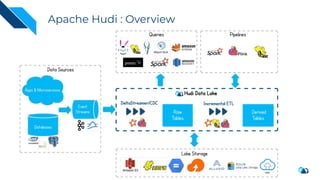
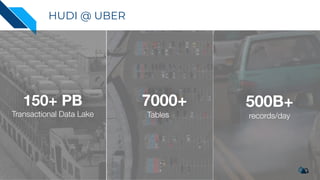
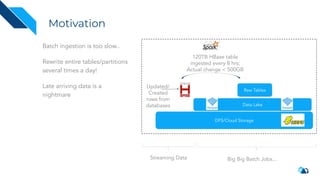
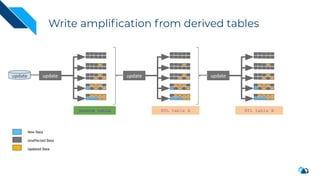
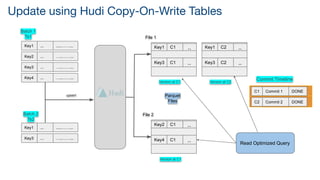
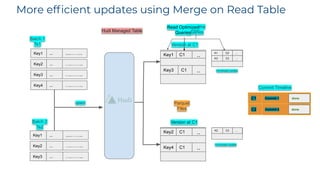
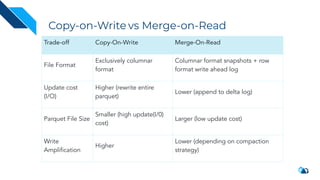
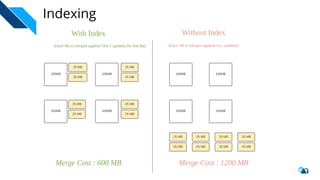
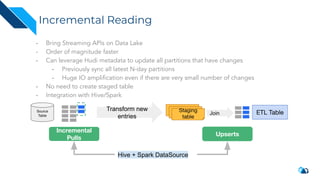
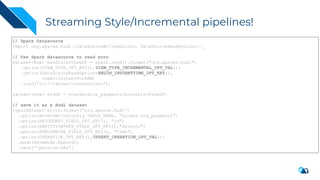
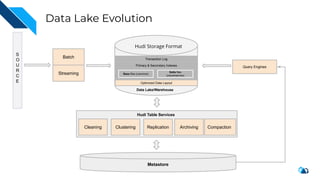
The document discusses the implementation of a large-scale transactional data lake using Apache Hudi, focusing on its capabilities for data consistency, efficient updates, and real-time processing. It highlights key features such as time travel queries, incremental processing, and the management of data ingestion and query efficiency. Additionally, the document outlines various use cases and challenges while showcasing Hudi's architecture and operational processes in managing vast datasets effectively.















![On-Going Work
➔ Concurrent Writers [RFC-22] & [PR-2374]
◆ Multiple Writers to Hudi tables with file level concurrency control
➔ Hudi Observability [RFC-23]
◆ Collect metrics such as Physical vs Logical, Users, Stage Skews
◆ Use to feedback jobs for auto-tuning
➔ Point index [RFC-08]
◆ Target usage for primary key indexes, eg. B+ Tree
➔ ORC support [RFC]
◆ Support for ORC file format
➔ Range Index [RFC-15]
◆ Target usage for column ranges and pruning files/row groups (secondary/column indexes)
➔ Enhance Hudi on Flink [RFC-24]
◆ Full feature support for Hudi on Flink version 1.11+
◆ First class support for Flink
➔ Spark-SQL extensions [RFC-25]
◆ DML/DDL operations such as create, insert, merge etc
◆ Spark DatasourceV2 (Spark 3+)](https://image.slidesharecdn.com/buildinglargescaletransactionaldatalakeusingapachehudi-210430181618/85/Building-large-scale-transactional-data-lake-using-apache-hudi-29-320.jpg)



































![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)













































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








