







![ Single Namespace for entire cluster
Files are broken up into sequence blocks
– For a file all blocks except the last are of the same size.
– Each block replicated on multiple DataNodes
Data Coherency
– Write-once-read-many access model
– Client can only add/append to files, restricts to random change
Intelligent Client
– Client can find location of blocks
– Client accesses data directly from DataNode [Q: How it is possible ?]
--- User data never flows through the NameNode
Distributed file system](https://image.slidesharecdn.com/introductionhdfs2-140513035449-phpapp01/85/Hadoop-HDFS-Architeture-and-Design-9-320.jpg)





![Benefit of Block abstraction
A file can be larger than any single disk in the network.
Simplify the storage subsystem.
Providing fault tolerance and availability.
Indepedent processing, failureover and distribute the
computaion. [Q: How it is independent ? ]](https://image.slidesharecdn.com/introductionhdfs2-140513035449-phpapp01/85/Hadoop-HDFS-Architeture-and-Design-15-320.jpg)

![ Data Integrity maintained in block level. [Q: Why it is block level not in
file level?]
Client copies data along with check sum and client computes the
checksum of every block , it verifies that the corresponding
checksums match. If does not match, the client can retrieve the
block from a replica. The corrupt block delete a replica will
create.
Verified after each operation. What if access foe long time? that
might result in data corruption. Also checked periodically.
Data Integrity](https://image.slidesharecdn.com/introductionhdfs2-140513035449-phpapp01/85/Hadoop-HDFS-Architeture-and-Design-17-320.jpg)



![[what, how and where ]
The NameNode maintains the namespace tree
Mapping of datanode to list of blocks
Receiving heartbeats and Monitor datanodes health.
Replicate missing blocks.
Recording the file system changes.
Authorization & Authentication.
Name node functions](https://image.slidesharecdn.com/introductionhdfs2-140513035449-phpapp01/85/Hadoop-HDFS-Architeture-and-Design-21-320.jpg)

![[Read, Write, Report ]
During startup each DataNode connects to the NameNode and
performs a handshake. The purpose of the handshake is to
verify the namespace ID and the software version of the
DataNode. If either does not match that of the NameNode, the
DataNode automatically shuts down.
Serves read, write requests, performs block creation, deletion,
and replication upon instruction from Namenode
Periodically send heartbeats and block reports to Namenode
A DataNode identifies block replicas in its possession to the
NameNode by sending a block report.
A block report contains the block ID, the generation stamp and the
length for each block replica the server hosts
Data Node functions](https://image.slidesharecdn.com/introductionhdfs2-140513035449-phpapp01/85/Hadoop-HDFS-Architeture-and-Design-23-320.jpg)



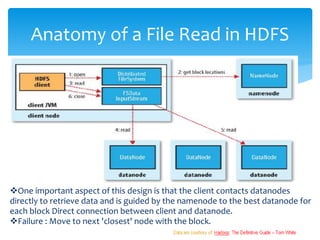
















HDFS is a distributed file system designed for storing very large data files across commodity servers or clusters. It works on a master-slave architecture with one namenode (master) and multiple datanodes (slaves). The namenode manages the file system metadata and regulates client access, while datanodes store and retrieve block data from their local file systems. Files are divided into large blocks which are replicated across datanodes for fault tolerance. The namenode monitors datanodes and replicates blocks if their replication drops below a threshold.


















































































