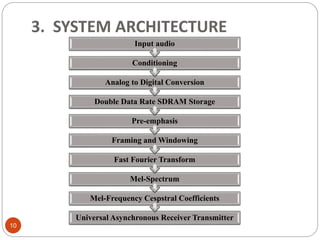
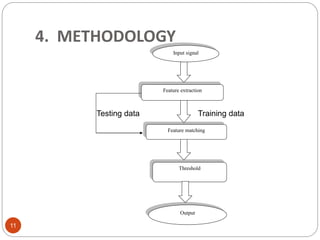
Downloaded 139 times







![4.1.2. Pre-Processing(2)
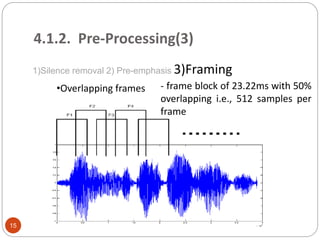
1)Silence removal 2) Pre-
emphasis
s’[n]=s[n]-a s[n-1] ……
[1]
[1] Shi-Huang Chen and Yu-Ren Luo, Speaker Verification Using MFCC
and Support Vector Machine14](https://image.slidesharecdn.com/textindependent-speaker-recognition-system-160214081148/85/Text-independent-speaker-recognition-system-14-320.jpg)
![4.1.2. Pre-Processing(4)
1)Silence removal 2) Pre-emphasis 3)Framing 4)Windowing
x[n] = s’[n] . w[n-m]
if n=0,1,2,…,N-1
if n=m,m+1,…..m+N-1
[2]
[2] Shi-Huang Chen and Yu-Ren Luo , Speaker Verification Using
MFCC and Support Vector Machine16](https://image.slidesharecdn.com/textindependent-speaker-recognition-system-160214081148/85/Text-independent-speaker-recognition-system-16-320.jpg)
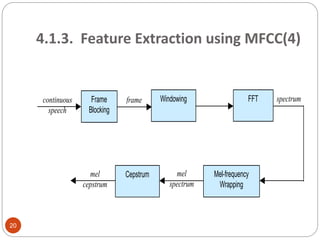
![4.1.3. Feature Extraction using MFCC
MFCC : Mel Filter Cepstral Coefficients
Perceptual approach
the human perception of speech, are applied to
the sample frames extract the features of speech.
Steps for calculating MFCC
1. Discrete Fourier Transform using FFT and
Power spectrum , X[k]|2 of signal
17](https://image.slidesharecdn.com/textindependent-speaker-recognition-system-160214081148/85/Text-independent-speaker-recognition-system-17-320.jpg)
![4.1.3. Feature Extraction using MFCC(2)
2. Mel scaling
Mel scale : linear up to 1 KHz and logarithmic after 1 KHz
. Mapping the powers of the spectrum onto the Mel scale,
using Mel filter bank-Mel spectral coefficients G[k]
Filter bank:
overlapping windows
18](https://image.slidesharecdn.com/textindependent-speaker-recognition-system-160214081148/85/Text-independent-speaker-recognition-system-18-320.jpg)
![4.1.3. Feature Extraction using MFCC(3)
3.log of Mel spectral coefficients has been taken
log(G[k]).
4. Discrete Cosine Transform (DCT) ->Mel-cepstrum
c[q].
(Source: Shi-Huang Chen and Yu-Ren Luo , Speaker Verification
Using MFCC and Support Vector Machine)
(3.4)
19](https://image.slidesharecdn.com/textindependent-speaker-recognition-system-160214081148/85/Text-independent-speaker-recognition-system-19-320.jpg)

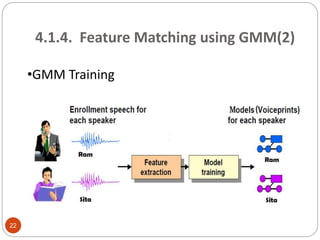

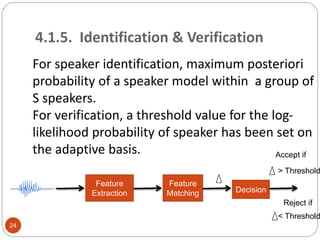









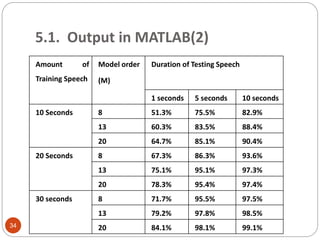



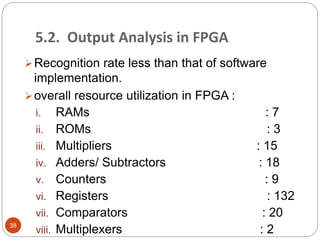
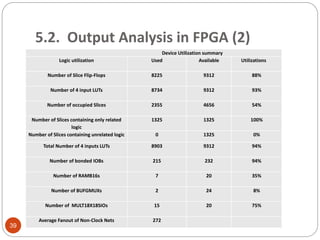
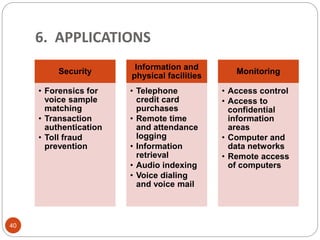





This document outlines a project to develop a text-independent speaker recognition system. It lists the project members and provides an overview of the presentation sections, which include the system architecture, methodology, results and analysis, and applications. The methodology section describes implementing the system in MATLAB, including voice capturing, pre-processing, MFCC feature extraction, GMM matching, and identification/verification. It also outlines implementing the system on an FPGA, including analog conversion, storage, framing, FFT, mel spectrum, MFCC extraction, and UART transmission to MATLAB for further processing. The results show over 99% recognition accuracy with longer training and test data.











![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)











































































