Downloaded 44 times







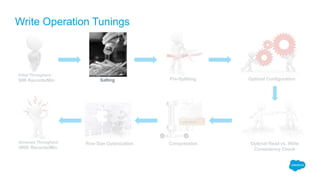

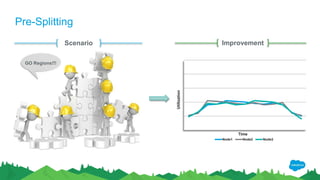
![Pre-Splitting
Outline: Pre-Splitting helps to create multiple regions during table creation which will help to
reap the benefits of salting
How do I pre-split a HBase table?
Pre-splitting can be done by providing split points during table creation
Example: create ‘table_name’, ‘cf_name’, SPLITS => [‘a’ , ‘m’]
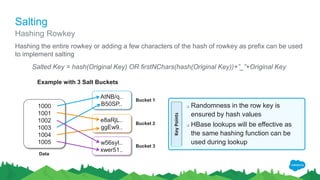
AtNB/q..
B50SP..
e8aRjL..
ggEw9..
w56syI..
xwer51..
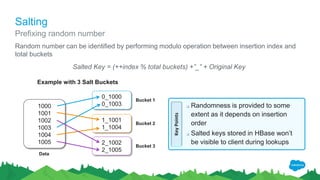
Bucket 1 [‘’ -> ‘a’]
Bucket 2 [‘a’ -> ‘m’]
Bucket 3 [‘m’ -> ‘’]
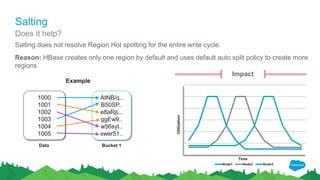
1000
1001
1002
1003
1004
1005
Data](https://image.slidesharecdn.com/170622velocityranjeethkathiresangurpreetmultani-170626023727/85/Scaling-HBase-for-Big-Data-22-320.jpg)
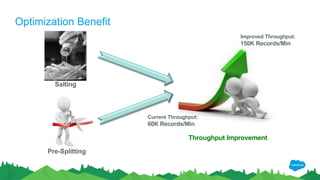


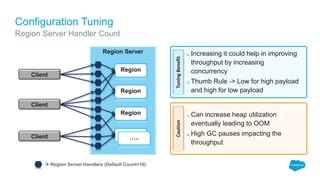
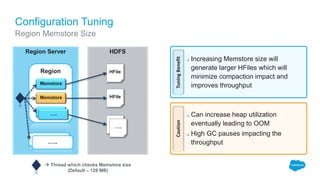
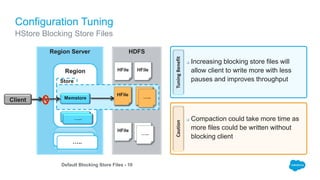
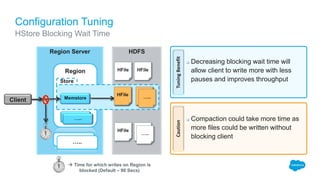
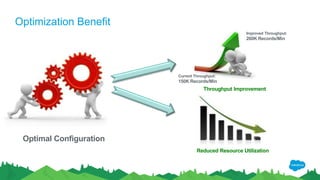
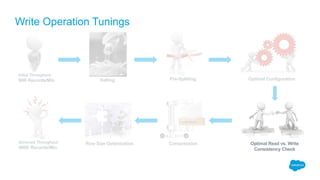


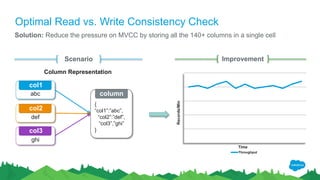
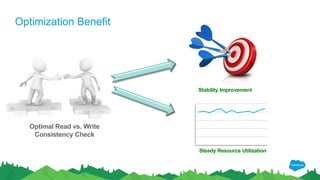

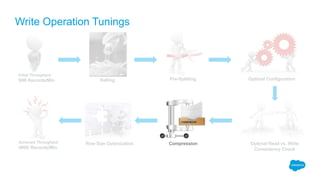

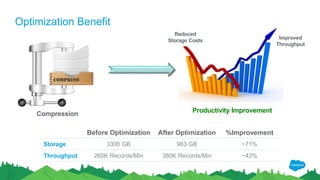
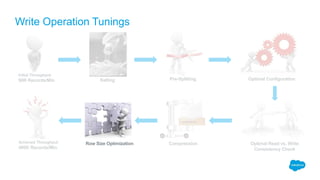
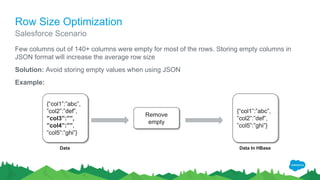
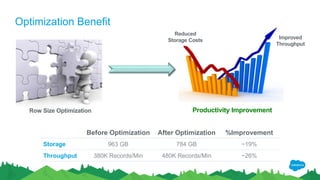

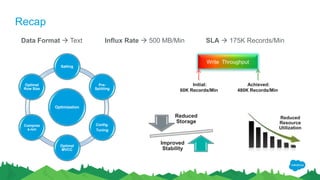





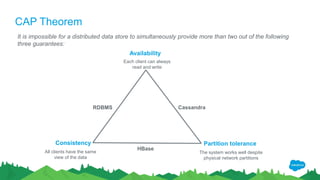
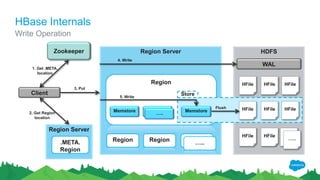
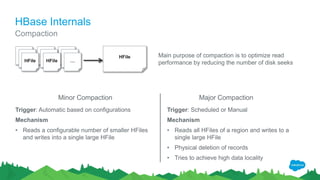
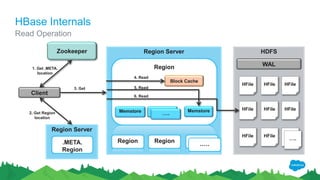
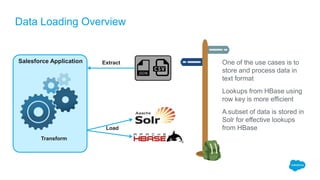
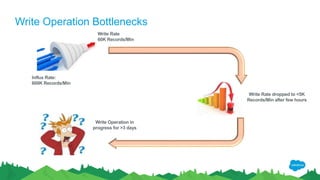
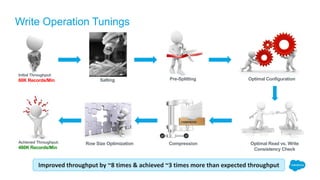
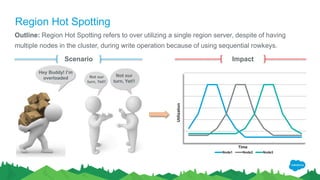
The document outlines the roles of Ranjeeth Kathiresan and Gurpreet Multani as senior and principal software engineers at Salesforce, respectively, focusing on performance tuning and scalability of Apache HBase for big data applications. It covers essential concepts such as the CAP theorem, HBase internals, data loading use cases, bottlenecks in write operations, and various optimization techniques like salting, pre-splitting, and configuration tuning that significantly improves write throughput. Finally, it addresses best practices for row key design and when to use HBase, emphasizing its suitability for high-volume, real-time data access.























































































