










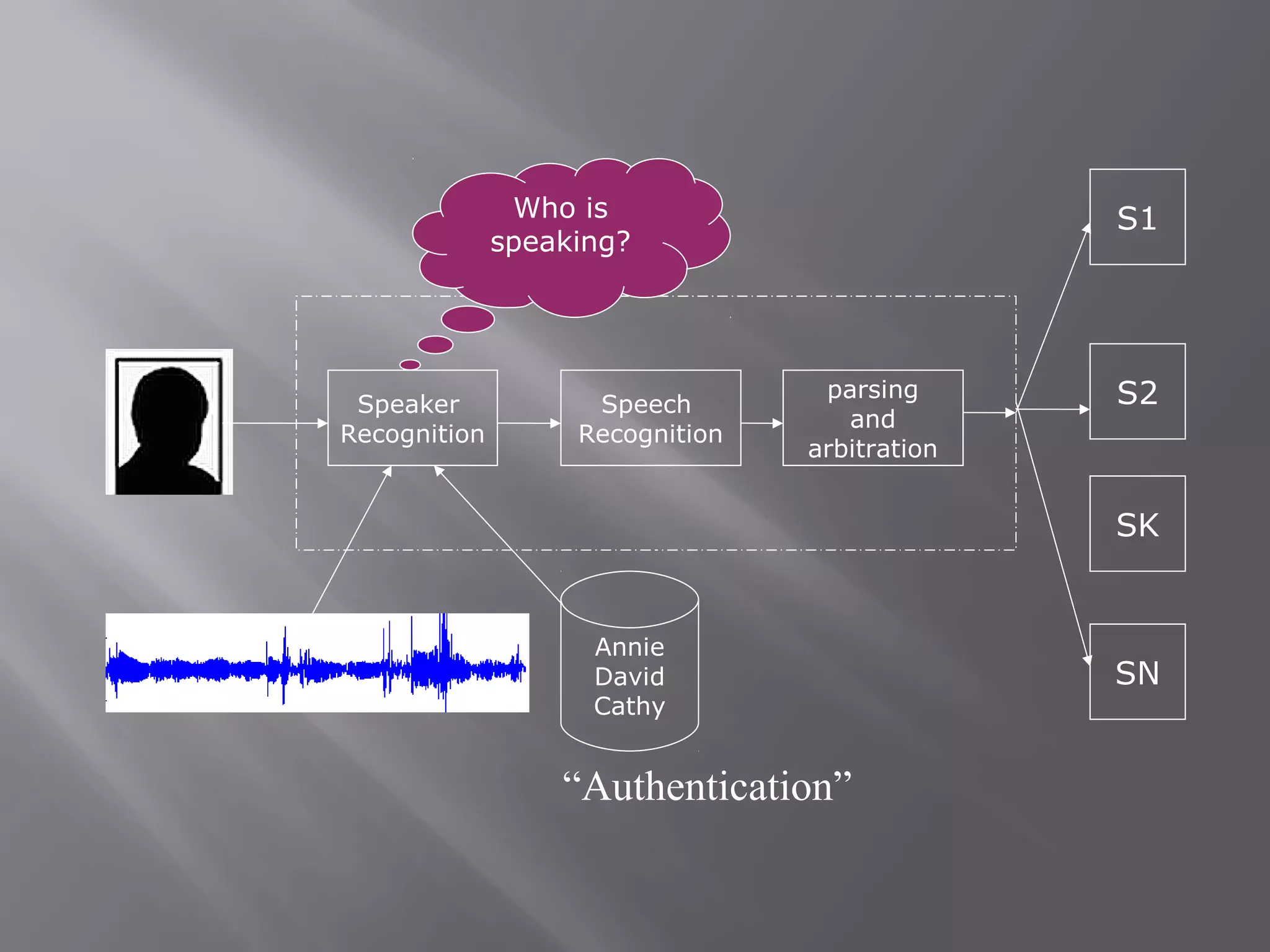
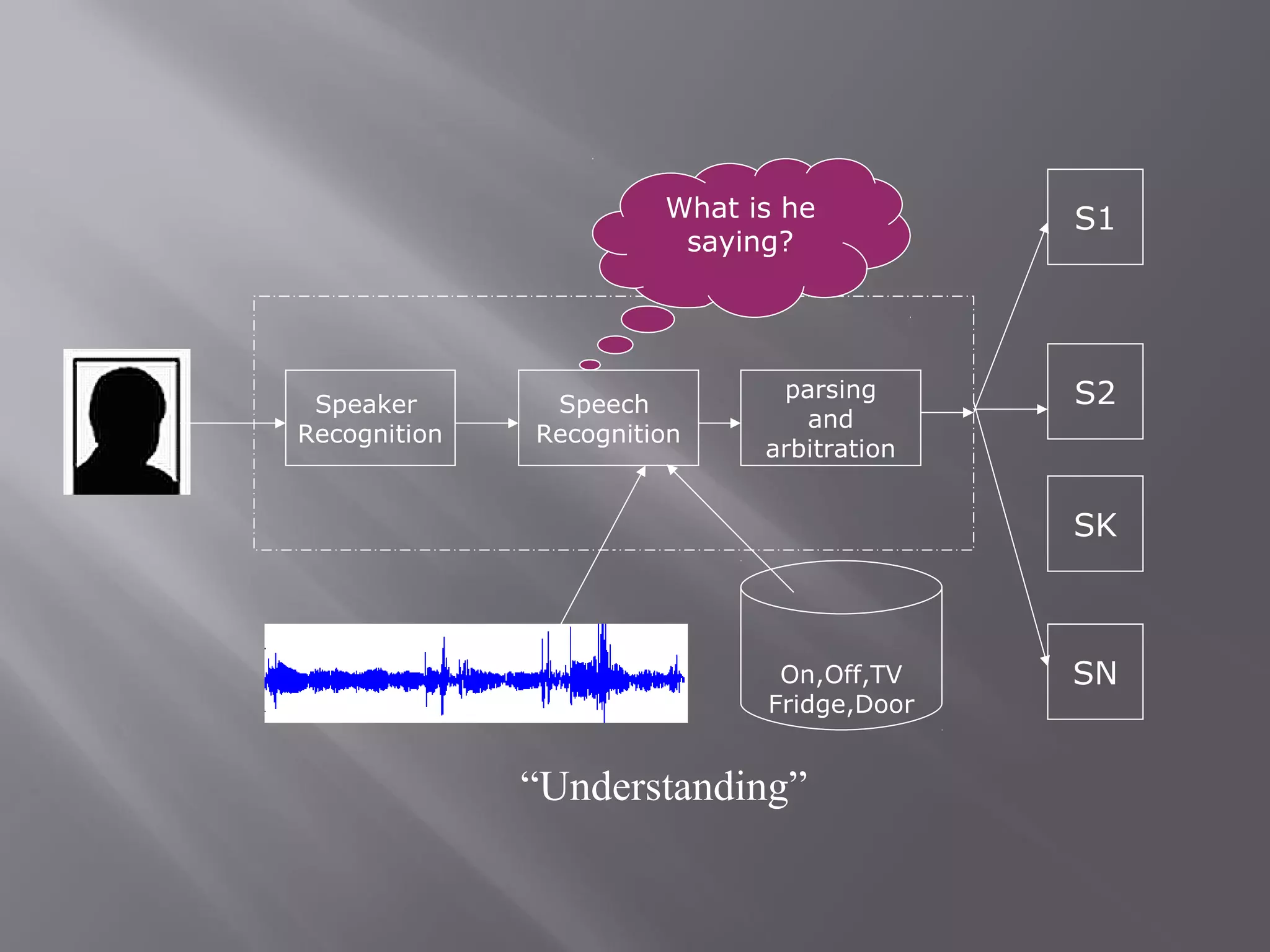
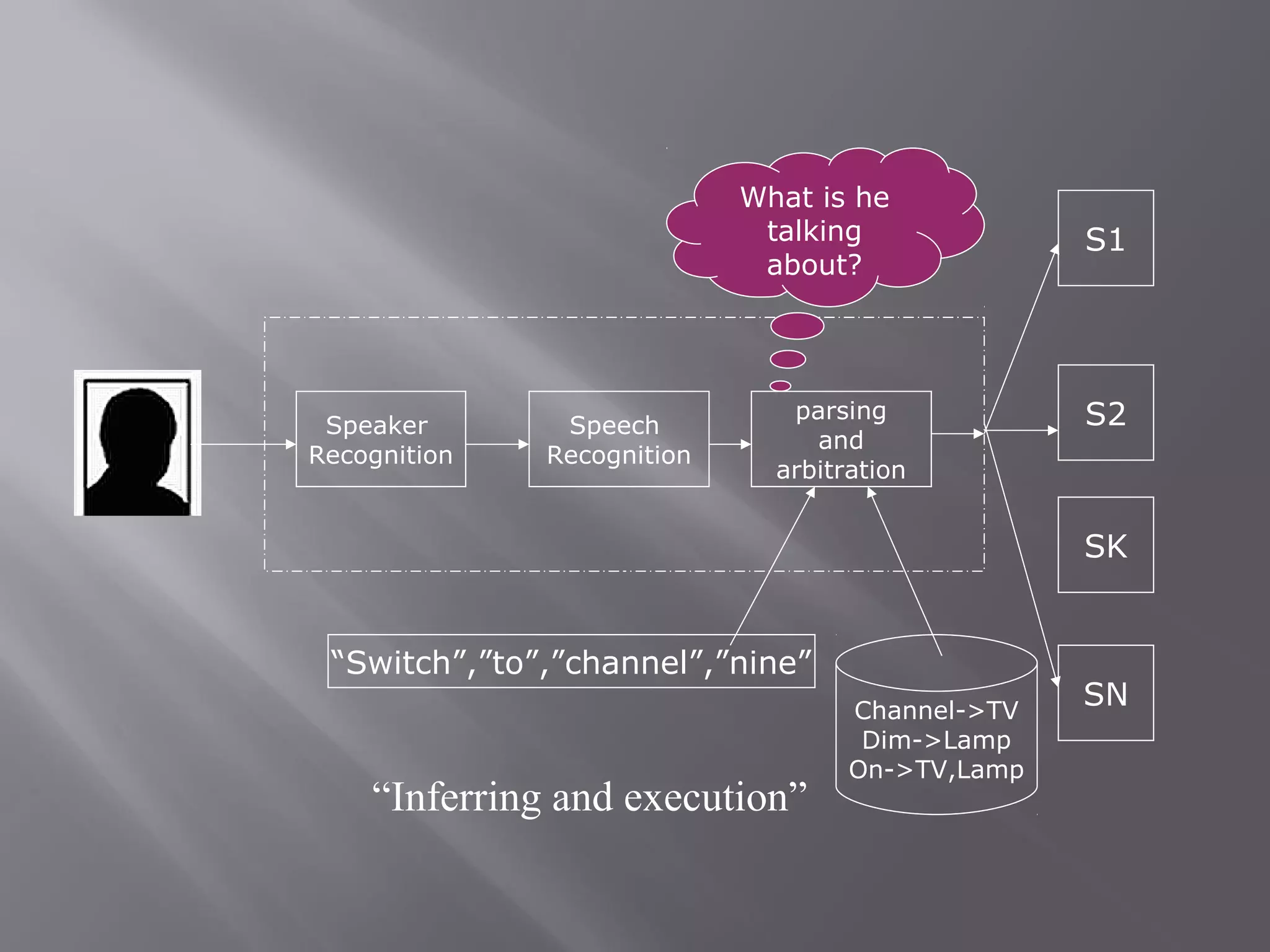



Speech recognition, also known as automatic speech recognition, allows a computer to understand human voice and perform tasks. It uses acoustic and language models to recognize speech. Acoustic models are statistical representations of sounds created from audio recordings and transcriptions, while language models predict word sequences. There are two main types: speaker-dependent systems require user training to recognize individual voices more accurately, while speaker-independent systems used in applications like phones do not require training but are generally less accurate. The speech recognition process involves digitizing speech, analyzing acoustic signals, and linguistically interpreting the speech to recognize words.
Definition of speech recognition; uses in system navigation and industrial applications.
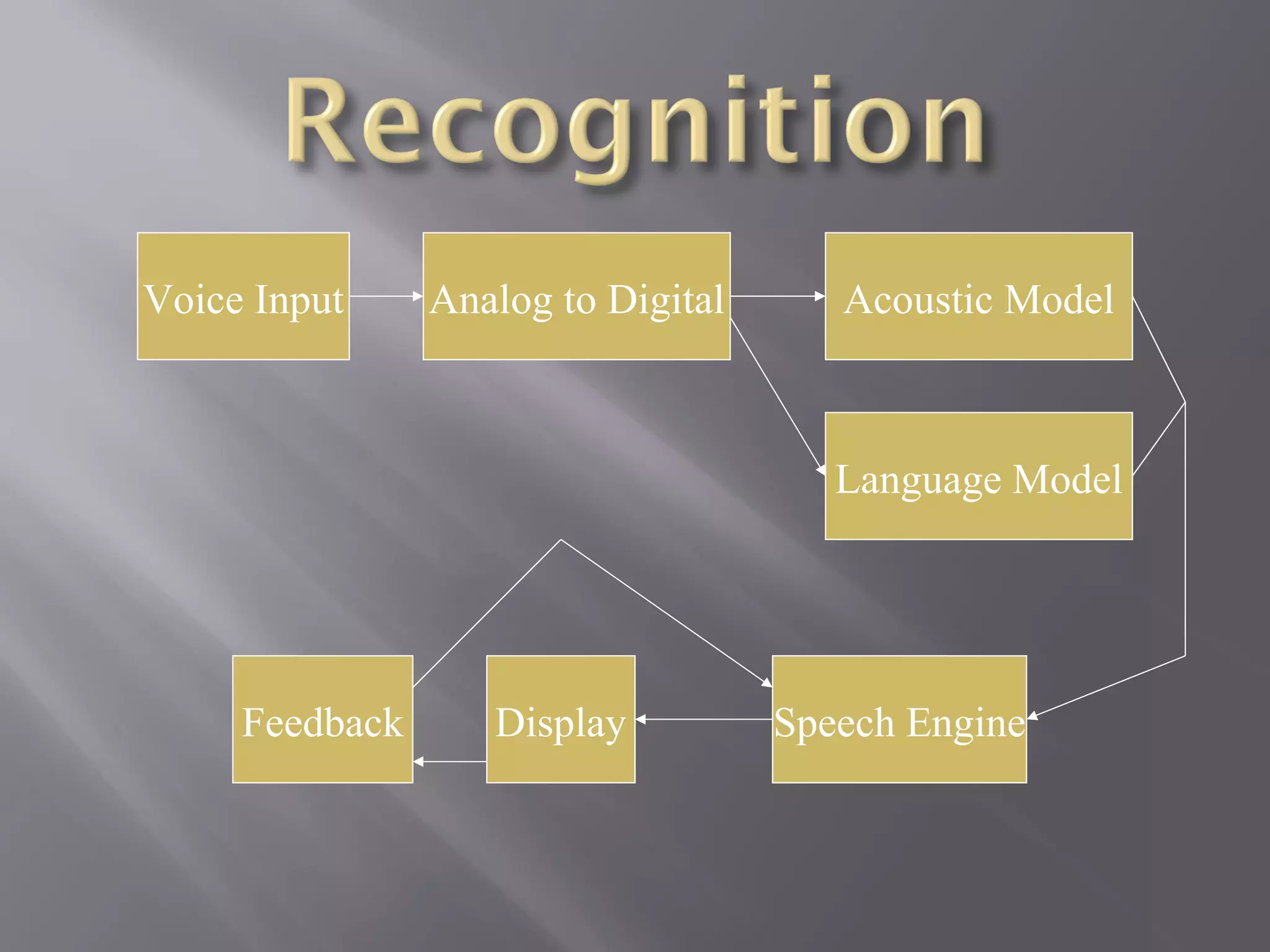
Details on acoustic and language models used for speech recognition processes.
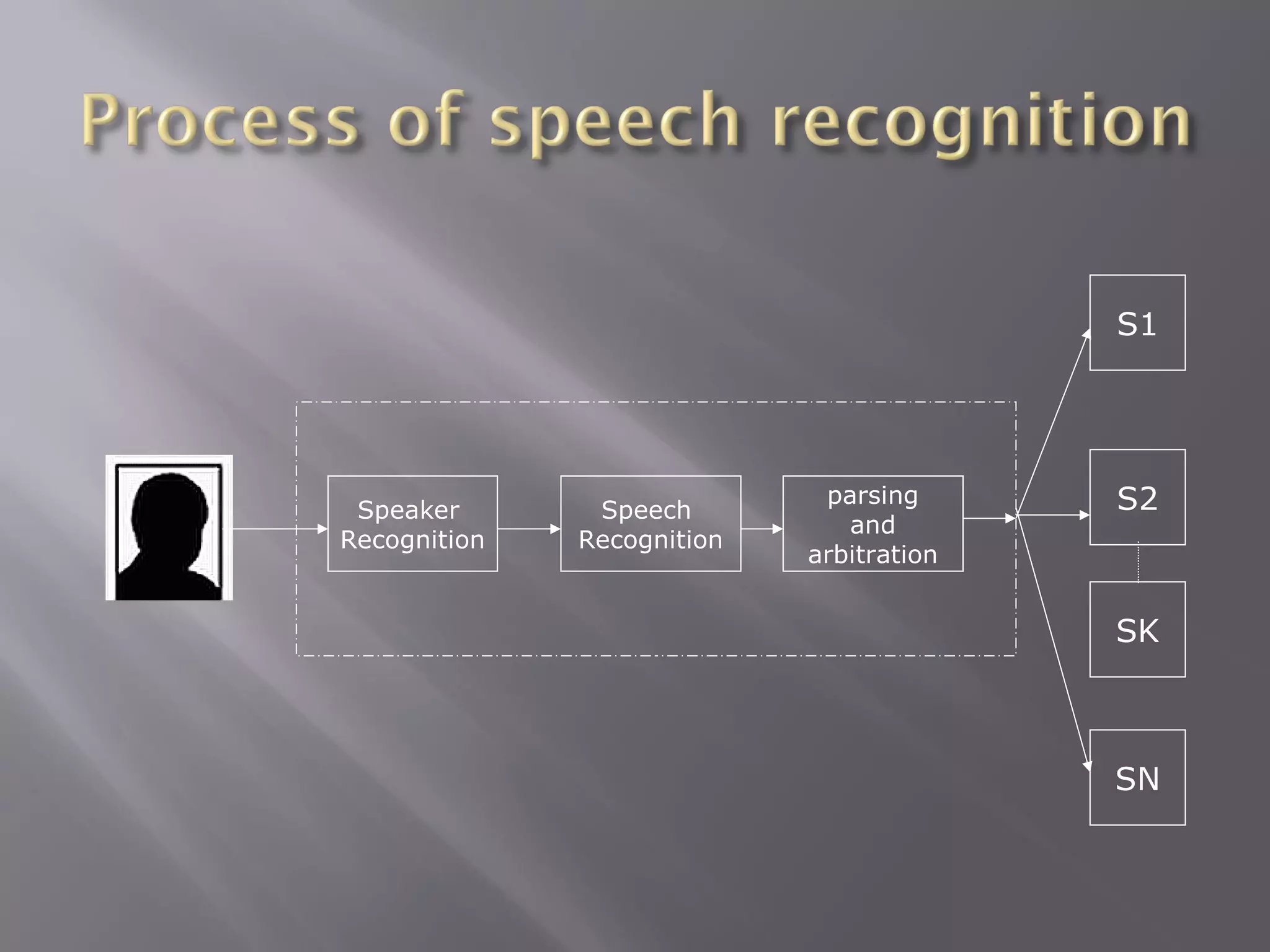
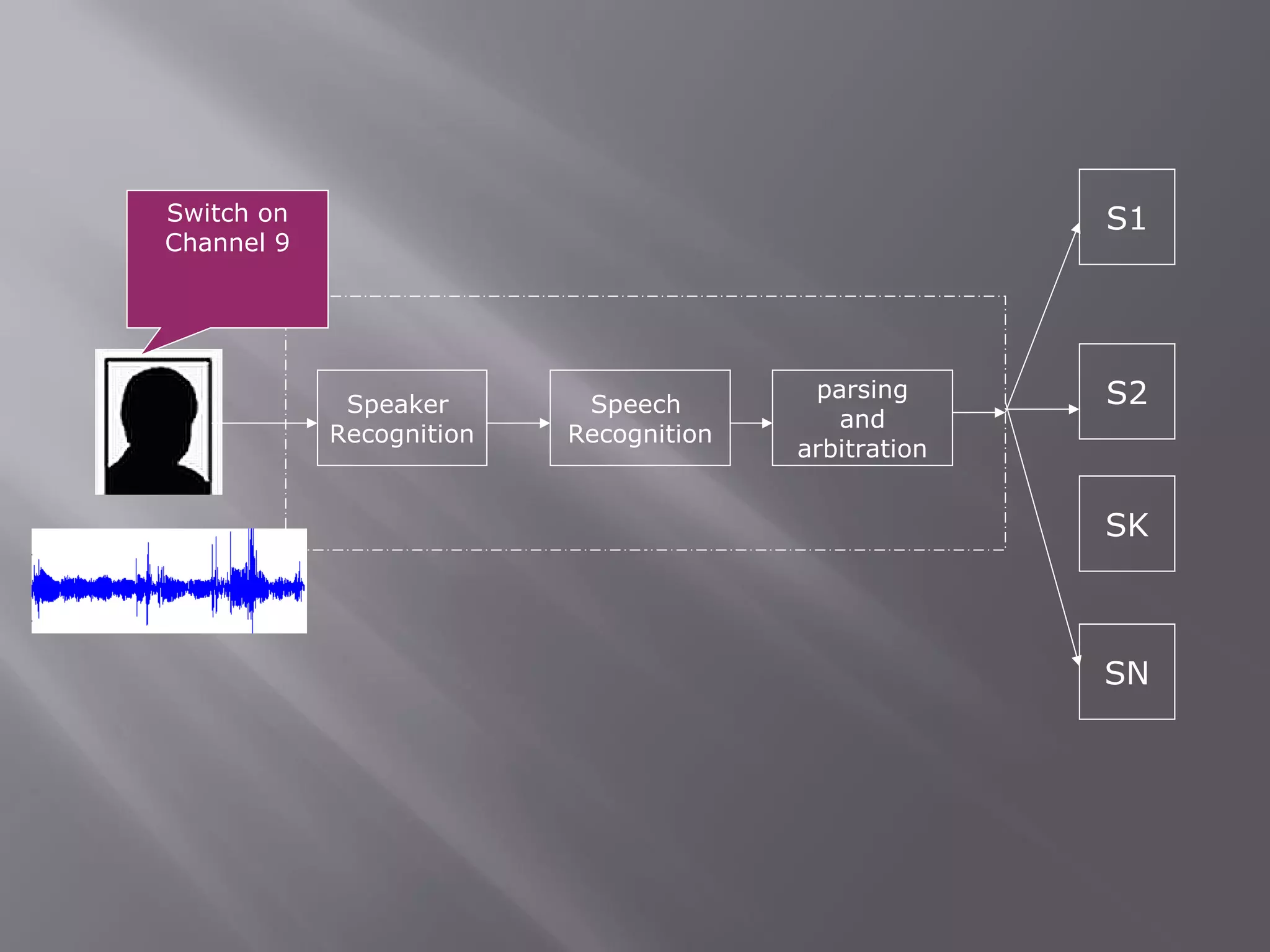
Explains speaker-dependent and speaker-independent speech recognition, their functions, and accuracy.
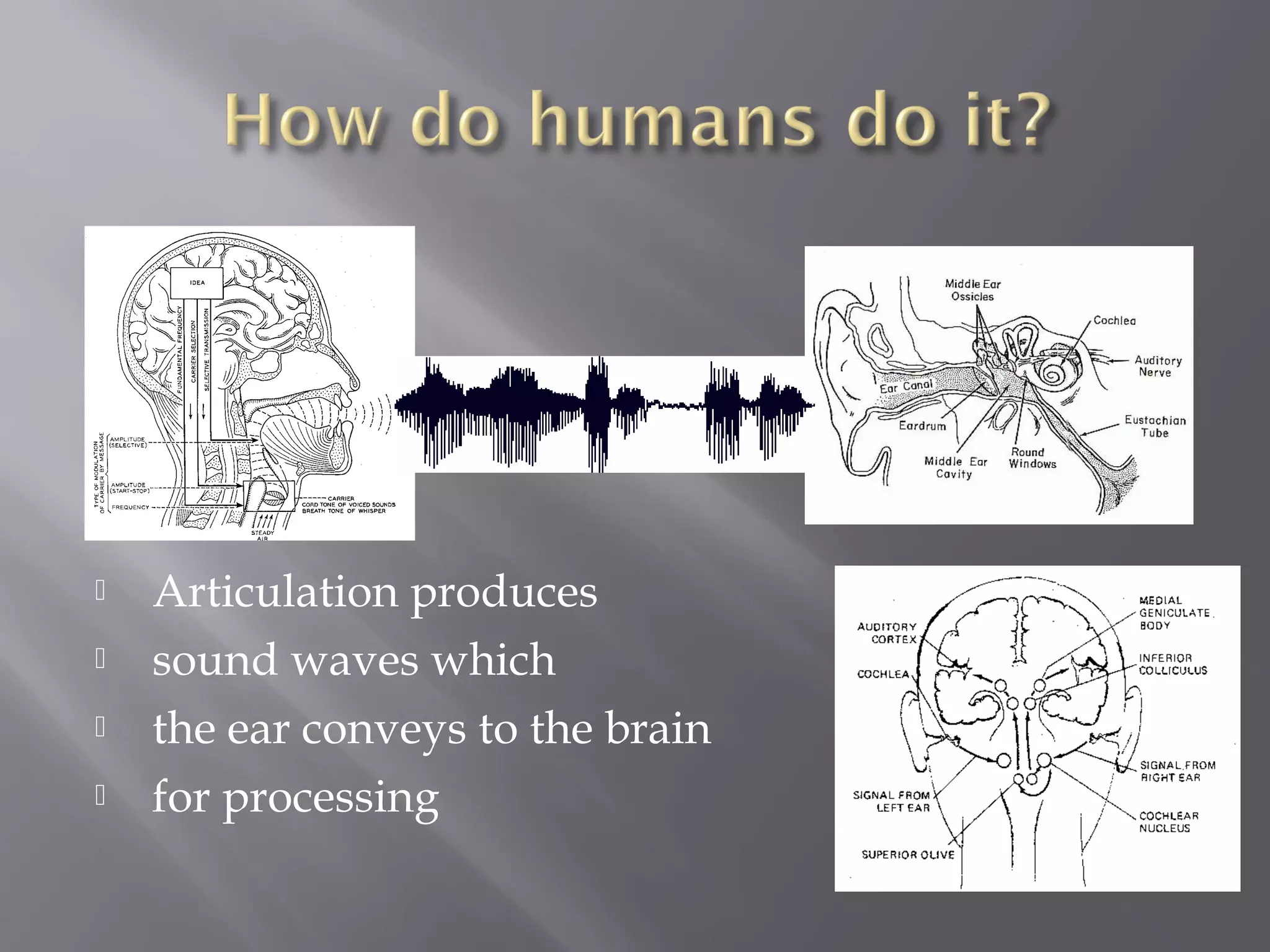
Processes like articulation, digitization, signal processing, phonetics, and phonology essential for recognition.
In-depth exploration of semantics, pragmatics, and the recognition process involving inference and execution.
List of external links and resources related to speech recognition.























































































