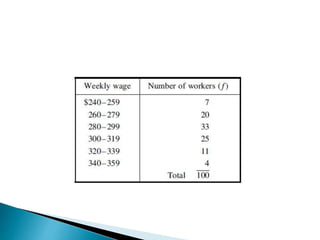
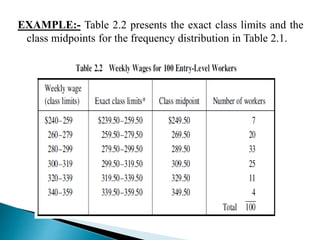
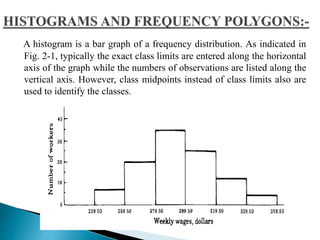
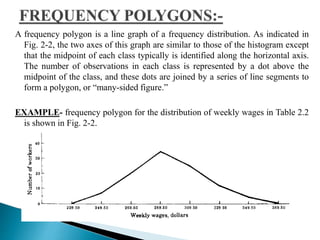
This document discusses statistics and their uses in various fields such as business, health, learning, research, social sciences, and natural resources. It provides examples of how statistics are used in starting businesses, manufacturing, marketing, and engineering. Statistics help decision-makers reduce ambiguity and assess risks. They are used to interpret data and make informed decisions. However, statistics also have limitations as they only show averages and may not apply to individuals.