Downloaded 150 times



![HBASEATBLOOMBERG//
TIME SERIES AND HBASE
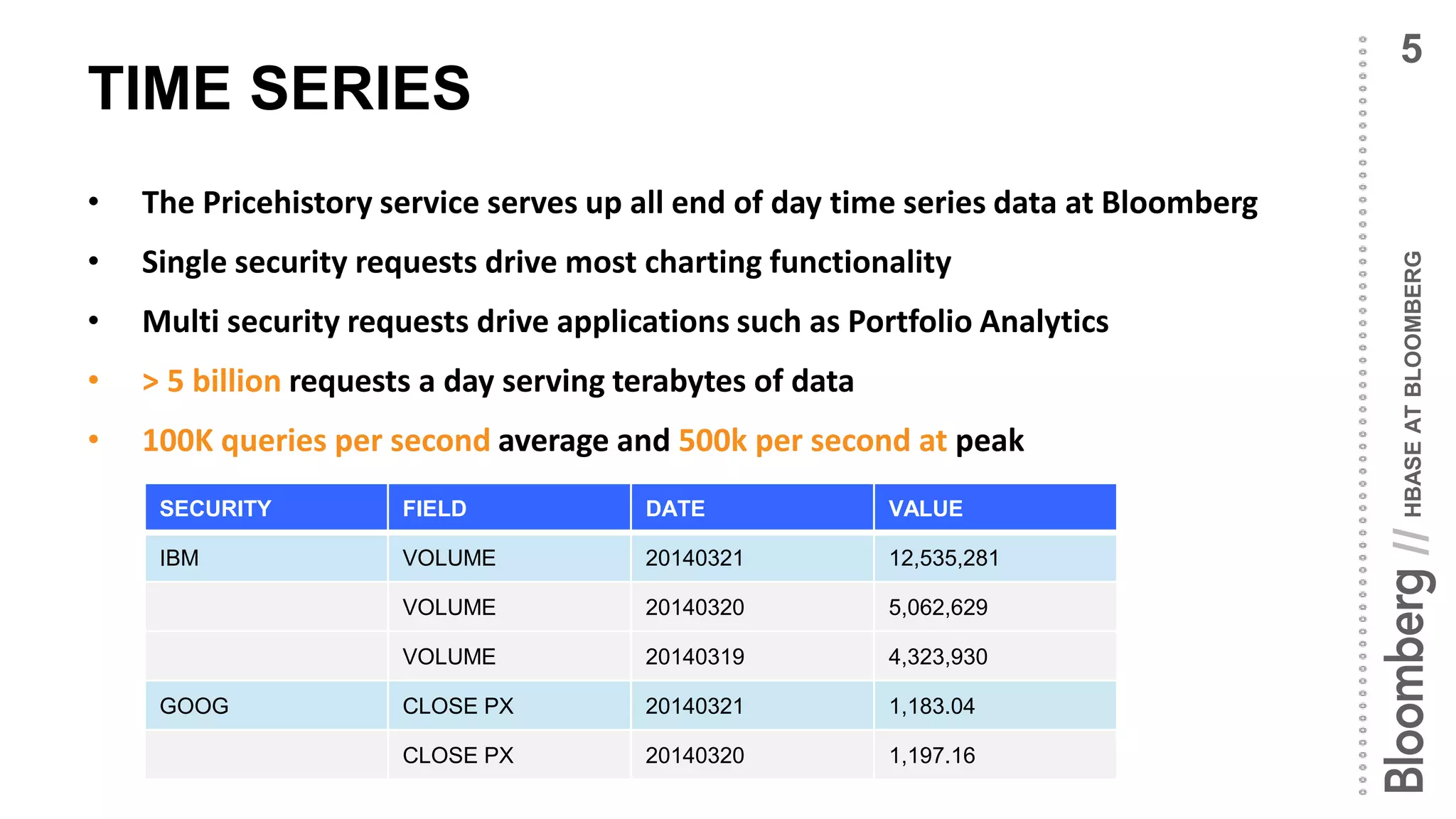
• Time series data fetches are embarrassingly parallel
• Simplistic data types and models mean we do not require rich type
support or query capabilities
• No need for joins, lookups only by [security, field, date]
• Data sets are large enough to require manual sharding…
administrative overhead
• Require a commodity framework to consolidate various disparate
systems built over time and bring about simplicity
• Frameworks bring benefit of additional analytical tools
HBase is an excellent fit for this problem domain
6](https://image.slidesharecdn.com/casestudies-session4a-140616154303-phpapp01/75/HBase-at-Bloomberg-High-Availability-Needs-for-the-Financial-Industry-6-2048.jpg)
![HBASEATBLOOMBERG//
OUR REQUIREMENTS FOR HBASE
• Read performance – fast with low variance
• High availability
• Operational simplicity
• Efficient use of our hardware
[16 cores, 100+ GB RAM, SSD storage]
• Bloomberg has been investing in all these aspects of HBase
• In the rest of this talk, we’ll focus on High Availability](https://image.slidesharecdn.com/casestudies-session4a-140616154303-phpapp01/75/HBase-at-Bloomberg-High-Availability-Needs-for-the-Financial-Industry-7-2048.jpg)


![HBASEATBLOOMBERG//
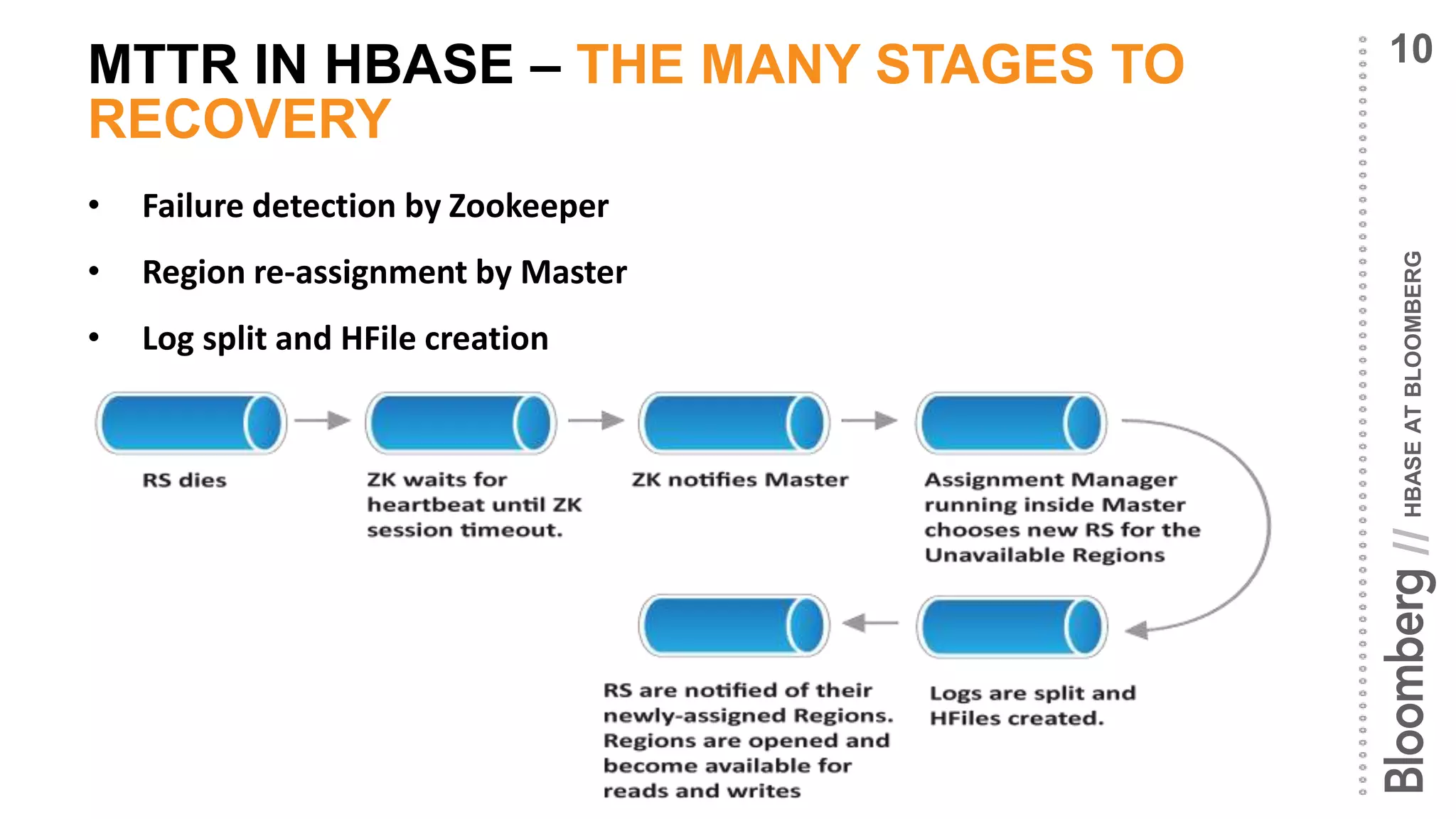
MTTR – A BRIEF HISTORY*
• Distributed log split [HBASE-1364]
• Routing around datanode failures via the hdfs stale state [HDFS-3912,
HDFS-4350]
• Assignment manager enhancements [HBASE-7247]
• Multicast notifications to clients with list of failed Region Servers
• Distributed log replay [HBASE-7006]
…
All this phenomenal work means HBase MTTR is now in
the order of 10s of seconds
11](https://image.slidesharecdn.com/casestudies-session4a-140616154303-phpapp01/75/HBase-at-Bloomberg-High-Availability-Needs-for-the-Financial-Industry-11-2048.jpg)



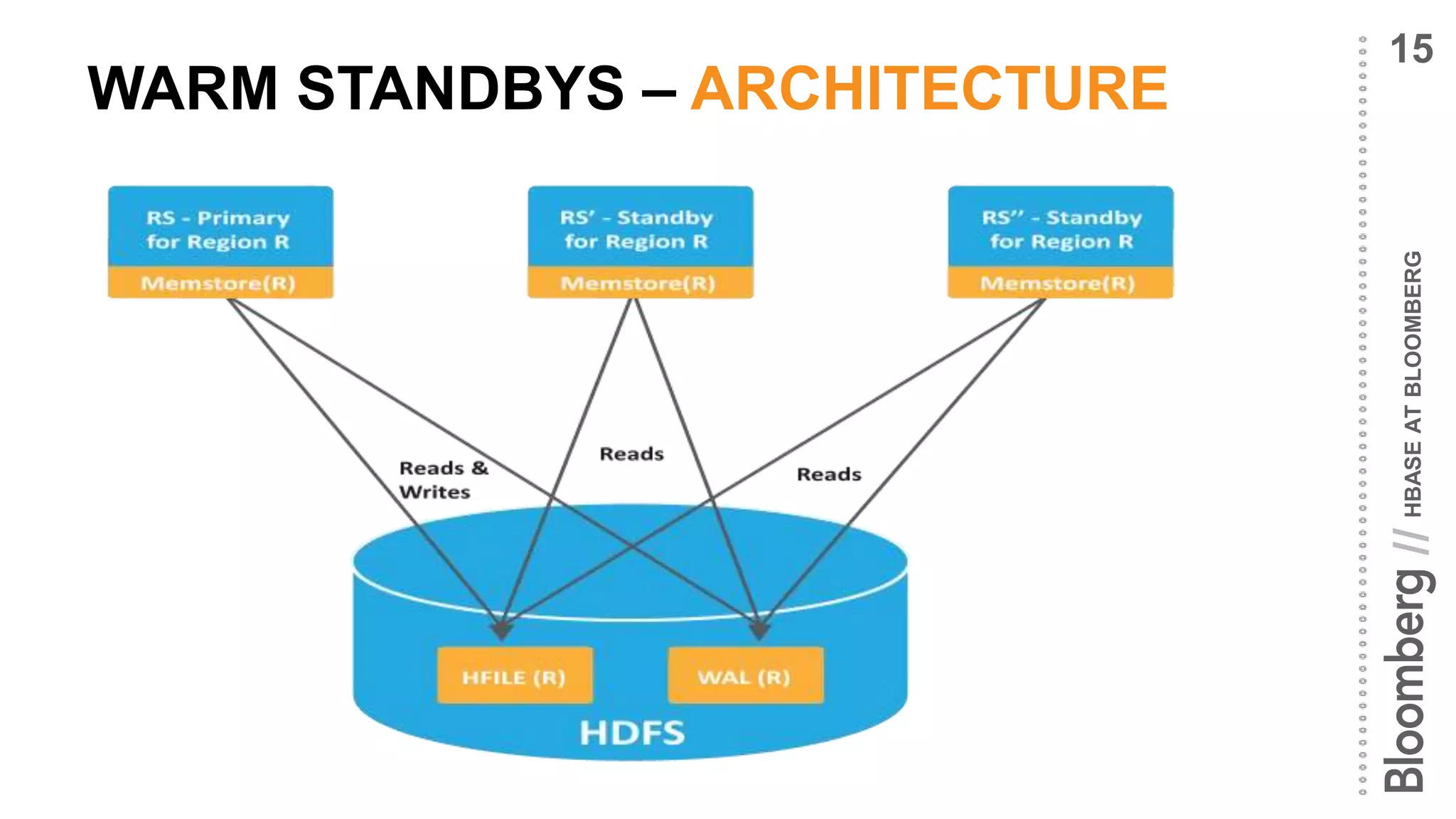










Bloomberg utilizes HBase to manage time series data, focusing on high availability and operational simplicity to handle billions of requests daily. The organization prioritizes fast read performance and efficient hardware use while implementing disaster recovery models across multiple data centers. Upcoming improvements aim to enhance data recovery times and address multi-tenancy challenges in the HBase architecture.











































































































