



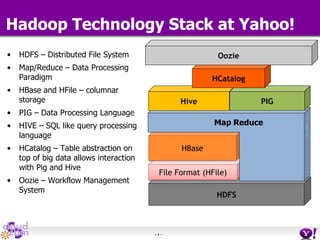
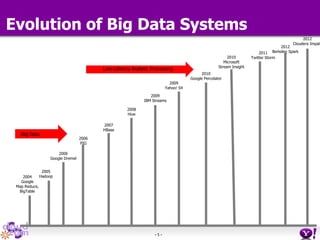







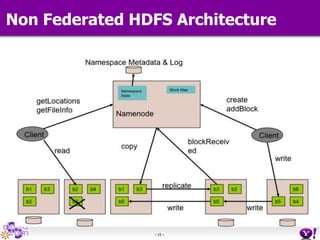
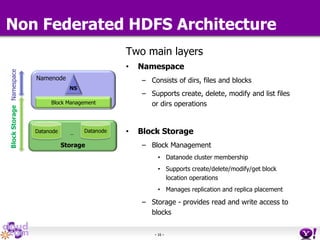
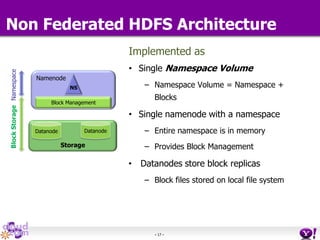

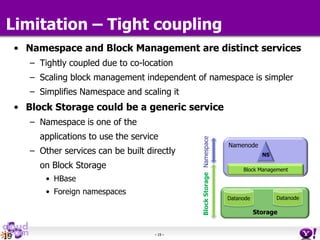
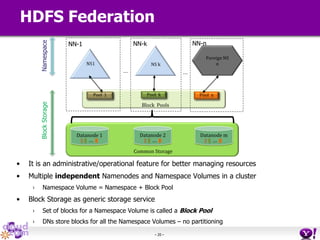
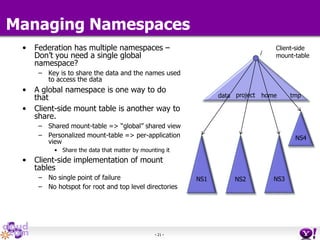













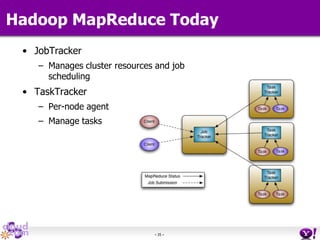




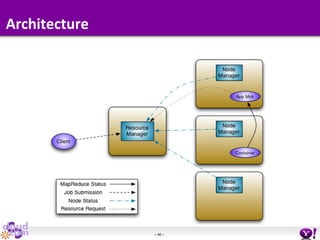
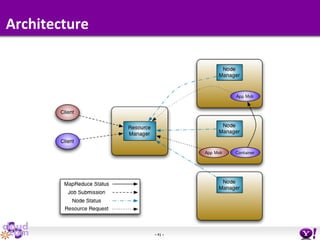
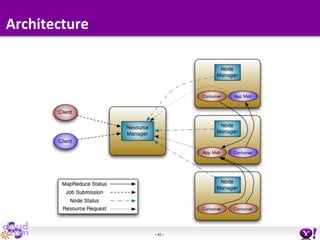

















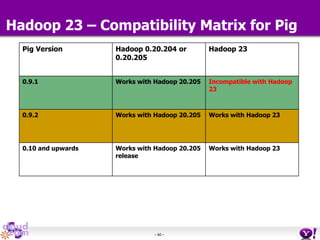

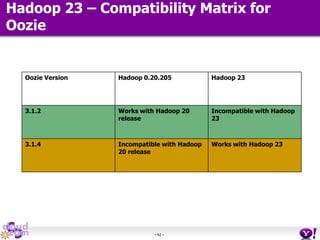















- HDFS Federation allows Hadoop to scale beyond the limitations of a single namespace by splitting the namespace across multiple independent namenodes. Each namenode manages its own namespace volume consisting of a namespace and block pool. - A client-side mount table provides a virtual unified namespace by mapping namespace volumes to namenodes, hiding the federation details from users and applications. - HDFS Federation provides wire compatibility by requiring clients to use the same version of Hadoop as the servers, and supports existing HDFS functionality like append, sticky bits, and new APIs like FileContext.



































































