Download as PDF, PPTX






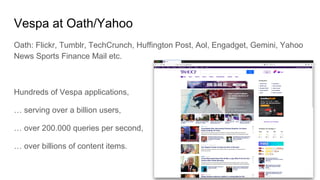




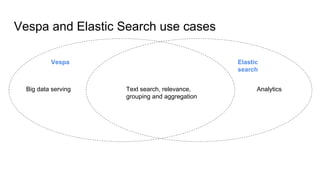
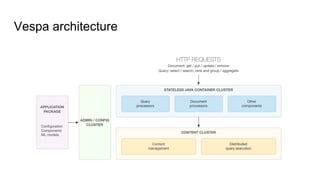
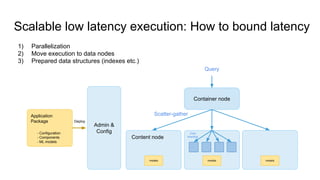


The document discusses Vespa, an open-source platform for big data serving that enables real-time data processing and decision-making using learned models. It outlines the maturity levels of big data usage, exemplifies its applications in fraud detection and content recommendations, and highlights Vespa's ability to handle large-scale, low-latency computations over structured and unstructured data. The platform is positioned as a more efficient alternative to traditional systems for search and recommendation tasks, integrating machine learning capabilities for enhanced results.




![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































