Download as PDF, PPTX



















![for step in range(20): # <-- this is way way way too simple to work in
"reality(tm)"
#-- RESET ACCUMULATORS ------------------------------------------------------
padn = [[0] * aspects for j in range(docs )]
pawn = [[0] * aspects for j in range(words)]
pan = [0] * aspects
#-- PROCESS ALL DOCUMENTS ---------------------------------------------------
for docId in range(docs):
#-- ITERATE OVER ALL WORDS ------------------------------------------------
for wordId in range(words):
#-- E-STEP (THIS CAN BE DONE MUCH MORE EFFICIENT) ----------------------
pzdw = [pad[docId][a] * paw[wordId][a] / pa[a] for a in range(aspects)]
norm(pzdw)
scale(pzdw, arrDoc[docId][wordId])
#-- M-STEP --------------------------------------------------------------
add(padn[docId ], pzdw)
add(pawn[wordId], pzdw)
add(pan , pzdw)
#-- SAVE ACCUMULATORS -------------------------------------------------------
pad = padn
paw = pawn
pa = pan QAware 28
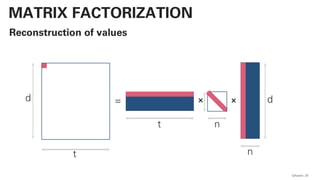
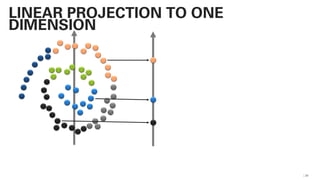
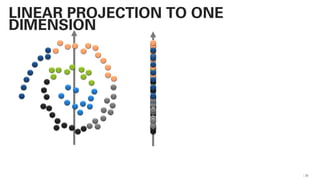
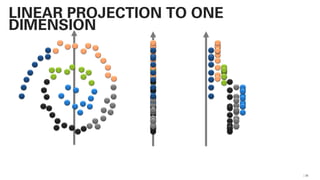
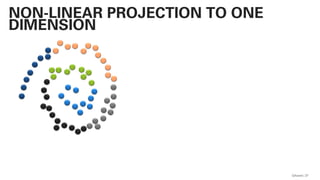
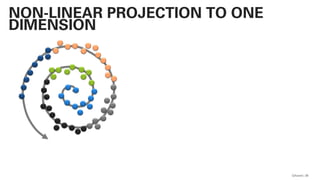
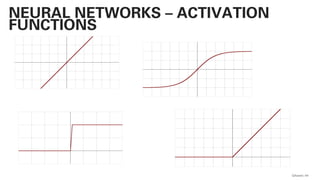
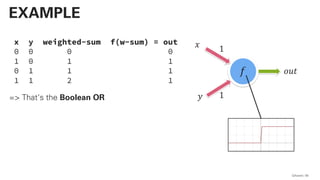
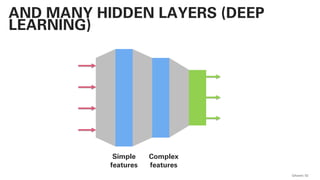
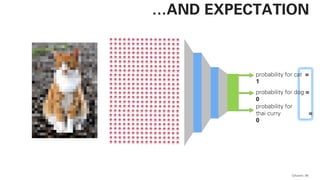
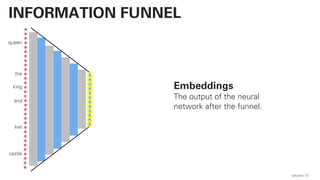
PLSA - PROBABILISTIC LATENT SEMANTIC
ANALYSIS
This actually works and
is not very far away from
a practical
implementation!](https://image.slidesharecdn.com/qaware-joerg-viechtbauer-from-grep-to-bert-201211123538/85/From-grep-to-BERT-28-320.jpg)




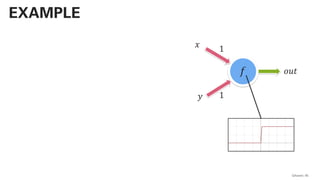
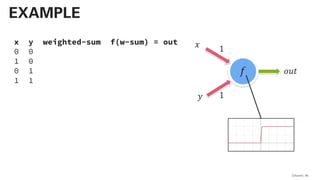
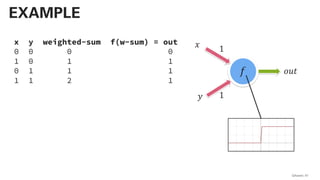
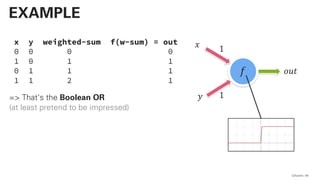
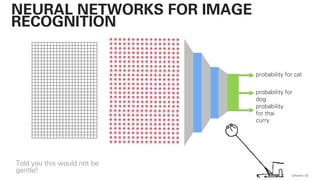
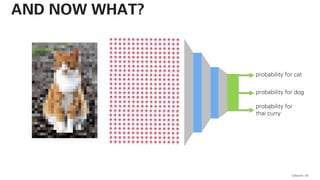
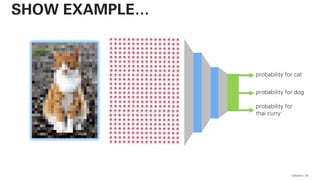
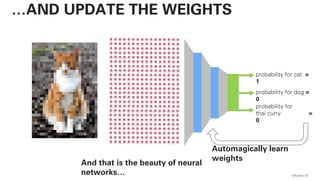








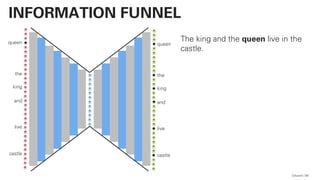
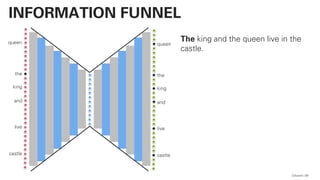
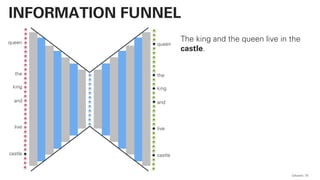
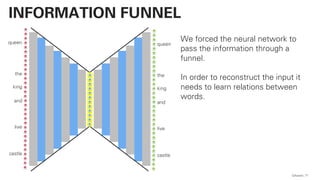




![!pip install -U sentence-transformers
!pip install scipy
import scipy
from sentence_transformers import SentenceTransformer
sentences = ["the sun shines",
"the sky is blue",
"we have good weather",
"bert is amazing",
"sentence embeddings rock",
"it is raining",
"uhh i need a rain coat",
"that's pretty bad weather"]
model = SentenceTransformer("roberta-large-nli-mean-tokens")
sentence_embeddings = model.encode(sentences)
distances = scipy.spatial.distance.cdist(sentence_embeddings, sentence_embeddings,
"cosine")
print(distances)
QAware 78
BERT – CODE](https://image.slidesharecdn.com/qaware-joerg-viechtbauer-from-grep-to-bert-201211123538/85/From-grep-to-BERT-78-320.jpg)
![!pip install -U sentence-transformers
!pip install scipy
import scipy
from sentence_transformers import SentenceTransformer
sentences = ["the sun shines",
"the sky is blue",
"we have good weather",
"bert is amazing",
"sentence embeddings rock",
"it is raining",
"uhh i need a rain coat",
"that's pretty bad weather"]
model = SentenceTransformer("roberta-large-nli-mean-tokens") # <== plenty to choose
from
sentence_embeddings = model.encode(sentences)
distances = scipy.spatial.distance.cdist(sentence_embeddings, sentence_embeddings,
"cosine")
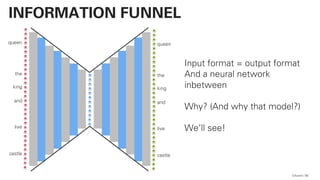
print(distances) QAware 79
BERT – CODE](https://image.slidesharecdn.com/qaware-joerg-viechtbauer-from-grep-to-bert-201211123538/85/From-grep-to-BERT-79-320.jpg)
![!pip install -U sentence-transformers
!pip install scipy
import scipy
from sentence_transformers import SentenceTransformer
sentences = ["the sun shines",
"the sky is blue",
"we have good weather",
"bert is amazing",
"sentence embeddings rock",
"it is raining",
"uhh i need a rain coat",
"that's pretty bad weather"]
model = SentenceTransformer("roberta-large-nli-mean-tokens")
sentence_embeddings = model.encode(sentences)
distances = scipy.spatial.distance.cdist(sentence_embeddings, sentence_embeddings,
"cosine")
print(distances)
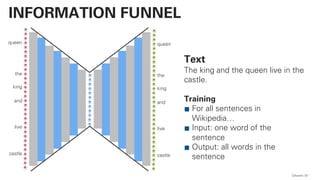
QAware 80
BERT – CODE](https://image.slidesharecdn.com/qaware-joerg-viechtbauer-from-grep-to-bert-201211123538/85/From-grep-to-BERT-80-320.jpg)
![!pip install -U sentence-transformers
!pip install scipy
import scipy
from sentence_transformers import SentenceTransformer
sentences = ["the sun shines",
"the sky is blue",
"we have good weather",
"bert is amazing",
"sentence embeddings rock",
"it is raining",
"uhh i need a rain coat",
"that's pretty bad weather"]
model = SentenceTransformer("roberta-large-nli-mean-tokens")
sentence_embeddings = model.encode(sentences)
distances = scipy.spatial.distance.cdist(sentence_embeddings, sentence_embeddings,
"cosine")
print(distances)
QAware 81
BERT – CODE](https://image.slidesharecdn.com/qaware-joerg-viechtbauer-from-grep-to-bert-201211123538/85/From-grep-to-BERT-81-320.jpg)



The document discusses cloud-native questions, semantic search using vector space models, and the transition from traditional search methods to neural network approaches. It highlights the evolution of search technologies including grep, wget, probabilistic latent semantic analysis, and deep learning techniques. Key concepts include the importance of vector embeddings, matrix factorization, and the neural network's ability to learn weights for improved search quality.









































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




