This document summarizes and explains the GloVe model for generating word embeddings. GloVe aims to capture word meaning in vector space while taking advantage of global word co-occurrence counts. Unlike word2vec, GloVe learns embeddings based on a co-occurrence matrix rather than streaming sentences. It trains vectors so their differences predict co-occurrence ratios. The document outlines the key steps in building GloVe, including data preparation, defining the prediction task, deriving the GloVe equation, and comparisons to word2vec.























![[우리가 데이터를 쓰는 법] 좋다는 건 알겠는데 좀 써보고 싶소. 데이터! - 넘버웍스 하용호 대표](https://cdn.slidesharecdn.com/ss_thumbnails/3-160416163055-thumbnail.jpg?width=640&height=640&fit=bounds)















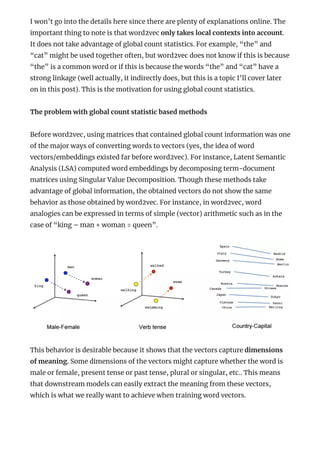
![[Emnlp] what is glo ve part i - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisgloveparti-towardsdatascience-200228052054-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Emnlp] what is glo ve part ii - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisglovepartii-towardsdatascience-200228052050-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Emnlp] what is glo ve part iii - towards data science](https://cdn.slidesharecdn.com/ss_thumbnails/emnlpwhatisglovepartiii-towardsdatascience-200228052047-thumbnail.jpg?width=640&height=640&fit=bounds)




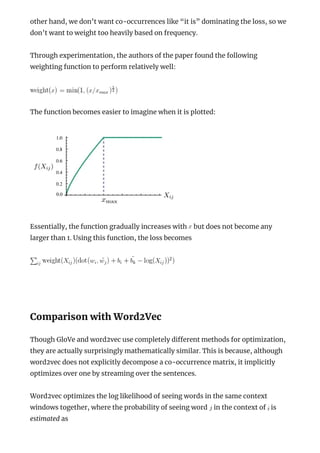
![[DSC Europe 25] Marcos Heidemann - Beyond the Hype: Making AI Coding Assistan...](https://cdn.slidesharecdn.com/ss_thumbnails/eexkhvldrjsopspdjbur-marcos-heidemann-beyond-the-hype-getting-real-value-out-of-ai-assisted-coding-260121115910-7e9d41ec-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)


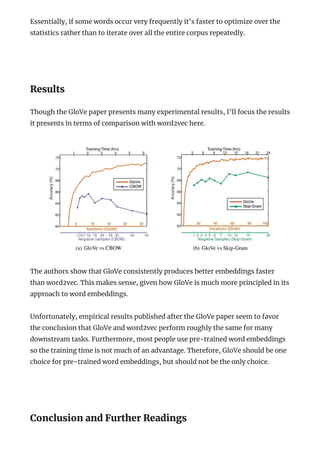
![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Harshvardhan Jain - From Pre-Trained to Purpose-Built: Fine-T...](https://cdn.slidesharecdn.com/ss_thumbnails/zru4zmiseku5tgvu2dgw-harshvardhan-jain-from-pre-trained-to-purpose-built-fine-tuning-llms-for-high-i-260119101520-8335585f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dubravko Culibrk - Deep Learning for Mammography.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/yiscimuktacgqoiu4dkp-deep-learning-for-mammography-260119121559-aad59182-thumbnail.jpg?width=640&height=640&fit=bounds)


