Download as PDF, PPTX












![Speech Feature Extraction...Contd
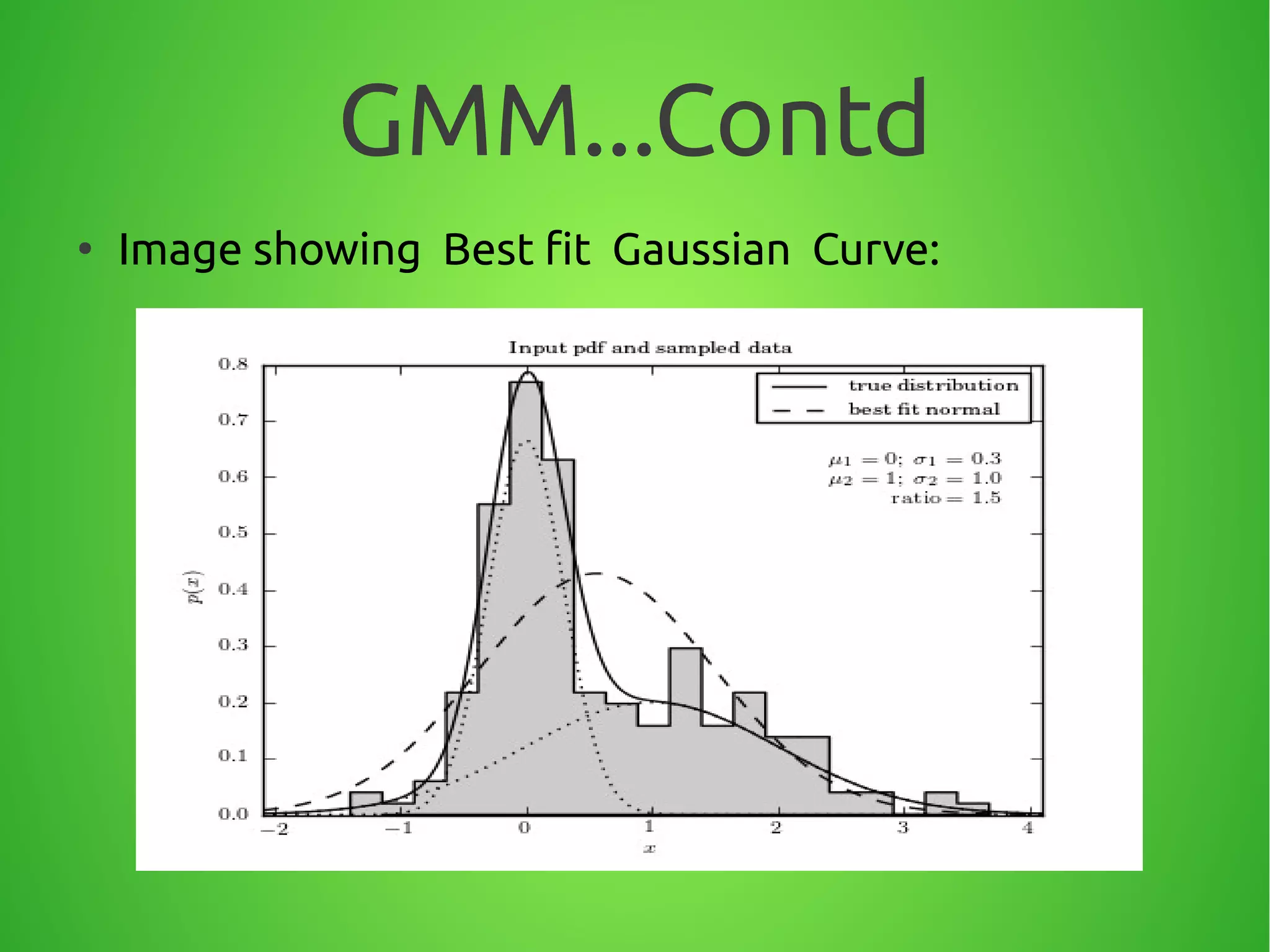
●
Pre-emphasis: In speech processing, the original
signal usually has too much lower frequency energy,
and processing the signal to emphasize higher
frequency energy is necessary. To perform
pre-emphasis, we choose some value α between 0.9
and 1. Then each value in the signal is re-evaluated
using this formula:
This is apparently a first order high pass filter.
y[n]=x[n]−α x[n−1], where 0.9<α<1](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-17-2048.jpg)


![Speech Feature Extraction...Contd
● Fast Fourier Transform (FFT): The Discrete
Fourier Transform (DFT) of a discrete-time signal
x(nT) is given by:
Where:
X (k)= ∑
n=0
N−1
x [n]e
−j
2π
N
nk
k=0,1,…N−1
x (nT )=x [n]](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-22-2048.jpg)
![Speech Feature Extraction...Contd
●
If we let: thene
−j
2π
N
=W N
X (k)= ∑
n=0
N−1
x [n]W N
nk
0 20 40 60 80 100 120
-2
-1
0
1
2
Sampledsignal
Sample
Amplitude
0 0.1 0.2 0.3 0.4 0.5
0
0.2
0.4
0.6
0.8
1
FrequencyDomain
NormalisedFrequency
Magnitude
Figure 10](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-23-2048.jpg)
![Speech Feature Extraction...Contd
● x[n] = x[0], x[1], …, x[N-1]
X (k)= ∑
n=0
N−1
x[n]W N
nk
; 0≤k≤N−1 [1][1]
Lets divide the sequence x[n] into even and odd
sequences:
x[2n] = x[0], x[2], …, x[N-2]
x[2n+1] = x[1], x[3], …, x[N-1]](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-24-2048.jpg)
![Speech Feature Extraction...Contd
●
Equation 1 can be rewritten as:
X (k)= ∑
n=0
N
2
−1
x[2n]WN
2nk
+ ∑
n=0
N
2
−1
x[2n+1]WN
(2n+1)k
[2][2]
Since:
W N
2 nk
=e
− j
2π
N
2 nk
=e
−j
2π
N /2
nk
=W N
2
nk W N
(2n+1)k
=W N
k
⋅W N
2
nk
Then:
X (k)= ∑
n=0
N
2
−1
x [2n]WN
2
nk
+WN
k
∑
n=0
N
2
−1
x [2n+1]WN
2
nk
=Y (k )+WN
k
Z (k )
and](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-25-2048.jpg)
![Speech Feature Extraction...Contd
●
The result is that an N-point DFT can be divided into
two N/2 point DFT’s:
●
Where Y(k) and Z(k) are the two N/2 point DFTs
operating on even and odd samples respectively:
X (k)= ∑
n=0
N−1
x[n]W N
nk
; 0≤k≤N−1 N-point DFTN-point DFT
X (k)= ∑
n=0
N
2
−1
x1[n]WN
2
nk
+W N
k
∑
n=0
N
2
−1
x2[n]WN
2
nk
=Y (k )+WN
k
Z (k )
TwoTwo
N/2-pointN/2-point
DFTsDFTs](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-26-2048.jpg)
![Speech Feature Extraction...Contd
●
Periodicity and symmetry of W can be exploited to
simplify the DFT further:
X (k )= ∑
n=0
N
2
−1
x1[n]W N
2
nk
+W N
k
∑
n=0
N
2
−1
x2[n]W N
2
nk
⋮
X(k+
N
2 )= ∑
n=0
N
2
−1
x1[n]W N
2
n(k +
N
2 )+W
N
k+
N
2
∑
n=0
N
2
−1
x2 [n]W N
2
n(k+
N
2 )
[3][3]
Or: W N
k+
N
2
=e
− j
2π
N
k
e
−j
2π
N
N
2
=e
−j
2π
N
k
e−jπ
=−e
−j
2π
N
k
=−W N
k : Symmetry: Symmetry
And: W N
2
k+
N
2
=e
− j
2π
N /2
k
e
− j
2π
N /2
N
2
=e
− j
2π
N /2
k
=W N
2
k : Periodicity: Periodicity](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-27-2048.jpg)
![Speech Feature Extraction...Contd
●
Finally by exploiting the symmetry and periodicity,
Equation 3 can be written as:
●
Hence Complete Equations for finding FFT are:
X (k+
N
2 )= ∑
n=0
N
2
−1
x1[n]W N
2
nk
−W N
k
∑
n=0
N
2
−1
x2[n]W N
2
nk
=Y (k)−W N
k
Z (k )
[4][4]
X (k)=Y (k)+WN
k
Z (k ); k=0,…(N
2
−1)
X (k+
N
2 )=Y (k)−WN
k
Z (k); k=0,…(N
2
−1)](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-28-2048.jpg)
![Speech Feature Extraction...Contd
●
Schematic Diagram for FFT: Radix-2 butterfly diagram
y[0]y[0]
y[1]y[1]
y[2]y[2]
y[N-2]y[N-2]
N/2 pointN/2 point
DFTDFT
x[0]x[0]
x[2]x[2]
x[4]x[4]
x[N-2]x[N-2]
N/2 pointN/2 point
DFTDFT
x[1]x[1]
x[3]x[3]
x[5]x[5]
x[N-1]x[N-1]
z[0]z[0]
z[1]z[1]
z[2]z[2]
z[N/2-1]z[N/2-1]
X[1] = y[1]+WX[1] = y[1]+W11z[1]z[1]
WW11
X[0] = y[0]+WX[0] = y[0]+W00z[0]z[0]
WW00
X[N/2] = y[0]-WX[N/2] = y[0]-W00z[0]z[0]-1-1
X[N/2+1] = y[1]-WX[N/2+1] = y[1]-W11z[1]z[1]-1-1](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-29-2048.jpg)

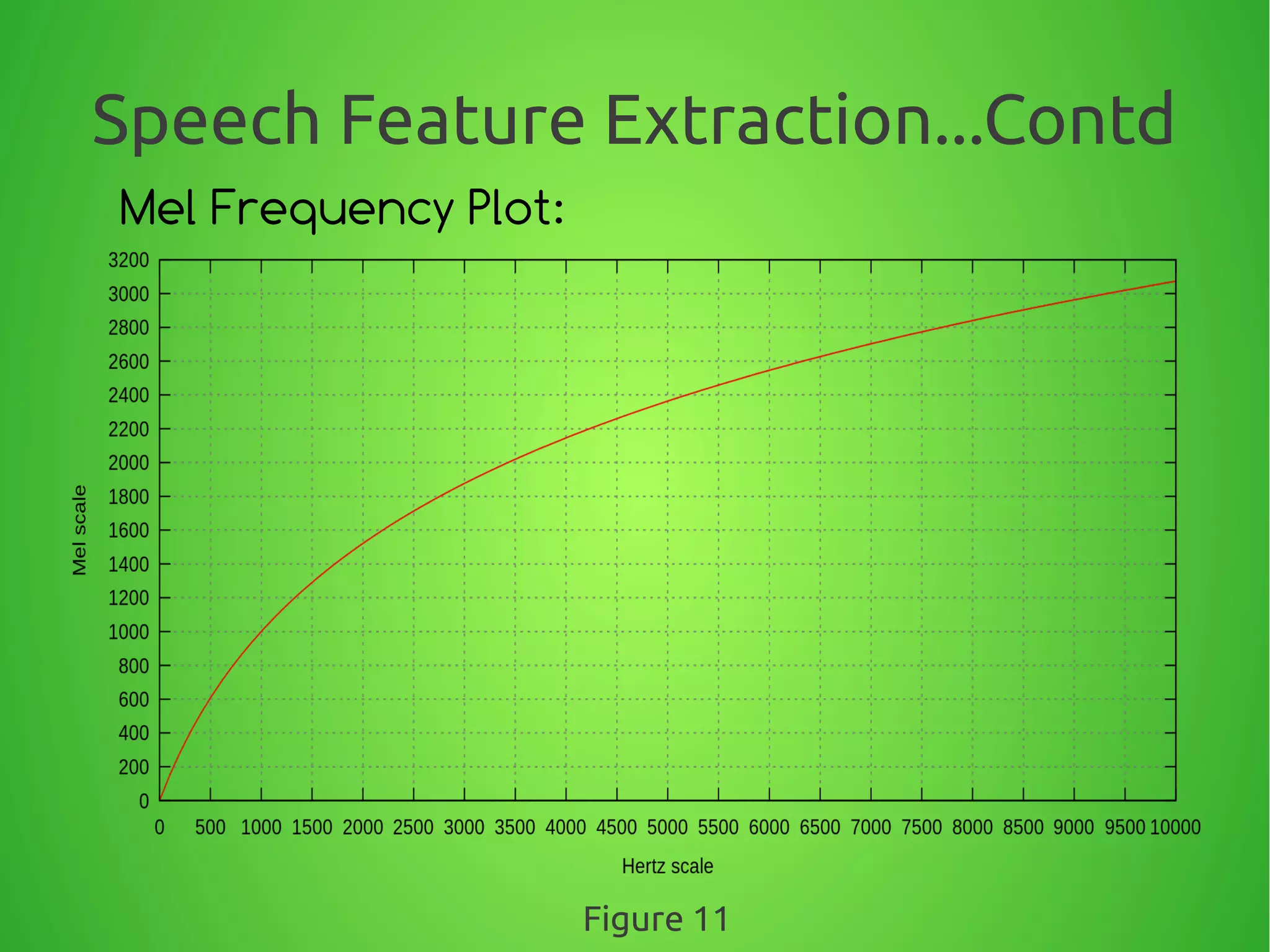

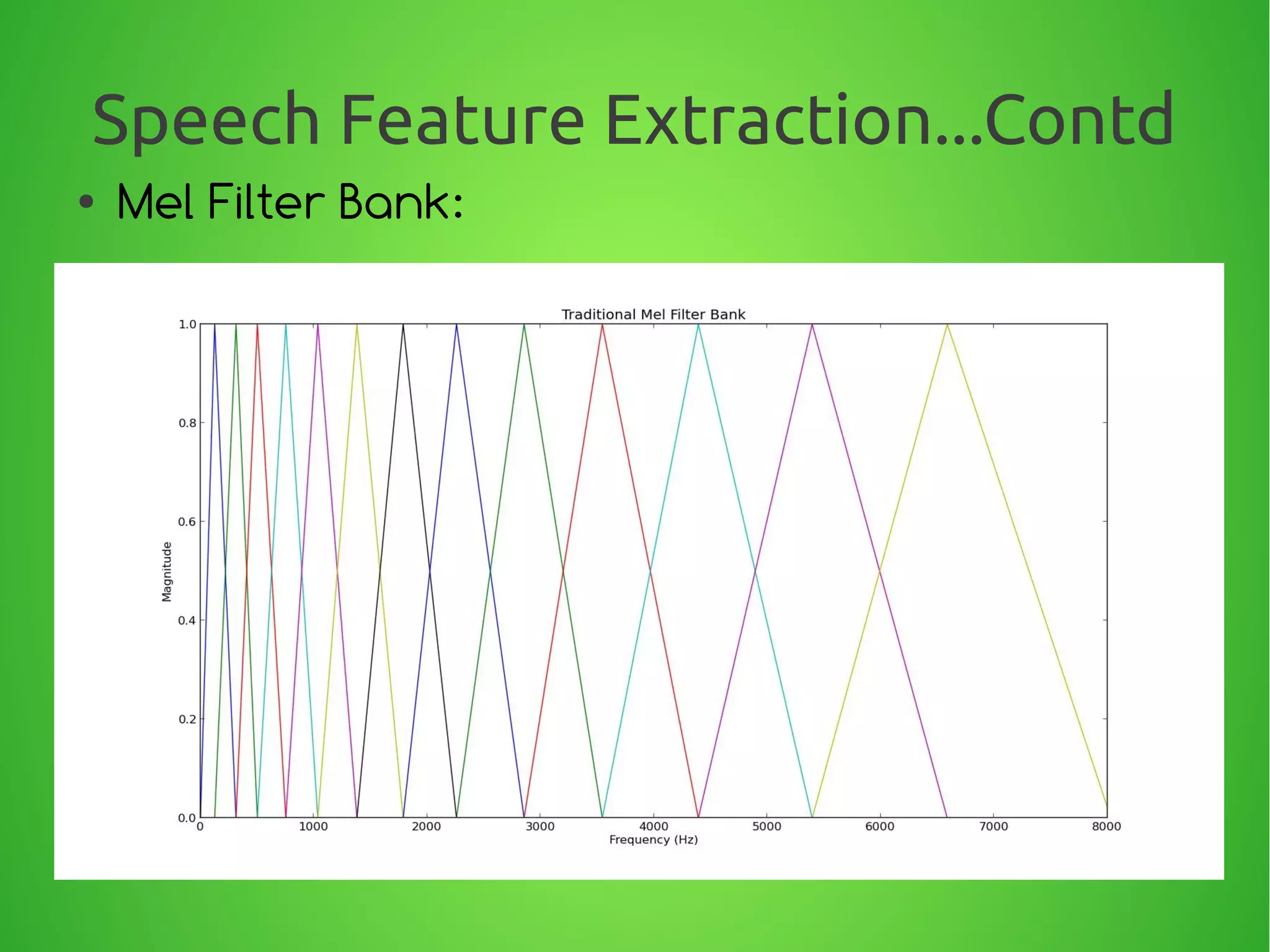
![Speech Feature Extraction...Contd
●
Equally Spaced Mel values:
●
We define a triangular filter-bank with M filters (m=1, 2,...,M) where,
Hm[ k ] , is the magnitude (frequency response) of the filter given by:
Hm( k) =
{
0, k< f ( m−1)
k− f ( m−1)
f ( m)−f ( m−1)
, f ( m−1)≤k≤f ( m)
f ( m+1)− k
f (m+ 1)−f (m)
, f ( m)≤k≤ f ( m+1)
0, k> f ( m+1)
}](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-33-2048.jpg)
![Speech Feature Extraction...Contd
●
Given the FFT of the input signal, x[n]
●
The values of FFT are weighted by triangular filters.
The result is called Mel-frequency power spectrum
which is defined as:
where is called the Power Spectrum.
X [k]=∑
n=0
N−1
x[n]e
−j2 π nk/ N
,0≤k≤N
S[m]=∑
k=1
N
∣Xa [k]∣
2
Hm[k],0<m≤M
∣Xa [k]∣
2](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-35-2048.jpg)
![Speech Feature Extraction...Contd
●
Schematic diagram of Filter Bank Energy:
●
Finally, a discrete cosine transform (DCT) of the
logarithm of S[m] is computed to form the MFCCs as:
mfcc[i]=∑
m=1
M
log(S[m])cos[i(m−
1
2
) π
M
],
i=1,2,........., L](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-36-2048.jpg)












![References
●
[1] Molau, S., Pitz, M., Schlüter, R. & Ney, H. (2001), Computing Mel-Frequency
Cepstral Coefficients on the Power Spectrum, IEEE International Conference on
Acoustics, Speech and Signal Processing, Germany, 2001: 73-76.
●
[2] Huang, X., Acero, A. & Hon, H. (2001), Spoken Language Processing - A Guide to
Theory, Algorithm, and System Development, Prentice Hall PTR, New Jersey.
●
[3] Homayoon Beigi, (2011), Fundamentals of Speaker Recognition, Springer.
●
[4] Daniel J. Mashao, Marshalleno Skosan, Combining classifier decisions for robust
speaker identification, ELSEVIER 2006.
●
[5] W.M. Campbell , J.P. Campbell, D.A. Reynolds, E. Singer, P.A. Torres-Carrasquillo,
Support vector machines for speaker and language recognition, ELSEVIER, 2006.
●
[6] Seiichi Nakagawa, Kouhei Asakawa, Longbiao Wang, Speaker Recognition by
Combining MFCC and Phase Information, INTERSPEECH 2007.
●
[7] Nilsson, M. & Ejnarsson, M, Speech Recognition Using Hidden Markov Model
Performance Evaluation in Noisy Environment, Blekinge Institute of Technology
Sweden, 2002.](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-50-2048.jpg)
![References...Contd●
[8] Stevens, S. S. & Volkman, J. (1940), The Relation of the Pitch to
Frequency , Journal of Psychology, 1940(53): 329.
●
[9] A . Jain, A. Ross, and S. Prabhakar, “An introduction to biometric
recognition,” IEEETrans. Circuits Systems Video Technol., vol. 14, no. 1, pp.
4–20, 2004.
●
[10] D. Reynolds, “An overview of automatic speaker recognition
technology,” in Proc. IEEE Int. Conf. Acoustics Speech Signal Processing
(ICASSP), 2002, vol. 4, pp. 4072–4075.
●
[11] S. Furui, “Cepstral analysis technique for automatic speaker
verification,” IEEE Trans. Acoustics Speech Signal Process., vol. 29, no. 2, pp.
254–272, 1981.
●
[12] D. Reynolds and R. Rose, “Robust text-independent speaker
identification using Gaussian mixture speaker models,” IEEE Trans. Speech
Audio Process., vol. 3, no. 1, pp. 72–83, 1995.
●
[13] D. Reynolds, “Speaker identification and verification using Gaussian
mixture speaker models,” Speech Commun., vol. 17, no. 1–2, pp. 91–108,
1995.](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-51-2048.jpg)
![References...Contd
●
[14] Man-Wai Mak , Wei Rao, Utterance partitioning with acoustic vector
resampling for GMM–SVM speaker verification, ELSEVIER, 2011.
●
[15] Md. Sahidullah, Goutam Saha, Design, analysis and experimental
evaluation of block based transformation in MFCC computation for speaker
recognition, ELSEVIER, 2011.
●
[16] Qi Li, and Yan Huang, An Auditory-Based Feature Extraction Algorithm for
Robust Speaker Identification Under Mismatched Conditions , IEEE
TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 19,
NO. 6, AUGUST 2011.
●
[17] Alfredo Maesa, Fabio Garzia, Michele Scarpiniti, Roberto Cusani, Text
Independent Automatic Speaker Recognition System Using Mel-Frequency
Cepstrum Coefficient and Gaussian Mixture Models, Journal of Information
Security, 2012.
●
[18] Ming Li, Kyu J. Han, Shrikanth Narayanan, Automatic speaker age and
gender recognition using acoustic and prosodic level information fusion,
ELSEVIER, 2013.](https://image.slidesharecdn.com/d7789e5b-9154-46da-9a0c-0e9728432531-160304102232/75/ASR_final-52-2048.jpg)


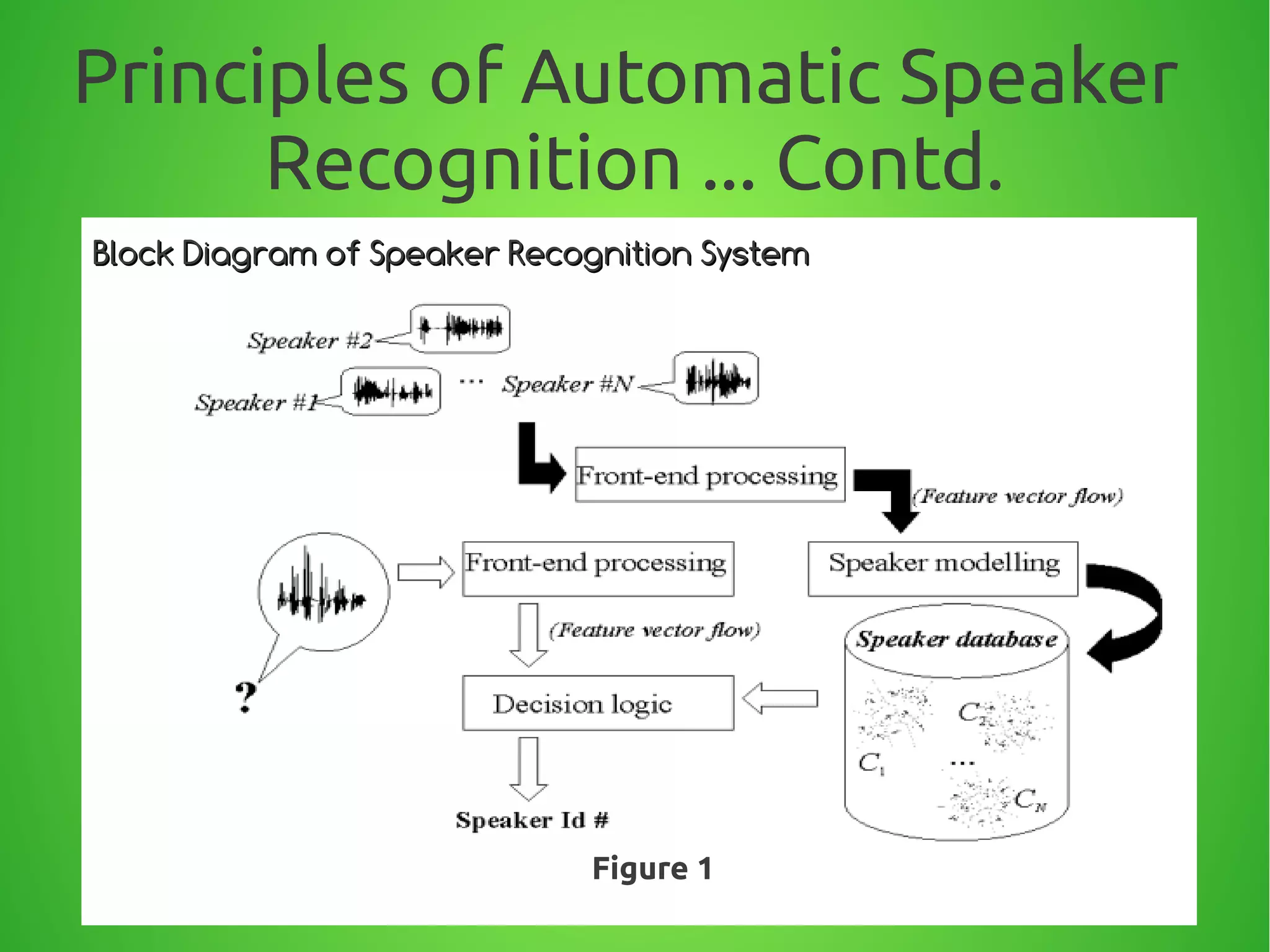
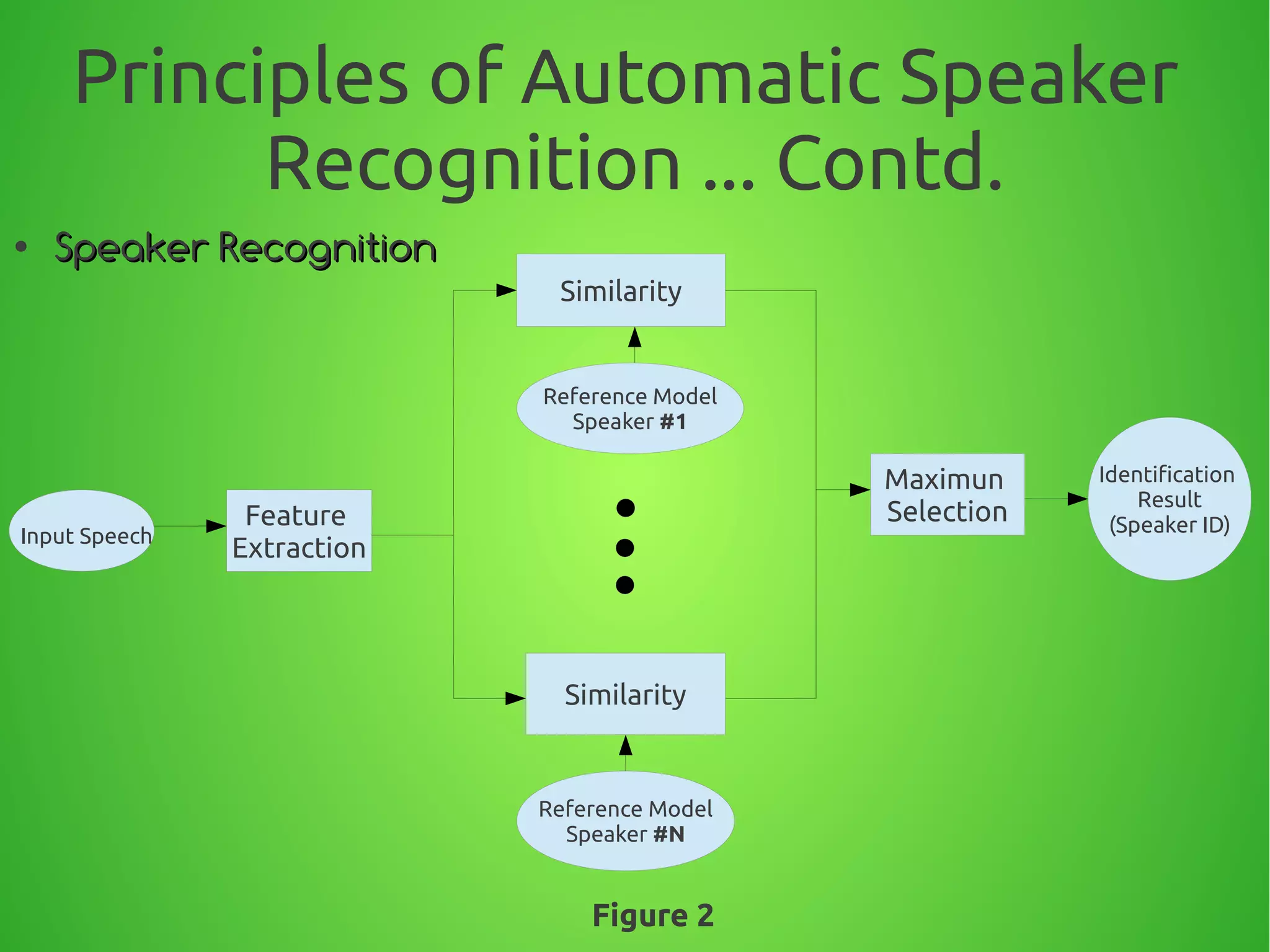
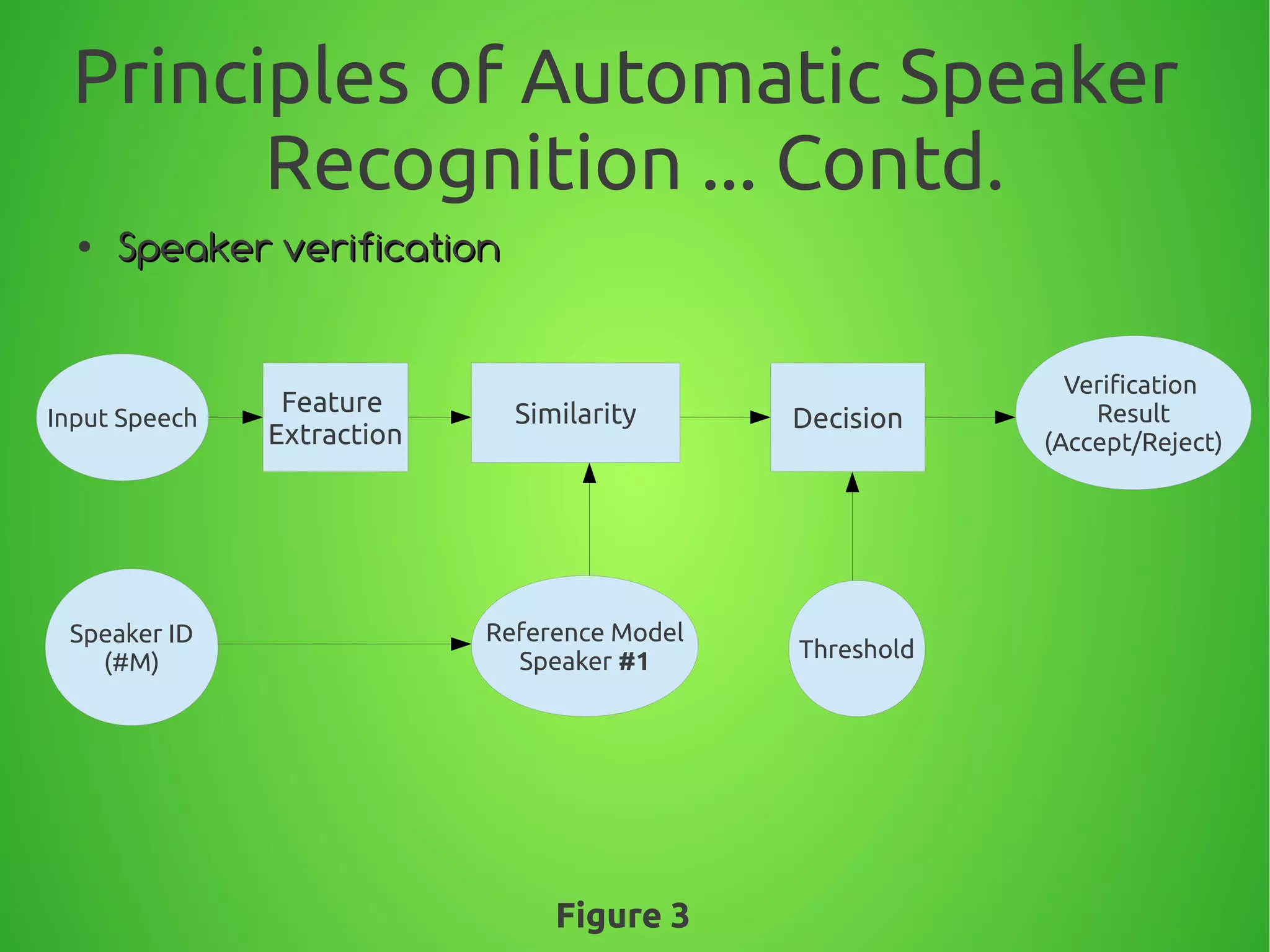
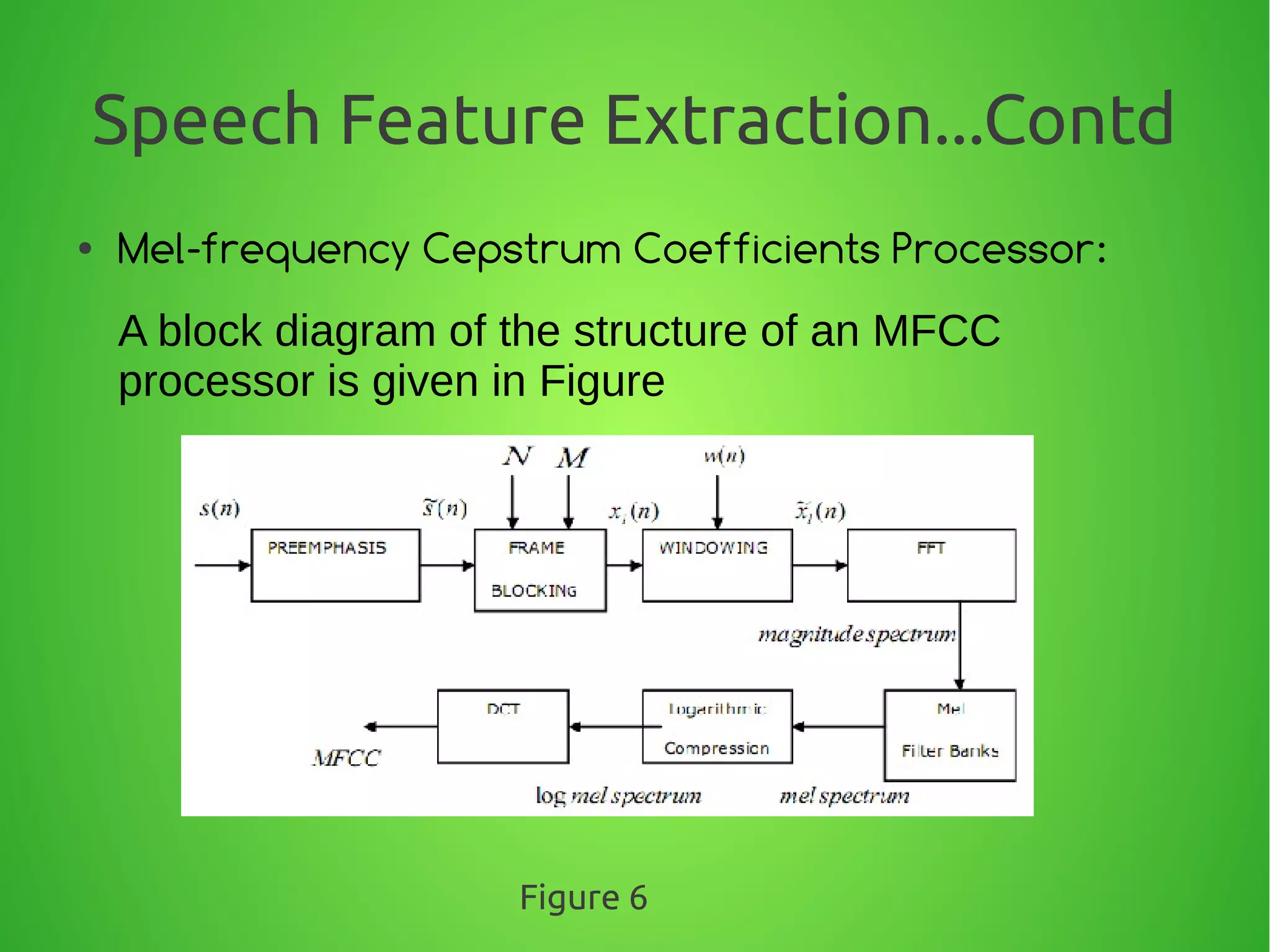
The document summarizes techniques for text-independent speaker recognition from audio signals. It discusses the principles of automatic speaker recognition including identification and verification. The key steps are voice recording, feature extraction using MFCC, modeling reference models for each speaker, pattern matching of input features against models, and making an identification or verification decision. Feature extraction involves framing the audio, windowing, FFT, mapping frequencies to the mel scale, and taking the DCT to produce cepstral coefficients.

































