HBase and OpenTSDB Practices at Huawei describes HBase and OpenTSDB practices at Huawei including:
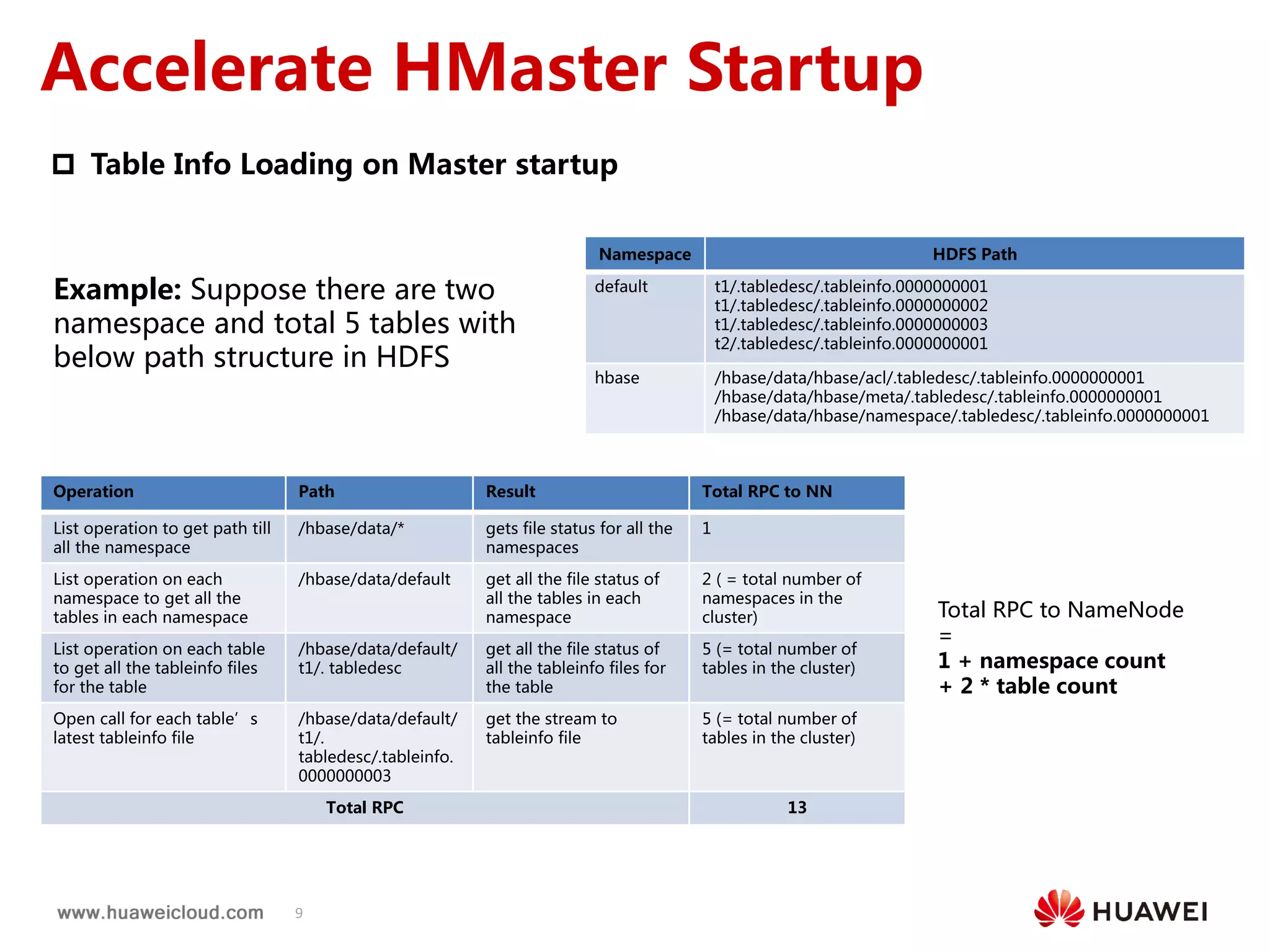
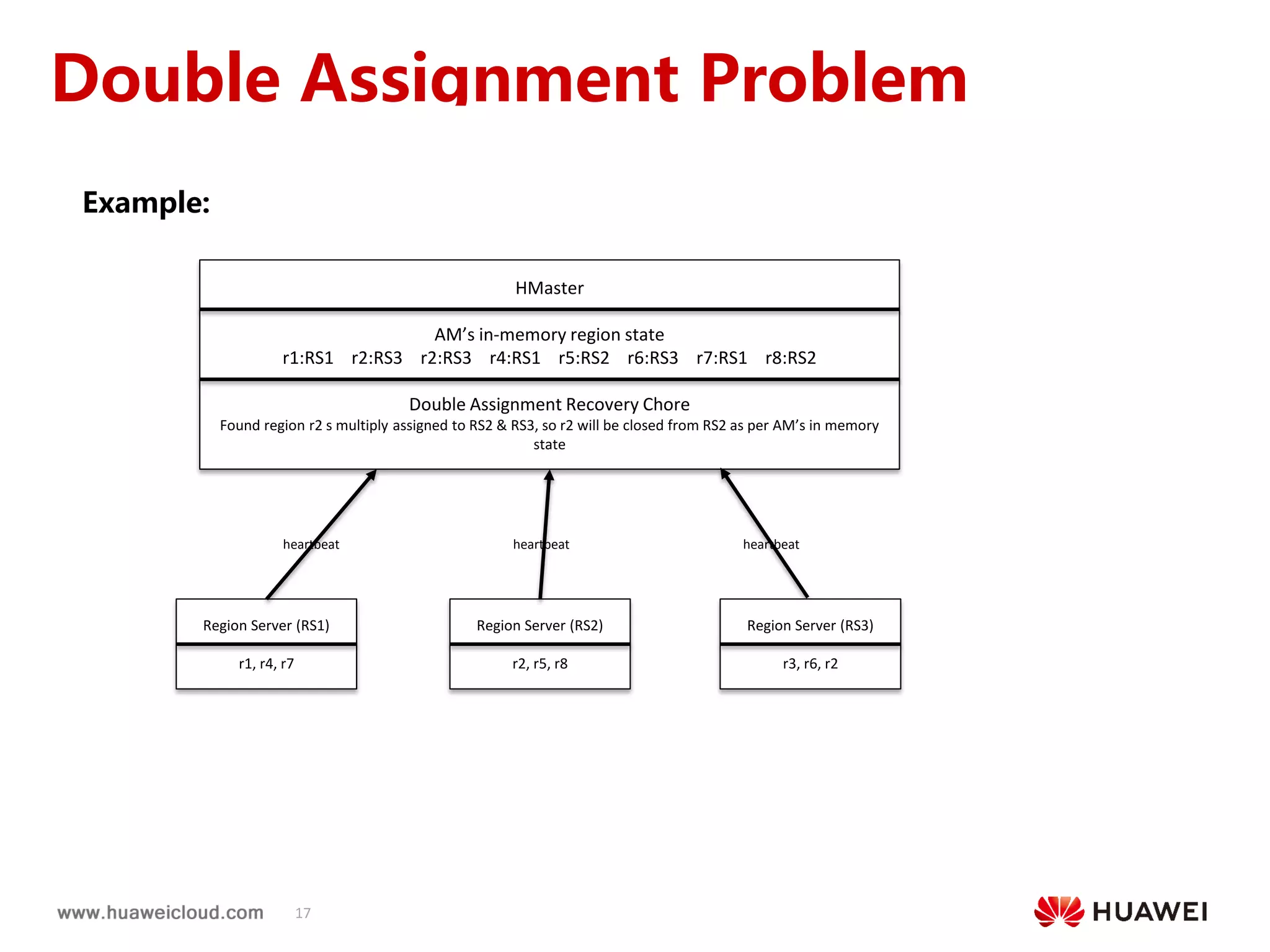
1) HBase practices such as accelerating HMaster startup time by parallelizing region locality computation, enhancing replication by configuring peer cluster principals and adaptive call timeouts, and ensuring reliable region assignment through periodic recovery of stuck regions and detection of duplicate region assignments.
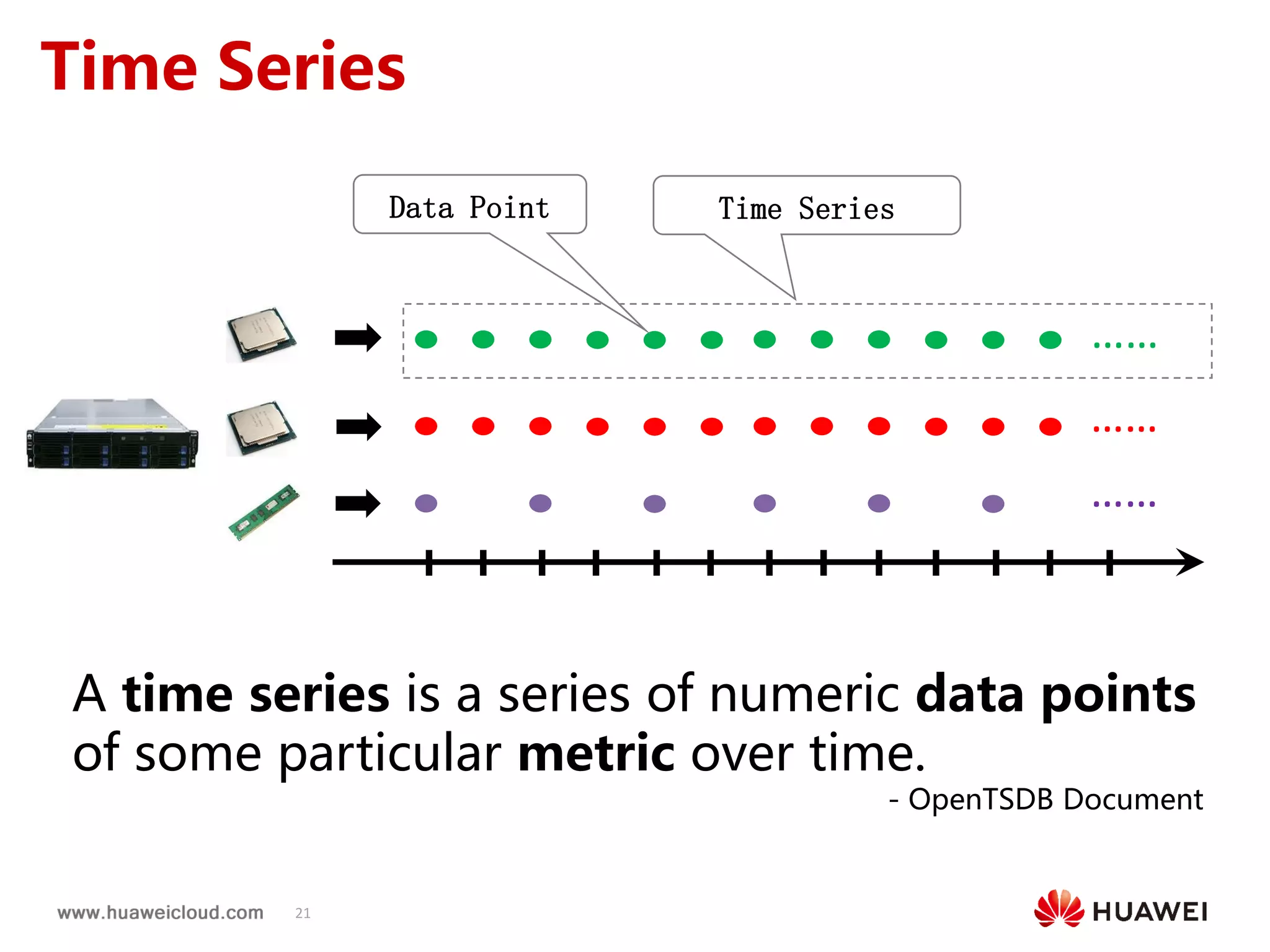
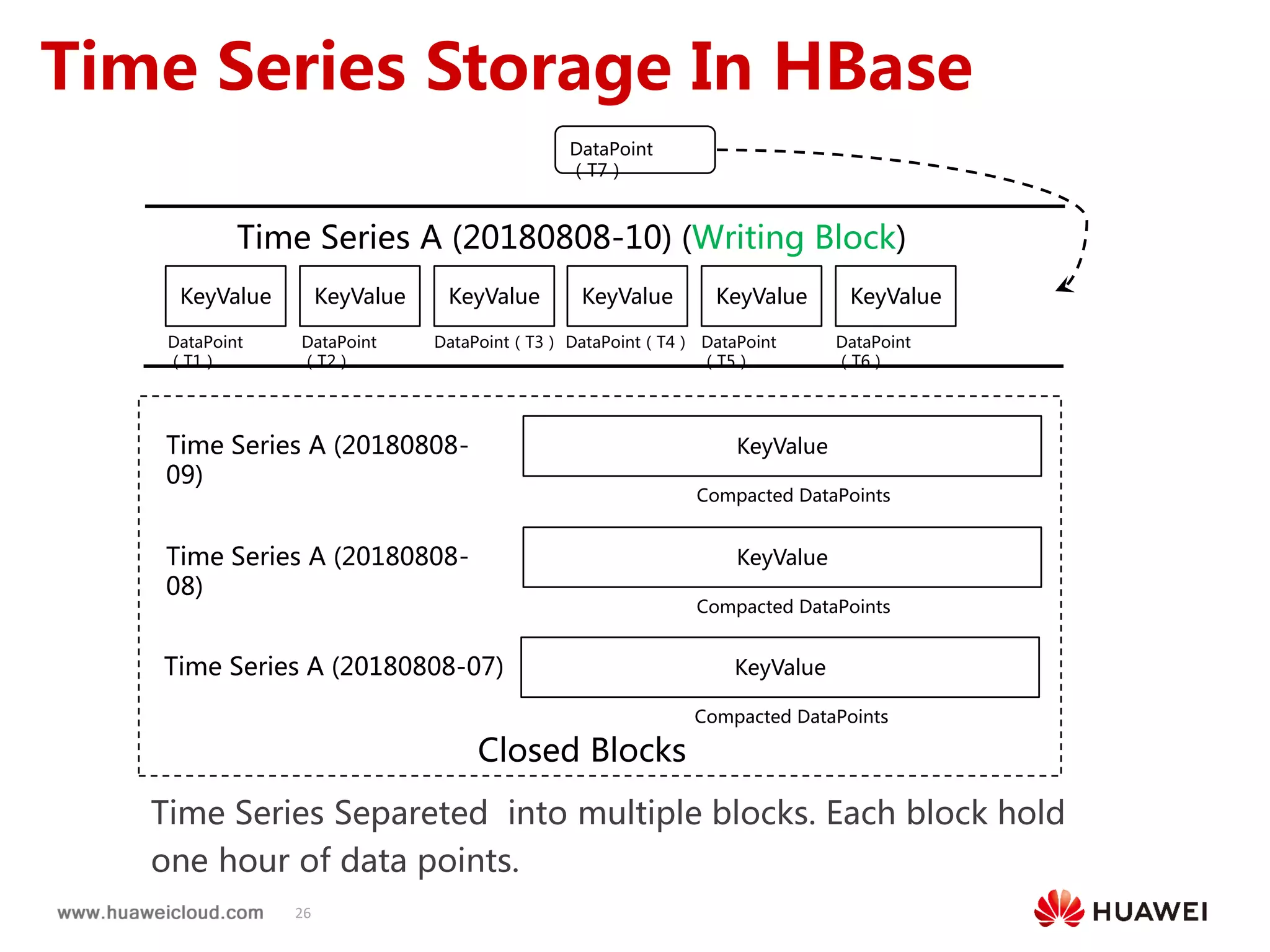
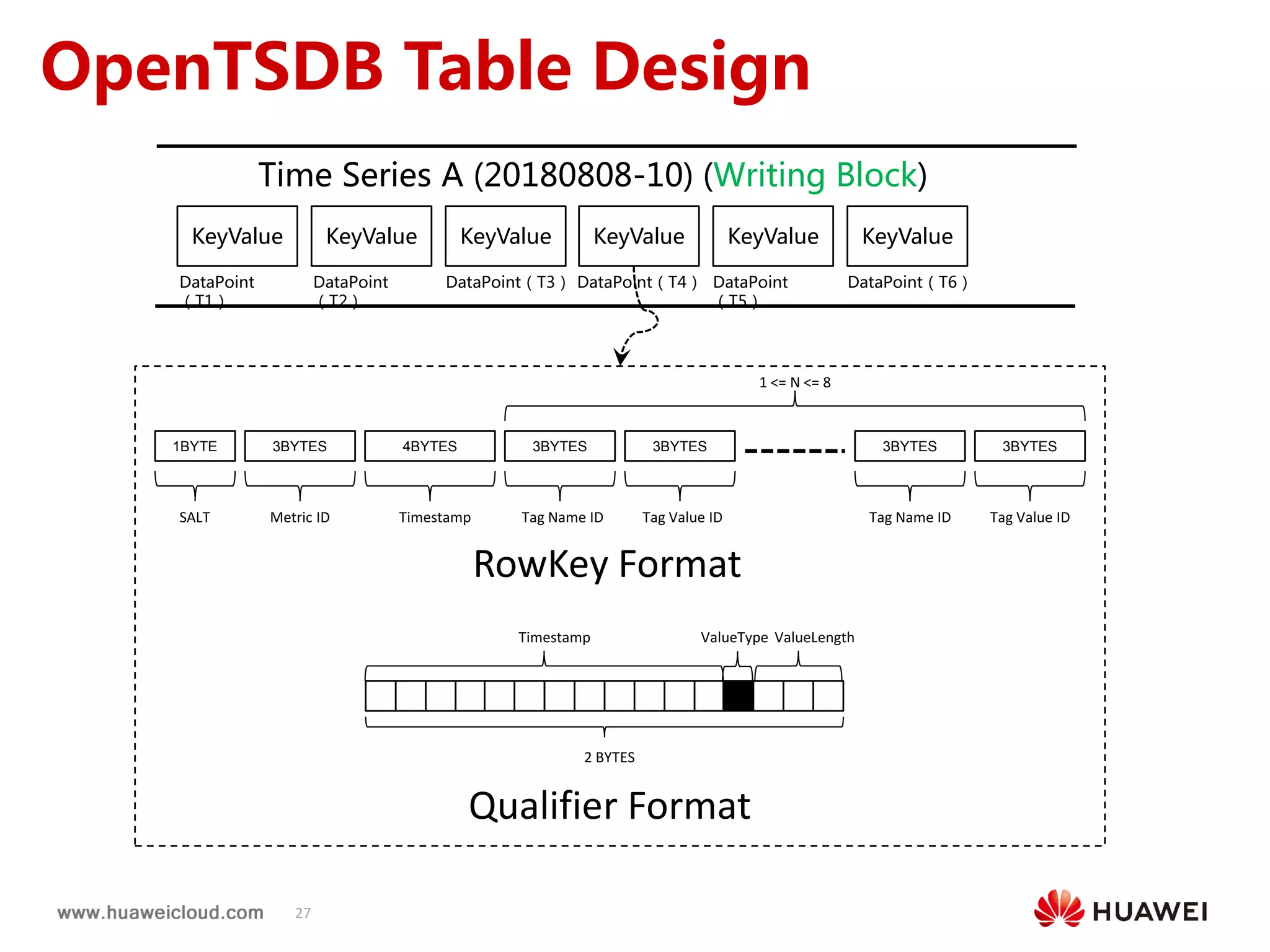
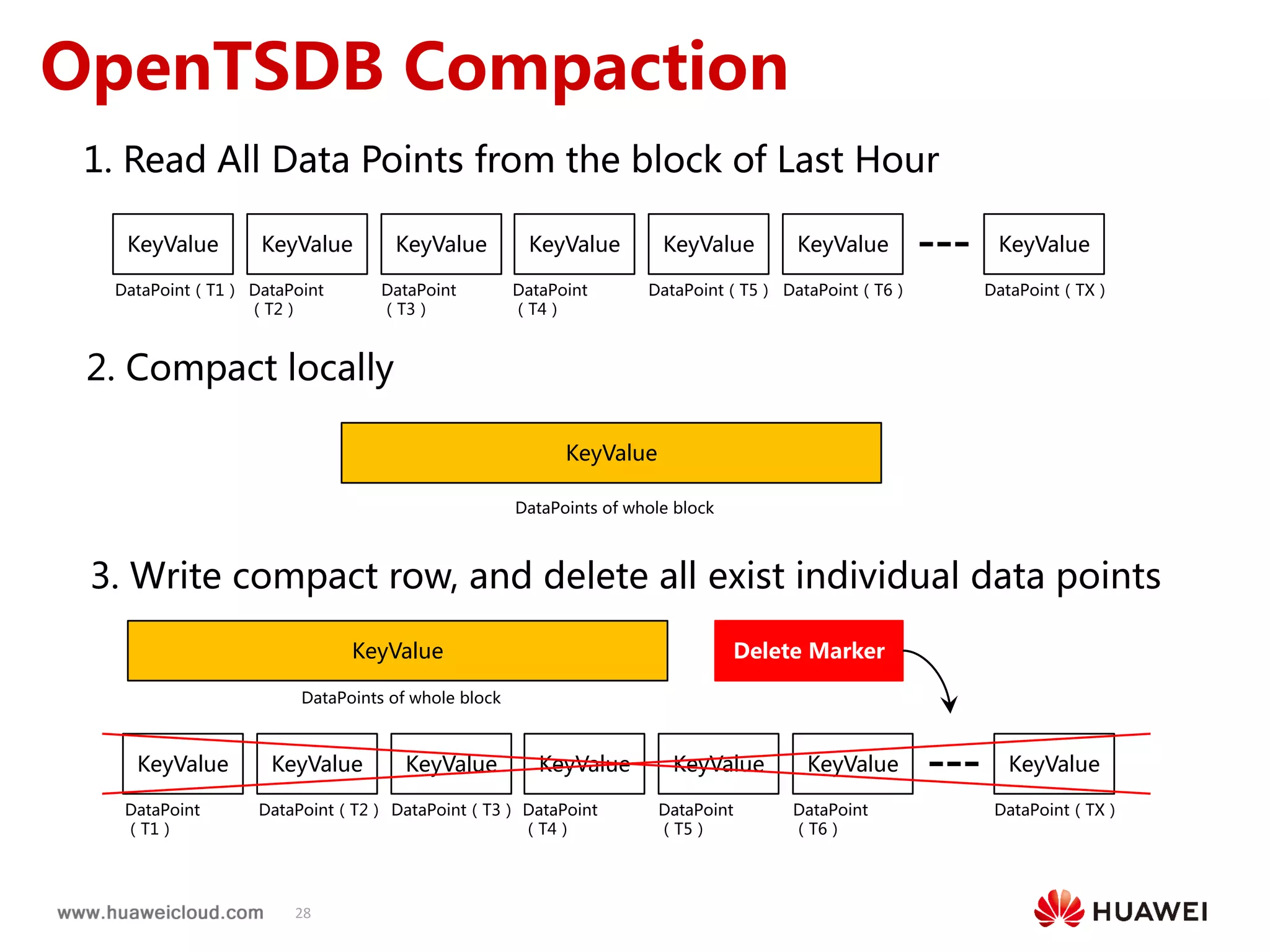
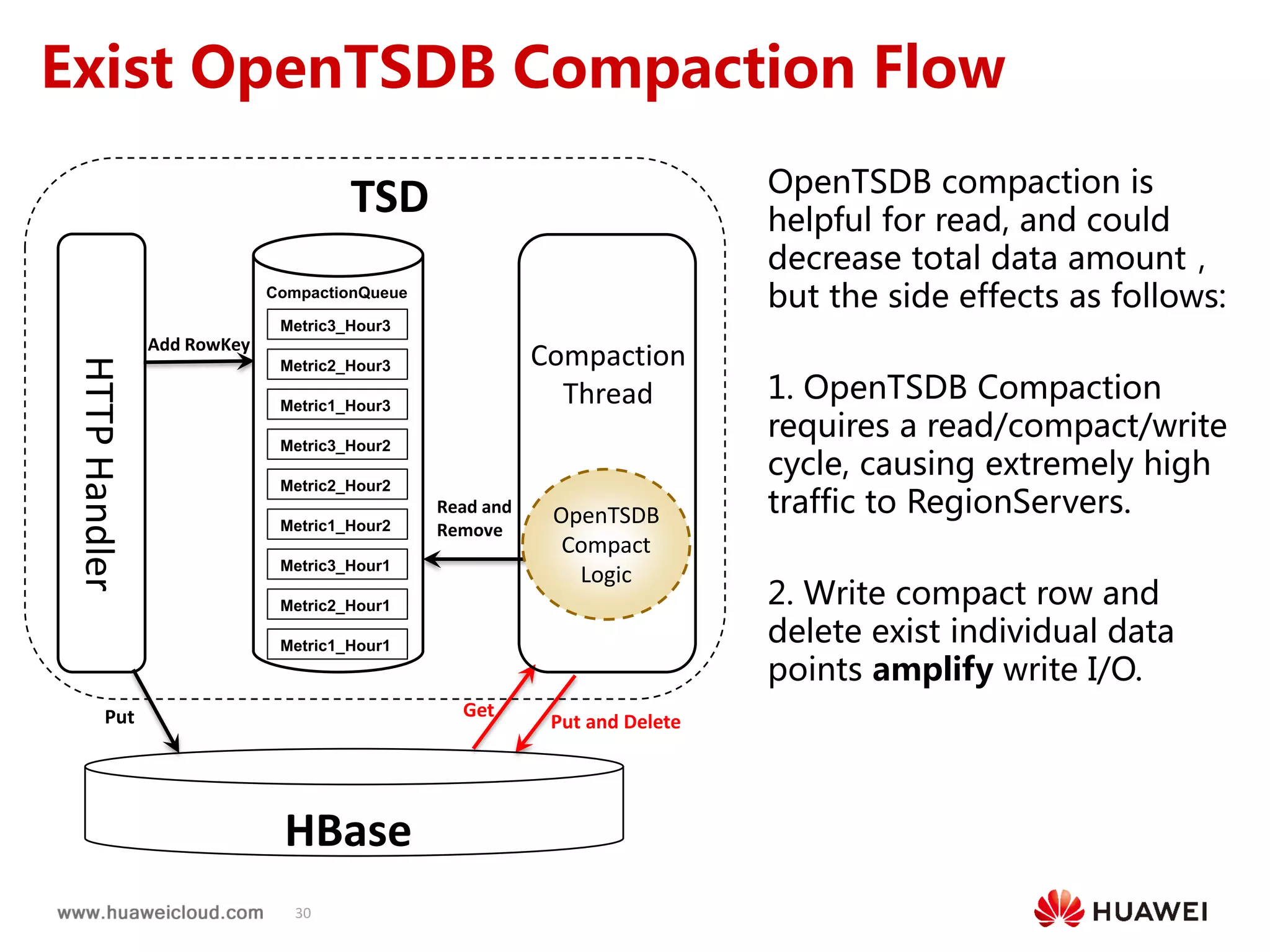
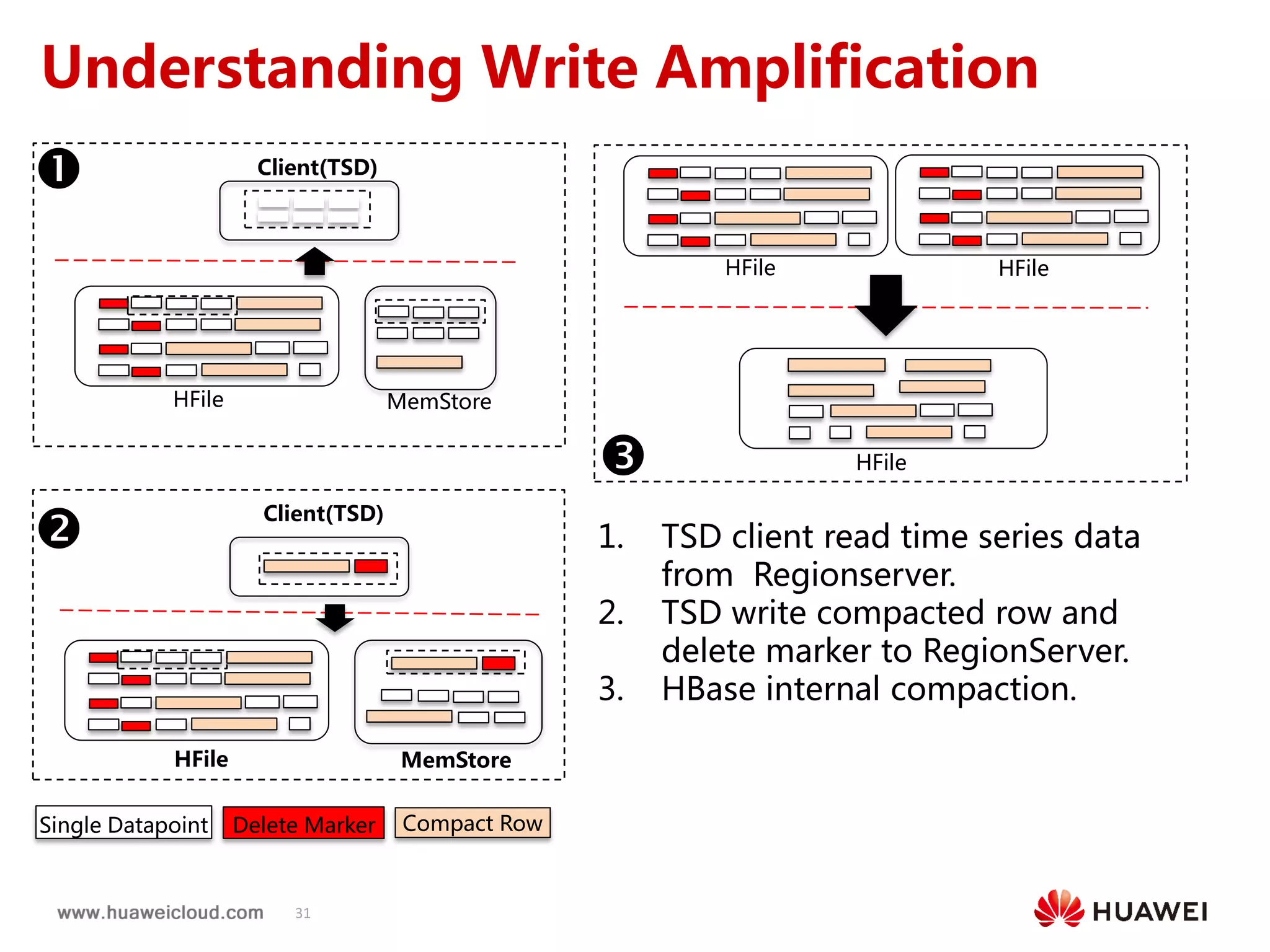
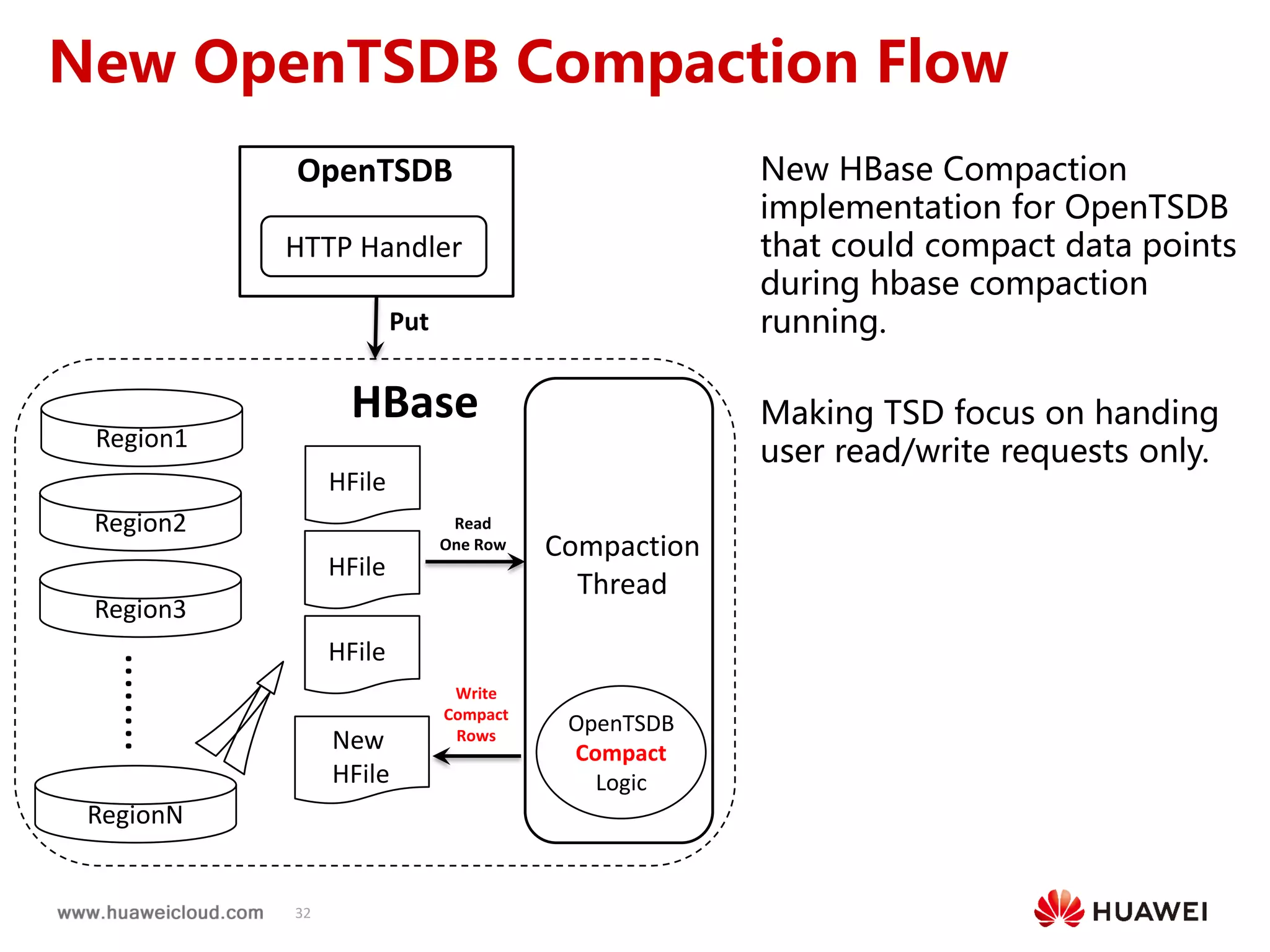
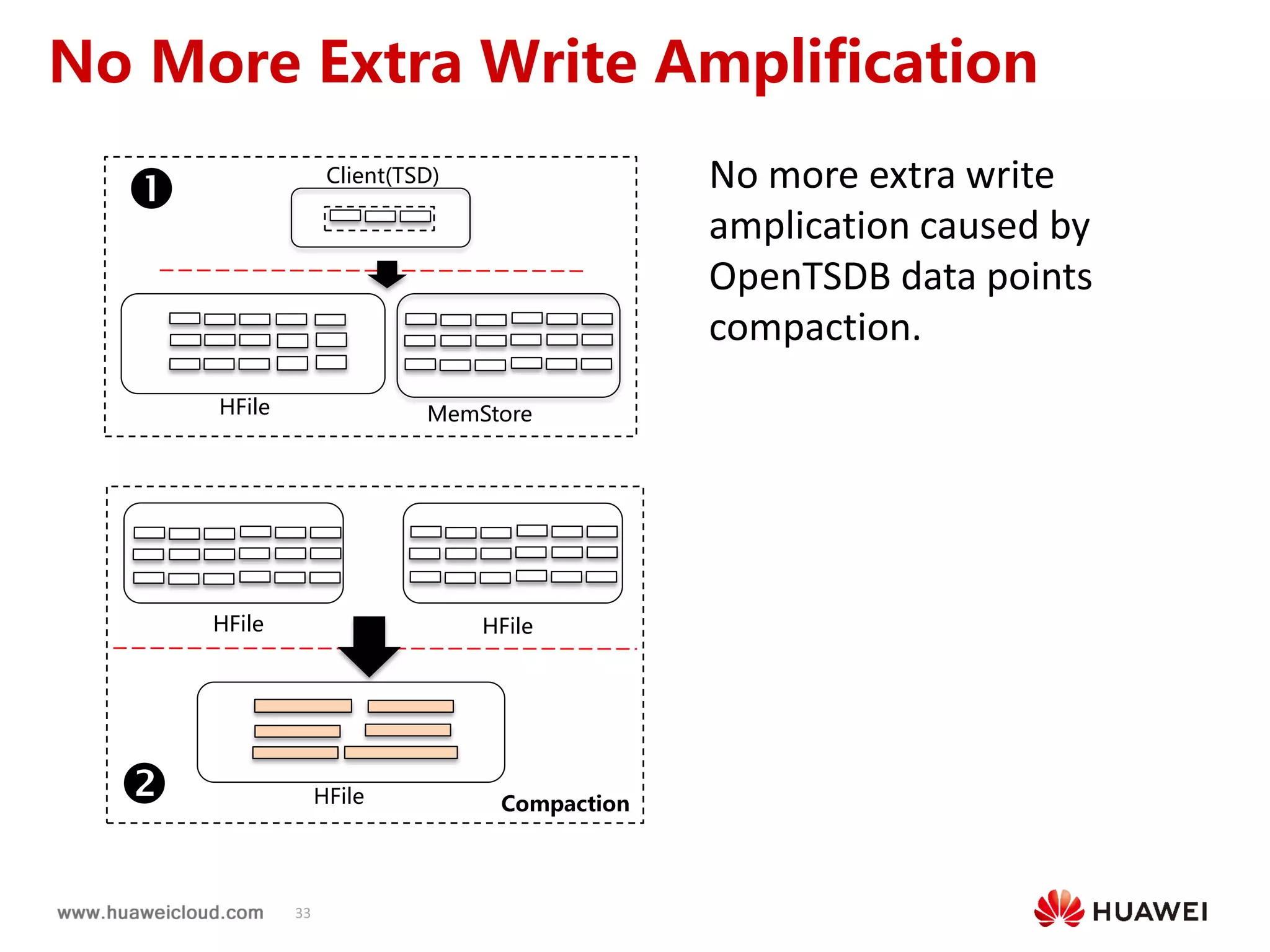
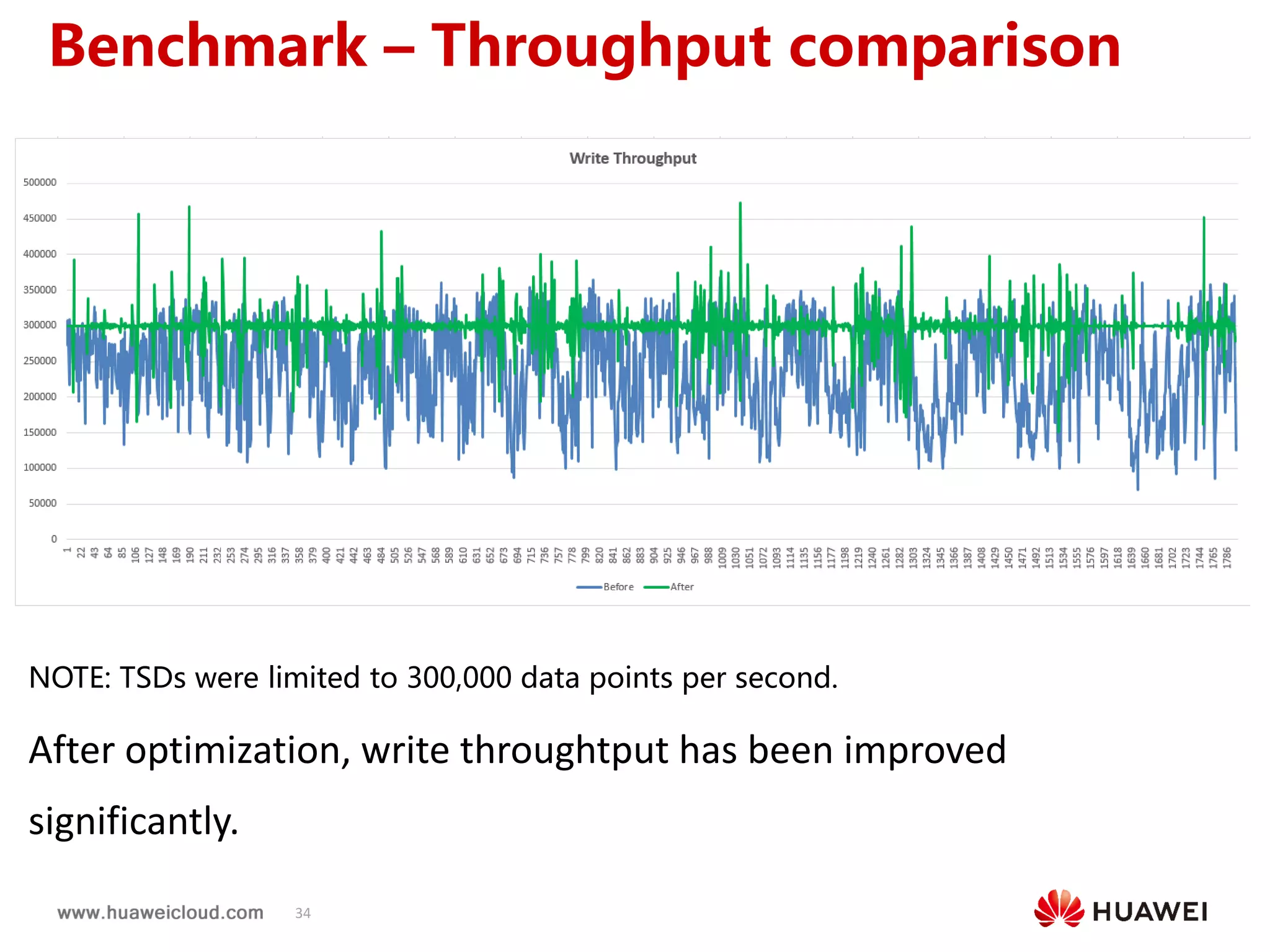
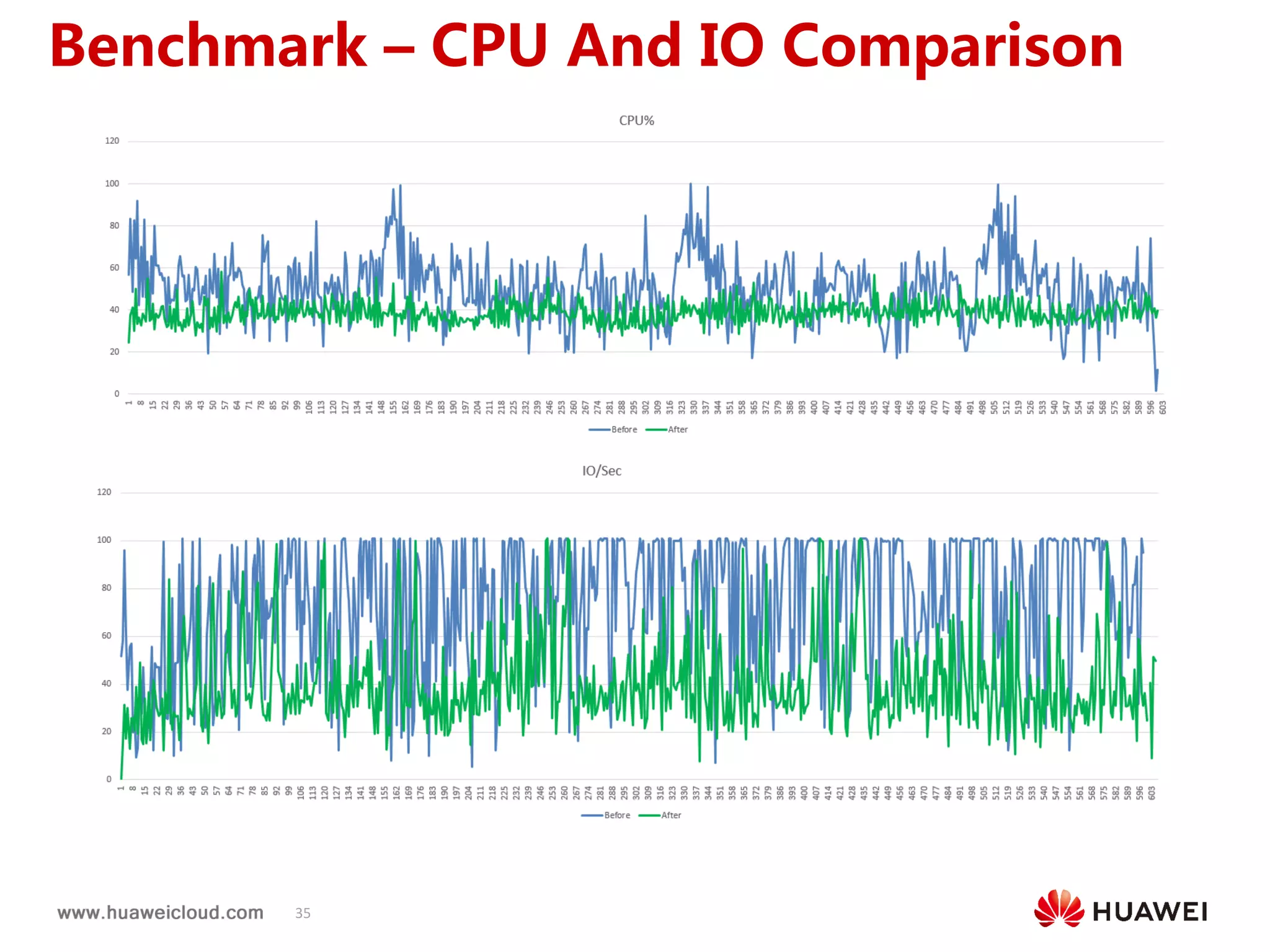
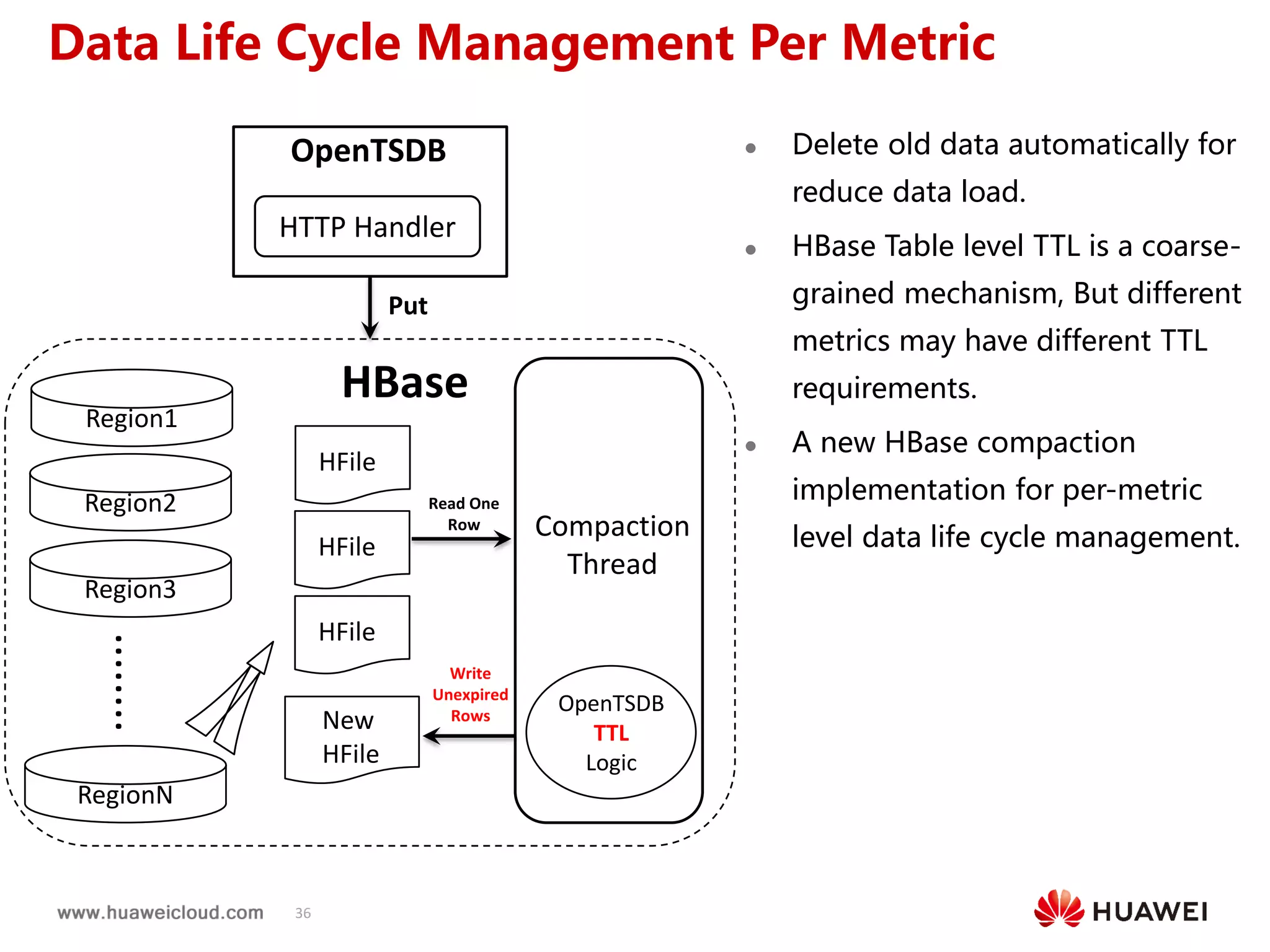
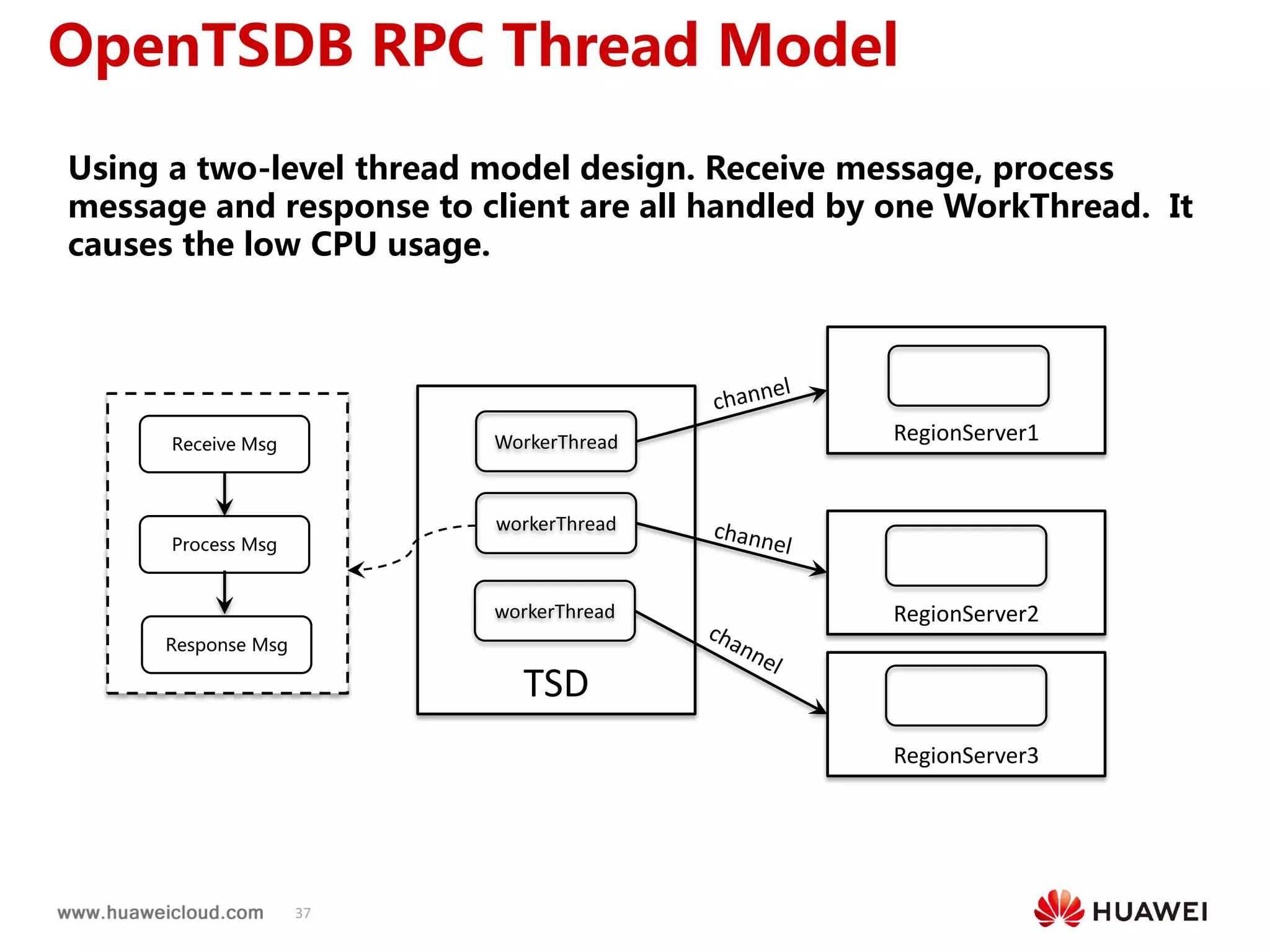
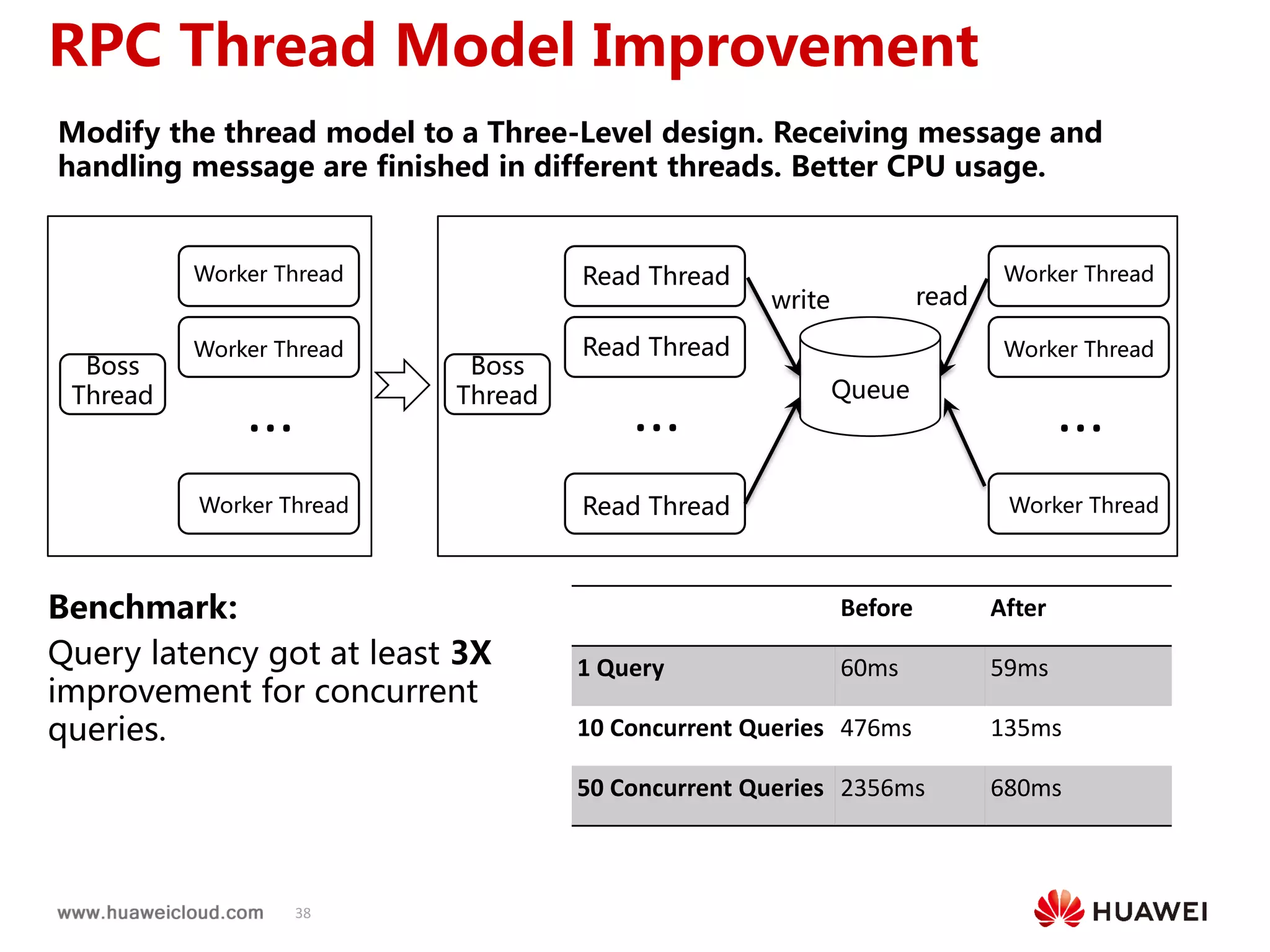
2) OpenTSDB practices such as improving compaction by integrating it with HBase internal compaction to avoid extra write amplification, and adding per-metric data lifecycle management and a two-level thread model for improved performance. Benchmark results show significant improvements in throughput, CPU usage, and query latency.

































































































![Computer Networks 01[1 using all terms].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computernetworks011-251214040533-327dd9f8-thumbnail.jpg?width=640&height=640&fit=bounds)











