Downloaded 453 times






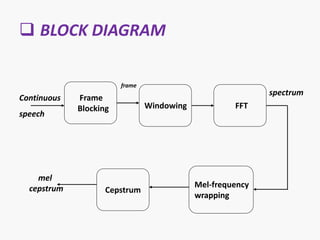
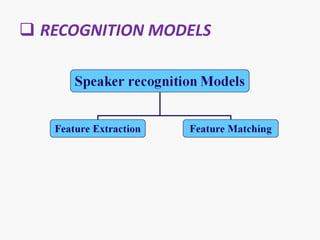


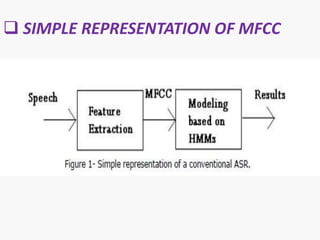
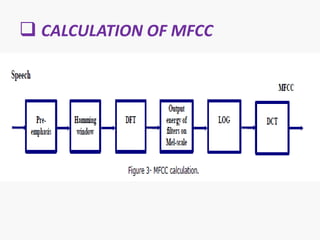
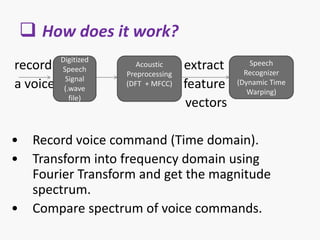







The document discusses voice recognition using MatLab. It introduces voice recognition as the process of converting acoustic signals to words. Voice recognition can be used for transcription, command and control, and information access. It discusses the principles and methods of voice recognition, including text-dependent and text-independent approaches. The document outlines the key components of a voice recognition system, including feature extraction using mel-frequency cepstrum coefficients (MFCC), recognition models, and applications like device control and mobile phones. It also reviews the advantages, limitations, and future of voice recognition technology.


















































































