Downloaded 1,672 times


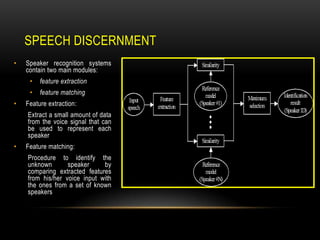

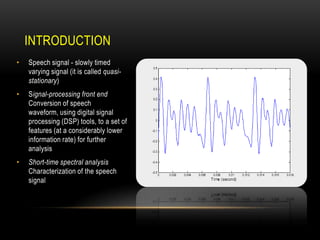



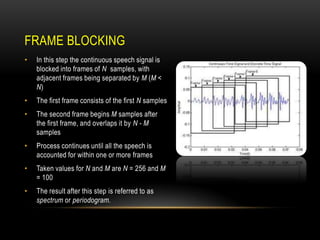
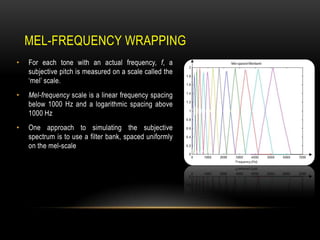
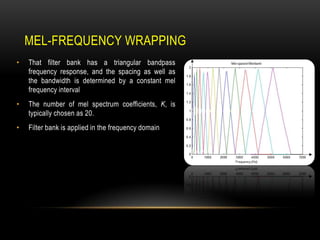



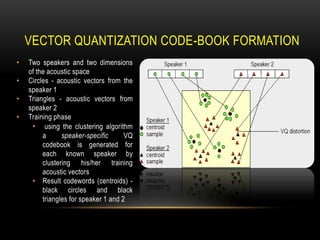
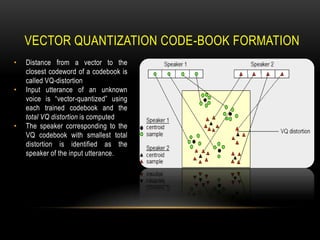
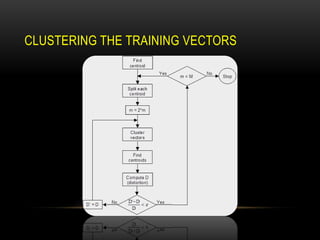



This document discusses speaker recognition using Mel Frequency Cepstral Coefficients (MFCC). It describes the process of feature extraction using MFCC which involves framing the speech signal, taking the Fourier transform of each frame, warping the frequencies using the mel scale, taking the logs of the powers at each mel frequency, and converting to cepstral coefficients. It then discusses feature matching techniques like vector quantization which clusters reference speaker features to create codebooks for comparison to unknown speakers. The document provides references for further reading on speech and speaker recognition techniques.











































































