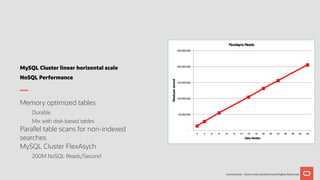
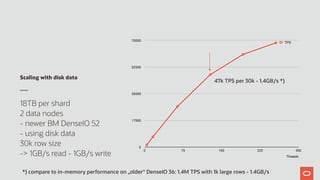
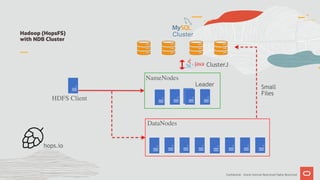
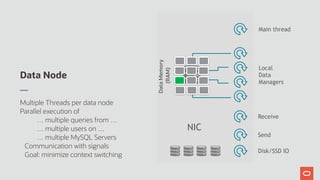
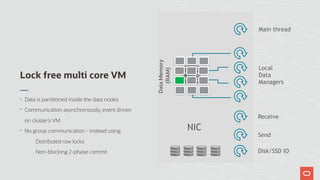
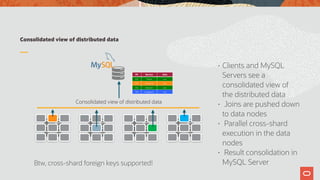
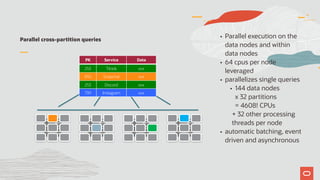
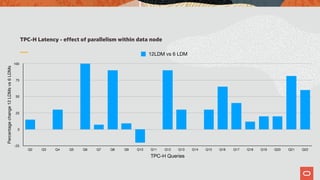
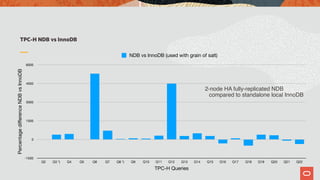
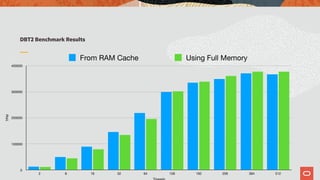
The document discusses the scalability and performance of MySQL Cluster, showcasing its ability to handle high transaction rates and improve read/write operations through advancements like parallel execution and memory optimization. It details benchmarks, configurations, and comparisons with competitors, emphasizing strong consistency and durability with ACID compliance. Various tests, including YCSB and dbt2, underline the effectiveness of MySQL Cluster in distributed environments with extensive data handling capabilities.















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












