Downloaded 59 times





















![Verify that the shard was added
• db.runCommand({ listshards:1 })
{ "shards" :
[{"_id”: "shard0000”,"host”: ”<hostname>:27018” } ],
"ok" : 1
}](https://image.slidesharecdn.com/introductiontosharding-130225112733-phpapp01/85/Introduction-to-Sharding-27-320.jpg)



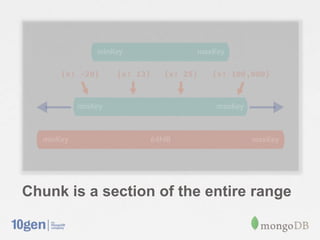





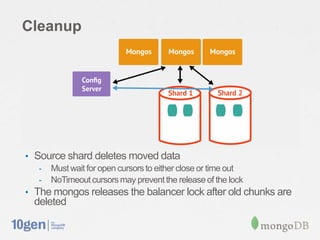





























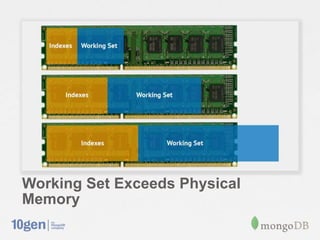
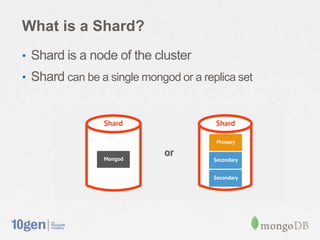
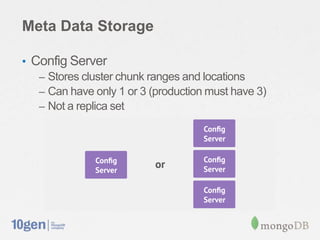
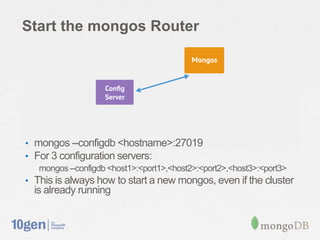
This document provides an overview of MongoDB sharding. It discusses how MongoDB addresses the need for horizontal scalability as data and throughput needs exceed the capabilities of a single machine. MongoDB uses sharding to partition data across multiple machines or shards. The key points are: - MongoDB shards or partitions data by a shard key, distributing data ranges across shards for scalability. - A configuration server stores metadata about sharding setup and chunk distribution. Mongos instances route queries to appropriate shards. - MongoDB automatically splits and migrates chunks as data grows to balance load across shards. - Setting up sharding in MongoDB requires minimal configuration and provides a consistent interface like a single database.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











