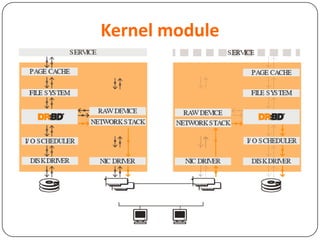
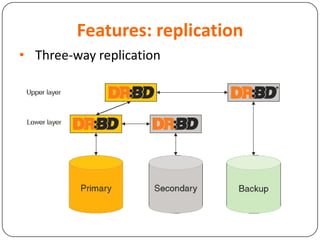
This document provides an overview of Distributed Replicated Block Device (DRBD), which is a software-based storage solution that mirrors the contents of block devices across multiple nodes in real-time. It describes DRBD's architecture including kernel modules, user space tools, resource configuration, roles, modes, features around efficient synchronization and data verification, and limitations.




























































































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)






