Downloaded 14 times









![Word Tokenization!
Splitting a sentence into single words
>>> from nltk.tokenize import word_tokenize
!
>>> word_tokenize("All your base are belong to us")
['All', 'your', 'base', 'are', 'belong', 'to', 'us']](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-15-320.jpg)
![Sentence Tokenization!
Splitting a text into sentences
>>> from nltk.tokenize import sent_tokenize
!
>>> sent_tokenize("Hello, Mr. Anderson. We missed you!")
['Hello, Mr. Anderson.', 'We missed you!']](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-16-320.jpg)

![Stemming!
Finding the word stem or root form
>>> import nltk
>>> porter = nltk.PorterStemmer()
>>> lancaster = nltk.LancasterStemmer()
>>> wnl = nltk.WordNetLemmatizer()
!
>>> [wnl.lemmatize(w) for w in ['investigation','women']]
['investigation', ‘woman']
!
>>> [porter.stem(w) for w in ['investigation','women']]
['investig', 'women']
!
>>> [lancaster.stem(w) for w in ['investigation','women']]
['investig', 'wom']](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-18-320.jpg)
![Part-of-Speech Tagging!
Identifying nouns, verbs, adjectives…
>>> import nltk
>>> text = "In the middle ages Sweden had the
same king as Denmark and Norway."
>>> words = nltk.word_tokenize( text )
!
>>> nltk.pos_tag( words )
[('In', 'IN'), ('the', 'DT'), ('middle', 'NN'),
('ages', 'NNS'), ('Sweden', 'NNP'), ('had', 'VBD'),
('the', 'DT'), ('same', 'JJ'), ('king', 'NN'), ('as',
'IN'), ('Denmark', 'NNP'), ('and', 'CC'), ('Norway',
'NNP'), ('.', '.')]
NN* Noun
VB* Verb
JJ* Adjective
RB* Adverb
DT Determiner
IN Preposition](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-19-320.jpg)
![Named Entity Recognition!
Identifying people, organizations, locations…
>>> import nltk
>>> text = "New York City is the largest city in the
United States."
>>> words = nltk.word_tokenize( text )
!
>>> nltk.ne_chunk( nltk.pos_tag( words ) )
Tree('S', [Tree('GPE', [('New', 'NNP'), ('York', 'NNP'),
('City', 'NNP')]), ('is', 'VBZ'), ('the', 'DT'),
('largest', 'JJS'), ('city', 'NN'), ('in', 'IN'), ('the',
'DT'), Tree('GPE', [('United', 'NNP'), ('States',
'NNPS')]), ('.', '.')])
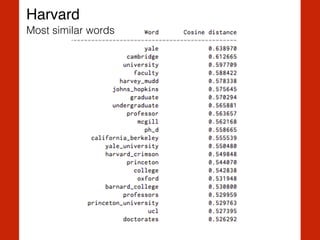
ORGANIZATION Georgia-Pacific Corp., WHO
PERSON Eddy Bonte, President Obama
LOCATION Murray River, Mount Everest
DATE June, 2008-06-29
TIME two fifty a m, 1:30 p.m.
MONEY GBP 10.40
PERCENT twenty pct, 18.75 %
FACILITY Washington Monument, Stonehenge
GPE South East Asia, Midlothian
(geo-political entity)](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-20-320.jpg)



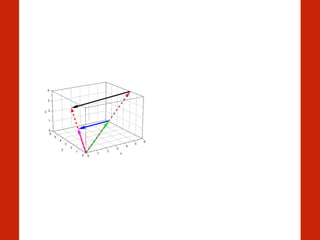
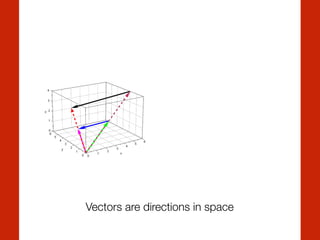
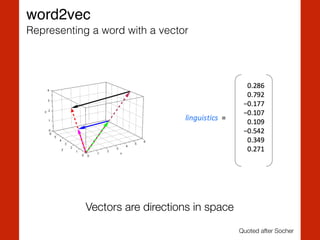
![T. Mikolov, K. Chen, G. Corrado, and J. Dean, ‘Efficient Estimation of Word
Representations in Vector Space’, CoRR, vol. abs/1301.3781, 2013 [Online].
Available: http://arxiv.org/abs/1301.3781
Vectors can encode relationships
MAN
WOMAN
AUNT
UNCLE
QUEEN
KING
word2vec
Representing a word with a vector](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-29-320.jpg)
![T. Mikolov, K. Chen, G. Corrado, and J. Dean, ‘Efficient Estimation of Word
Representations in Vector Space’, CoRR, vol. abs/1301.3781, 2013 [Online].
Available: http://arxiv.org/abs/1301.3781
man is to woman as king is to ?
KINGS
KING
QUEEN
QUEENS
word2vec
Representing a word with a vector](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-30-320.jpg)
![T. Mikolov, K. Chen, G. Corrado, and J. Dean, ‘Efficient Estimation of Word
Representations in Vector Space’, CoRR, vol. abs/1301.3781, 2013 [Online].
Available: http://arxiv.org/abs/1301.3781
word2vec
Representing a word with a vector](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-31-320.jpg)




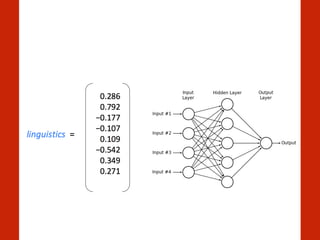











![Machine Translation
T. Mikolov, Q. V. Le, and I. Sutskever, ‘Exploiting Similarities among Languages
for Machine Translation’, CoRR, vol. abs/1309.4168, 2013 [Online]. Available:
http://arxiv.org/abs/1309.4168](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-50-320.jpg)

![{ "event":[
{"query":
{"id":[
{"timestamp_usec":"1317002730153183"}
],
"query_text":"google hangout"
}
},
{"query":
{"id":[
{"timestamp_usec":"1316577601549660"}
],
"query_text":"eurokrise"
}
},
{"query":
{"id":[
{"timestamp_usec":"1315592145720230"}
],
"query_text":"hoverboard"
}
}
parsed_json[‘event’][42]['query']['query_text']](https://image.slidesharecdn.com/heuerhackinghumanlanguagepycon-150526141914-lva1-app6892/85/Hacking-Human-Language-PyCon-Sweden-2015-53-320.jpg)






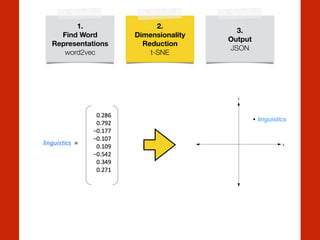










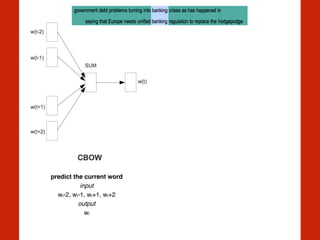
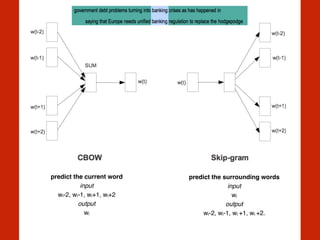


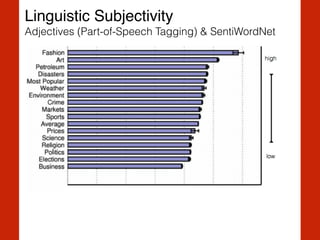
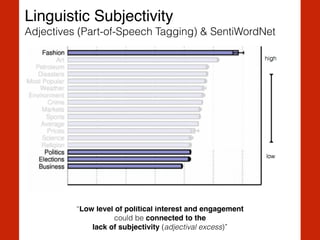
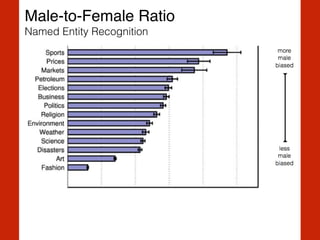
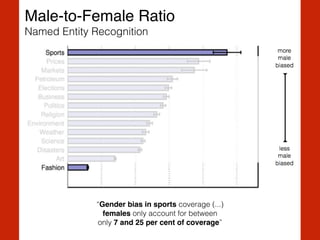
The document discusses the intersection of computational social science and natural language processing, emphasizing the application of various techniques like word vector representations, sentiment analysis, and machine translation. It highlights numerous studies analyzing digital texts and news content to reveal patterns in readability, gender bias, and linguistic subjectivity. Additionally, it provides practical examples of natural language processing methods, including tokenization, stemming, and named entity recognition.
























































