
![Chapter: 2 (Tutorial)
2
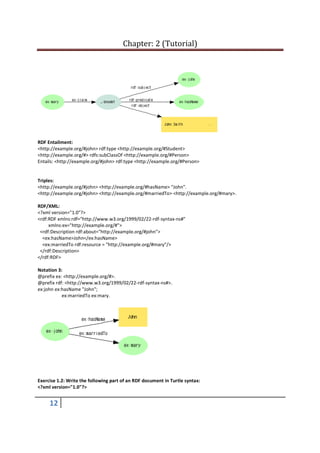
2. [RDF-Concept] is studied by Kishoj and Pradeep in order.
RDF/XML:
<rdf:RDF
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex = "http://example.org/"
>
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-concepts/">
<ex:studiedBy>
<rdf:Seq>
<rdf:li rdf:resource = "http://example.org/Kishoj"/>
<rdf:li rdf:resource = "http://example.org/Pradeep"/>
</rdf:Seq>
</ex:studiedBy>
</rdf:Description>
</rdf:RDF>
Notation 3:
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix ex: <http://example.org/>.
<http://www.w3.org/TR/rdf-concepts/> ex:studiedBy _:bnode1.
_:bnode1 rdf:type rdf:Seq;
rdf:_1 ex:Kishoj;
rdf:_2 ex:Pradeep.
Triples:
_:b1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-
syntax-ns#Seq>.
_:b1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#_1> <http://example.org/Kishoj>.
_:b1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#_2> <http://example.org/Pradeep>.
<http://www.w3.org/TR/rdf-concepts/> <http://example.org/studiedBy> _:b1.](https://image.slidesharecdn.com/tutorial2-130724035355-phpapp01/85/Tutorial-for-RDF-Graphs-2-320.jpg)

![Chapter: 2 (Tutorial)
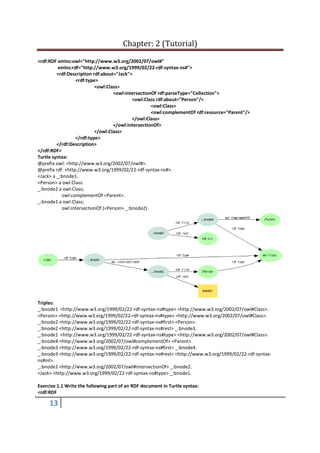
4
Convert the given graph to RDF/XML, Notation 3, turtle, triples and JSON.
RDF/XML:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor>
<rdf:Description ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/" />
</rdf:Description>
</ex:editor>
</rdf:Description>
</rdf:RDF>
Notation 3:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix dc: <http://purl.org/dc/elements/1.1/>.
@prefix ex: <http://example.org/stuff/1.0/>.
<http://www.w3.org/TR/rdf-syntax-grammar> ex:editor
[ ex:fullName "Dave Beckett"; ex:homePage <http://purl.org/net/dajobe/> ];
dc:title "RDF/XML Syntax Specification (Revised)".
Turtle: .ttl extension:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix dc: <http://purl.org/dc/elements/1.1/>.](https://image.slidesharecdn.com/tutorial2-130724035355-phpapp01/85/Tutorial-for-RDF-Graphs-4-320.jpg)
![Chapter: 2 (Tutorial)
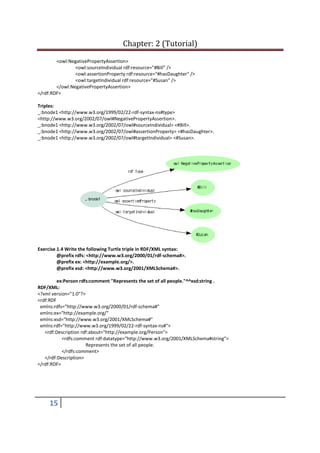
5
@prefix ex: <http://example.org/stuff/1.0/>.
<http://www.w3.org/TR/rdf-syntax-grammar> dc:title "RDF/XML Syntax Specification (Revised)";
ex:editor [ ex:fullname "Dave Beckett"; ex:homePage <http://purl.org/net/dajobe/>].
Triples:
<http://www.w3.org/TR/rdf-syntax-grammar> <http://purl.org/dc/elements/1.1/title> "RDF/XML Syntax
Specification (Revised)".
_:bnode1 <http://example.org/stuff/1.0/fullName> "Dave Beckett".
_:bnode1 <http://example.org/stuff/1.0/homePage> <http://purl.org/net/dajobe/>.
<http://www.w3.org/TR/rdf-syntax-grammar> <http://example.org/stuff/1.0/editor> _:bnode1.
RDF/XML:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Seq rdf:about="http://example.org/favourite-fruit">
<rdf:li rdf:resource="http://example.org/banana"/>
<rdf:li rdf:resource="http://example.org/apple"/>
<rdf:li rdf:resource="http://example.org/pear"/>
</rdf:Seq>
</rdf:RDF>
Tripes: .nt extension
<http://example.org/favourite-fruit> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#Seq>.
<http://example.org/favourite-fruit> <http://www.w3.org/1999/02/22-rdf-syntax-ns#_1>
<http://example.org/banana>.
<http://example.org/favourite-fruit> <http://www.w3.org/1999/02/22-rdf-syntax-ns#_2>
<http://example.org/apple>.
<http://example.org/favourite-fruit> <http://www.w3.org/1999/02/22-rdf-syntax-ns#_3>
<http://example.org/pear>.
Turtle to graph:
@prefix : <http://example.org/stuff/1.0/>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
:a :b
[ rdf:first "apple";
rdf:rest [ rdf:first "banana";
rdf:rest rdf:nil ]
] .](https://image.slidesharecdn.com/tutorial2-130724035355-phpapp01/85/Tutorial-for-RDF-Graphs-5-320.jpg)






![Chapter: 2 (Tutorial)
14
xmlns:owl="http://www.w3.org/2002/07/owl#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
>
<owl:Class rdf:about="Parent">
<owl:equivalentClass>
<owl:Restriction>
<owl:onProperty rdf:resource="hasChild"/>
<owl:someValuesFrom rdf:resource="Person"/>
</owl:Restriction>
</owl:equivalentClass>
</owl:Class>
</rdf:RDF>
Notation 3:
@prefix owl: <http://www.w3.org/2002/07/owl#>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
<Parent> a owl:Class;
owl:equivalentClass _:bnode1.
_:bnode1 rdf:type owl:Restriction;
owl:onProperty <hasChild>;
owl:someValuesFrom <Person>.
Triples:
<Parent> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/2002/07/owl#Class>.
_:bnode1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/2002/07/owl#Restriction>.
_:bnode1 <http://www.w3.org/2002/07/owl#onProperty> <hasChild>.
_:bnode1 <http://www.w3.org/2002/07/owl#someValuesFrom> <Person>.
<Parent> <http://www.w3.org/2002/07/owl#equivalentClass> _:bnode1.
Exercise 1.5:
Write the following Turtle triples in RDF/XML syntax: ([] can be used in Turtle for a blank node.)
@prefix owl: <http://www.w3.org/2002/07/owl#>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
[] rdf:type owl:NegativePropertyAssertion;
owl:sourceIndividual :Bill;
owl:assertionProperty :hasDaughter;
owl:targetIndividual :Susan.
RDF/XML:
<?xml version="1.0"?>
<rdf:RDF xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-
ns#">](https://image.slidesharecdn.com/tutorial2-130724035355-phpapp01/85/Tutorial-for-RDF-Graphs-14-320.jpg)


The document provides examples of representing data in RDF formats including RDF/XML, Notation 3, Turtle and triples. It shows how to represent basic statements and relationships between resources as well as more complex data structures like bags, sequences and collections. Examples are given for converting between the different RDF syntaxes and representing graphs in RDF/XML.






























































































