Download as PDF, PPTX






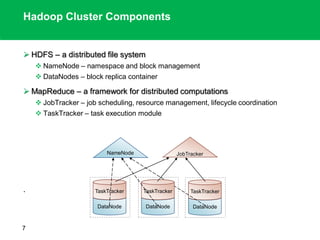


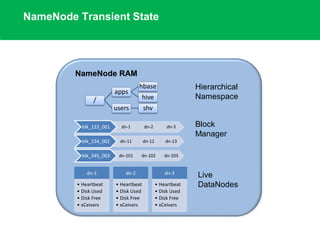



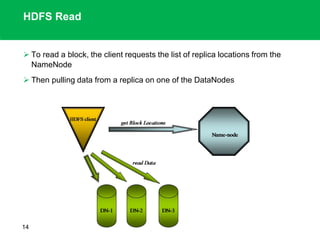

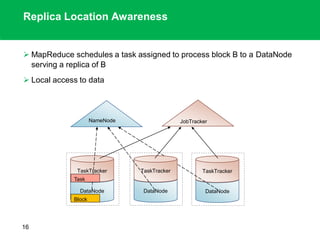
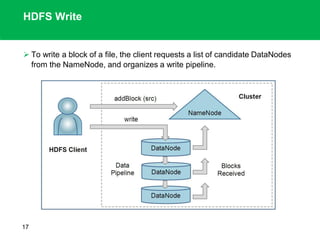










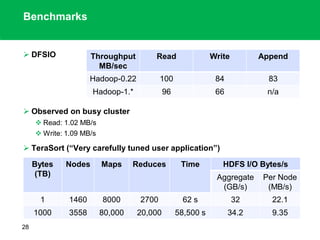












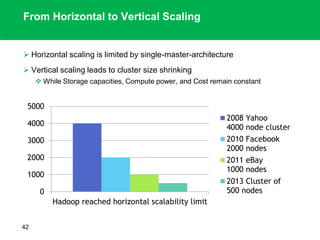
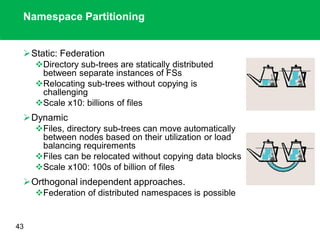



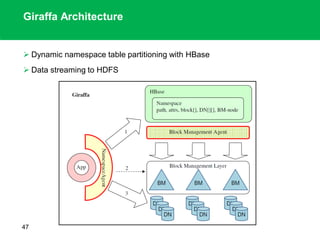



The document outlines the design principles and architecture of the Hadoop Distributed File System (HDFS), emphasizing its scalability, reliability, and efficient data processing capabilities. It details the core components such as the namenode and datanodes, block management, and the operational protocols for reading and writing files within HDFS. Additionally, it discusses future developments like HDFS federation and enhancements in high availability and MapReduce functionalities.