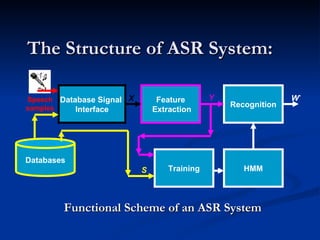
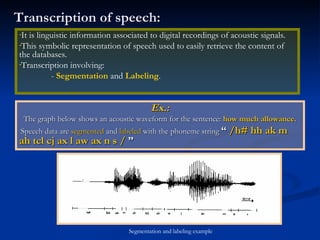
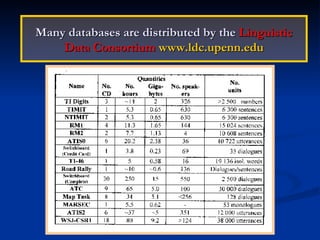
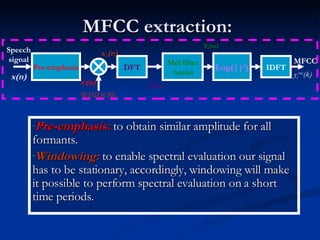
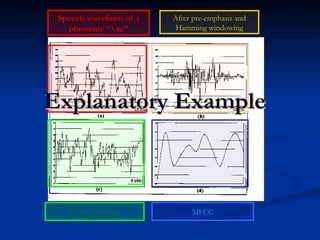
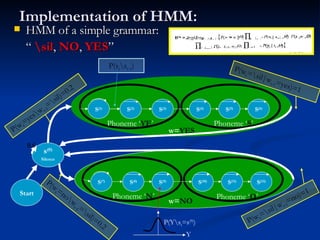
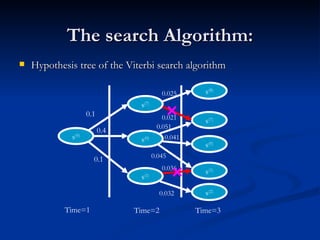
Automatic speech recognition (ASR) systems convert spoken words to text. ASR systems have a speech database for training, extract acoustic features like MFCCs from speech, and use hidden Markov models trained on large datasets to recognize speech in real-time. ASR has applications in dictation, command and control, telephony, and assisting those with disabilities. The timeline of ASR shows steady improvements from isolated word recognition to today's systems that can understand continuous speech.



![Multilayer Structure of speech production: [book_airplane_flight] [from_locality] [to_locality] [ departure_time] [I] [would] [like] [to] [book] [a] [flight] [from] [Rome] [to] [London][tomorrow][morning] [book] [b/uh/k] Pragmatic Layer Semantic Layer Syntactic Layer Prosodic/Phonetic Layer Acoustic Layer](https://image.slidesharecdn.com/asr3202/85/Asr-3-320.jpg)