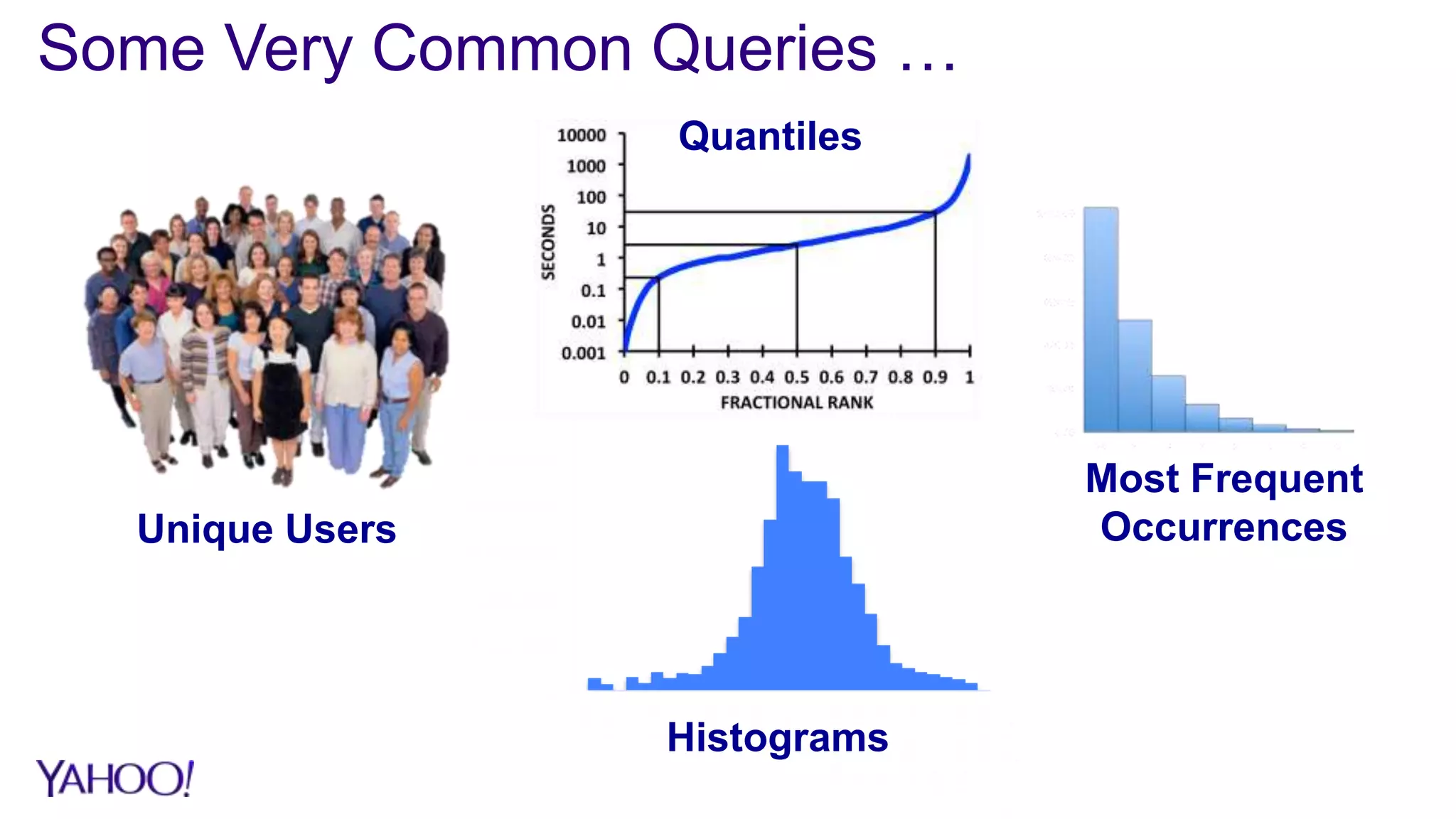

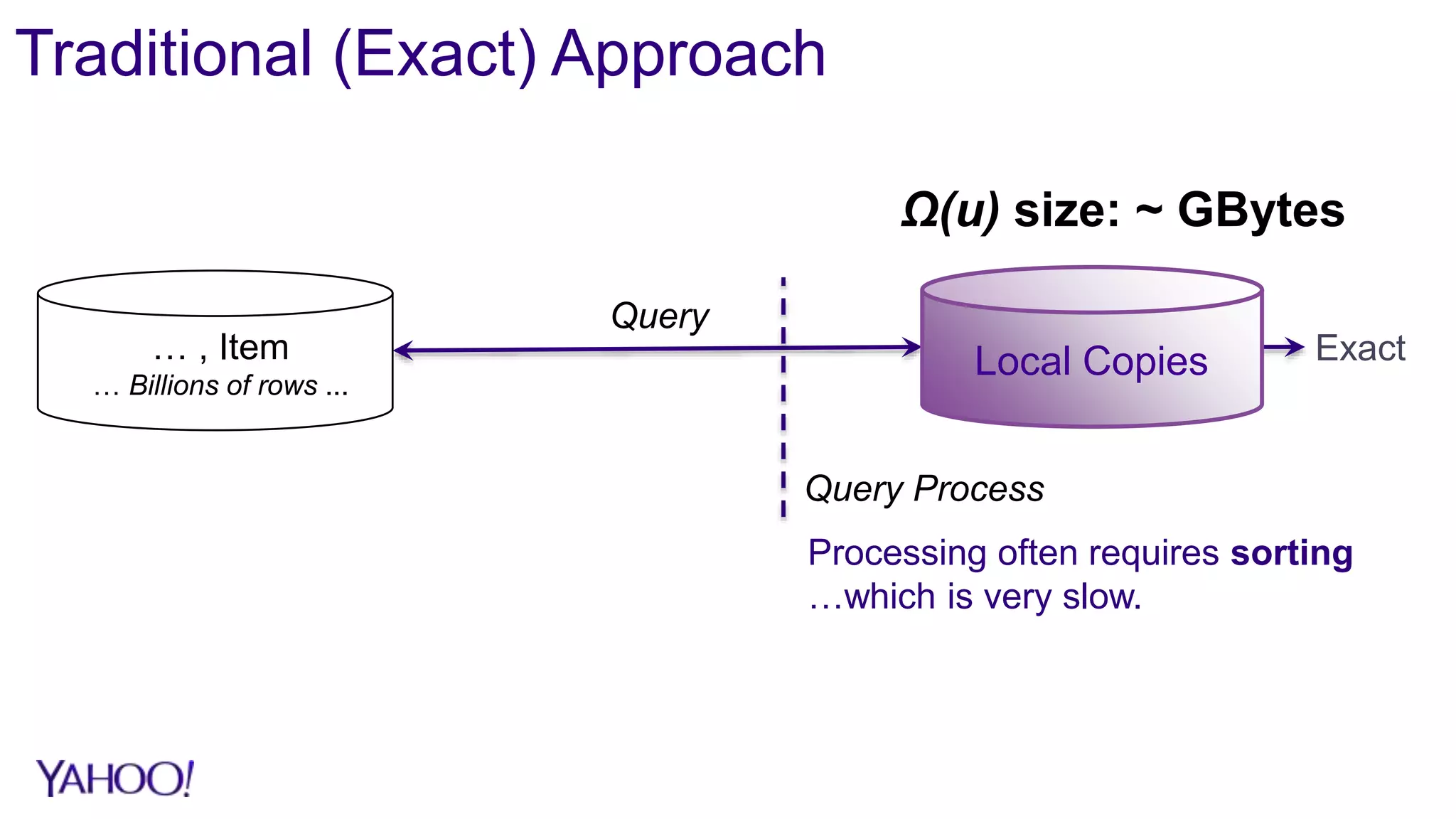
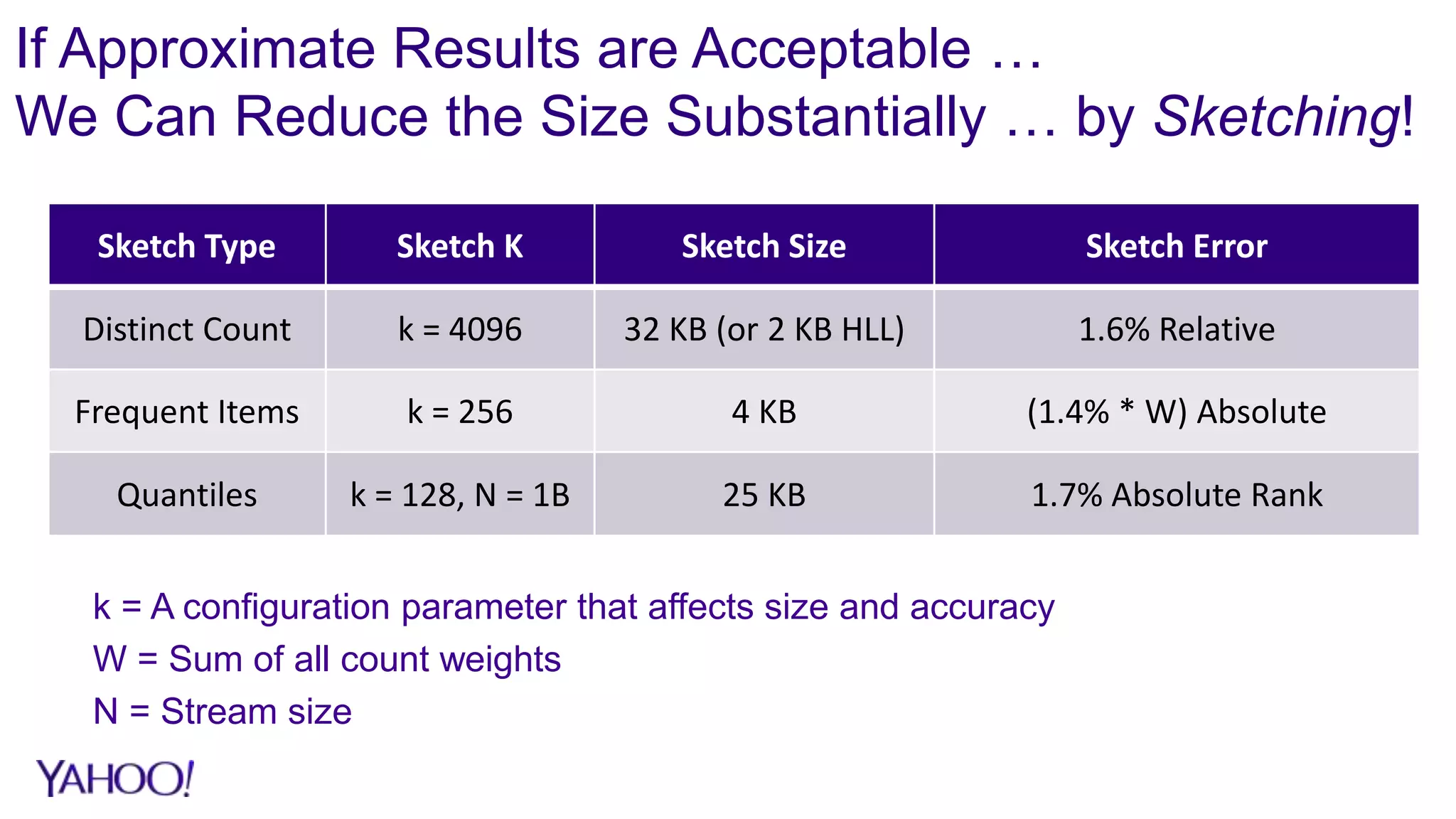


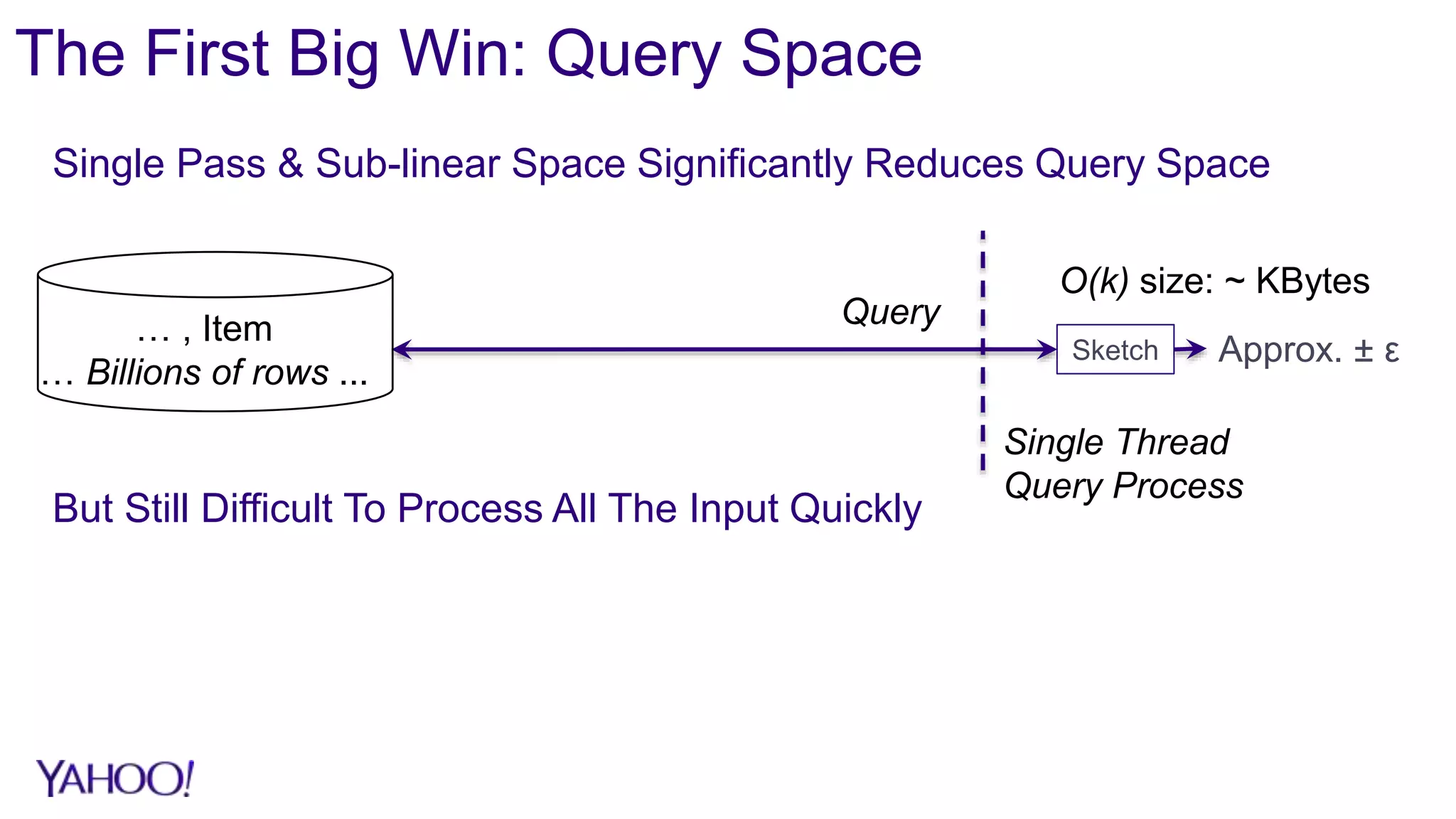









1. Sketch algorithms provide approximate query results with sub-linear space and processing time, enabling analysis of big data that would otherwise require prohibitive resources. 2. Case studies show sketches reduce storage by over 90% and processing time by over 95% compared to exact algorithms, enabling real-time querying and rollups across multiple dimensions that were previously infeasible. 3. The DataSketches library provides open-source implementations of popular sketch algorithms like Theta, HLL, and quantiles sketches, with code samples and adapters for systems like Hive, Pig, and Druid.








































































































