Downloaded 76 times










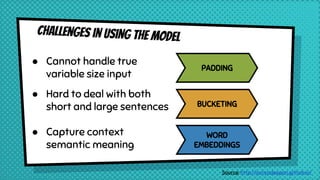
![padding
Source: http://suriyadeepan.github.io/
EOS : End of sentence
PAD : Filler
GO : Start decoding
UNK : Unknown; word not in vocabulary
Q : "What time is it? "
A : "It is seven thirty."
Q : [ PAD, PAD, PAD, PAD, PAD, “?”, “it”,“is”, “time”, “What” ]
A : [ GO, “It”, “is”, “seven”, “thirty”, “.”, EOS, PAD, PAD, PAD ]](https://image.slidesharecdn.com/seq2seqfinalroberto-170201172152/85/Sequence-to-sequence-encoder-decoder-learning-27-320.jpg)
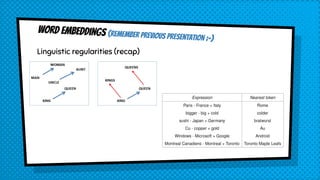
![Source: https://www.tensorflow.org/
bucketing
Efficiently handle sentences of different lengths
Ex: 100 tokens is the largest sentence in corpus
How about short sentences like: "How are you?" → lots of PAD
Bucket list: [(5, 10), (10, 15), (20, 25), (40, 50)]
(defaut on Tensorflow translate.py)
Q : [ PAD, PAD, “.”, “go”,“I”]
A : [GO "Je" "vais" "." EOS PAD PAD PAD PAD PAD]](https://image.slidesharecdn.com/seq2seqfinalroberto-170201172152/85/Sequence-to-sequence-encoder-decoder-learning-28-320.jpg)















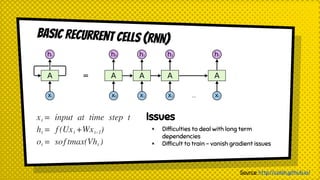
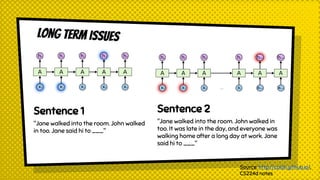
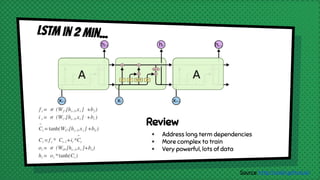
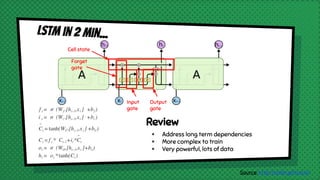
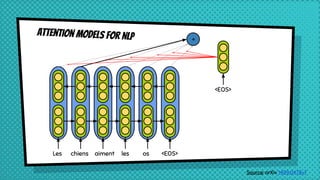
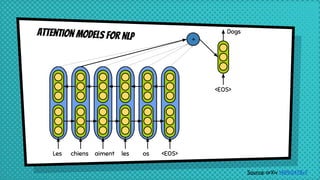
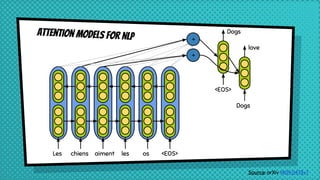
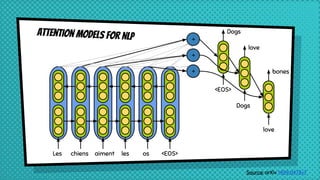
The document discusses various neural network models, including RNNs, LSTMs, and GRUs, focusing on their capabilities to handle sequence-to-sequence tasks. It highlights challenges in long-term dependencies and variable input sizes while outlining the use of attention mechanisms in machine translation and encoder-decoder architectures. Additionally, it explores applications like chatbots and image captioning, and suggests future directions for sequence-to-sequence learning.






































![[246]QANet: Towards Efficient and Human-Level Reading Comprehension on SQuAD](https://cdn.slidesharecdn.com/ss_thumbnails/246qanetdeview2018-181012000849-thumbnail.jpg?width=640&height=640&fit=bounds)




































