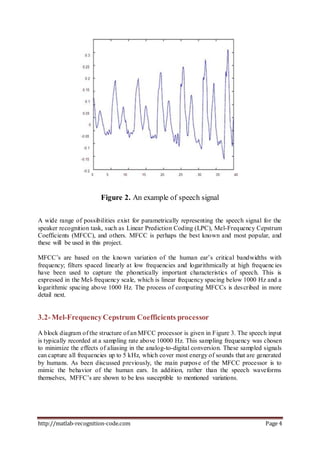
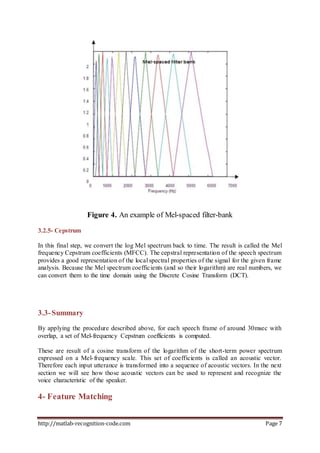
Speaker recognition systems aim to automatically identify or verify a speaker's identity based on characteristics of their voice. There are two main types: speaker identification determines which registered speaker is speaking, while speaker verification accepts or rejects a speaker's claimed identity. All systems contain modules for feature extraction and feature matching. Feature extraction represents the voice signal with parameters like MFCCs that can distinguish speakers. Feature matching compares extracted features from an unknown voice to known speaker models. The document describes the process of MFCC feature extraction in detail, including framing the speech signal, windowing frames, taking the FFT, mapping to the mel scale, and finally the DCT to produce MFCC coefficients.