Download as PDF, PPTX




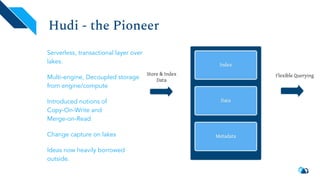


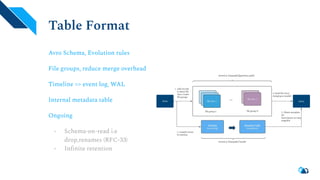
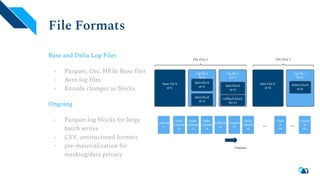



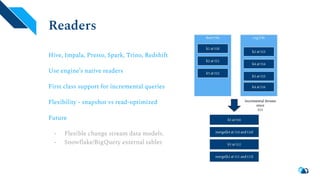

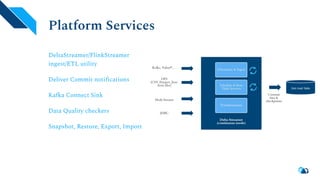


















Apache Hudi is a serverless transactional layer designed for data lakes that supports both streaming and batch pipelines, enabling efficient data processing. It features components for table metadata management, indexing, and concurrency control, while ensuring scalability on Hadoop-compatible storage systems. The platform has an active community contributing to ongoing improvements and new features such as indexing, schema evolution, and integration with various data processing engines.































![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)







