01. Summary
1. 2020년12월 발표, Facebook AI
2. ViT를 일부 발전시키고 Distillation 개념 도입
3. Contribution
- CNN을 사용하지 않은 Image Classification
- ImageNet만으로 학습
- Single 8-GPU Node로 2~3일정도만 학습
- SOTA CNN기반 Model과 비슷한 성능 확인
- Distillation 개념 도입
4. Conclusion
- CNN 기반 Architecture들은 다년간 연구가 진행되어 성능 향상
- Image Context Task에서 Transformer는 이제 막 연구되기 시작함
> 비슷한 성능을 보여준다는 점에서 Transformer의 가능성을 보여줌
02. Prerequisites
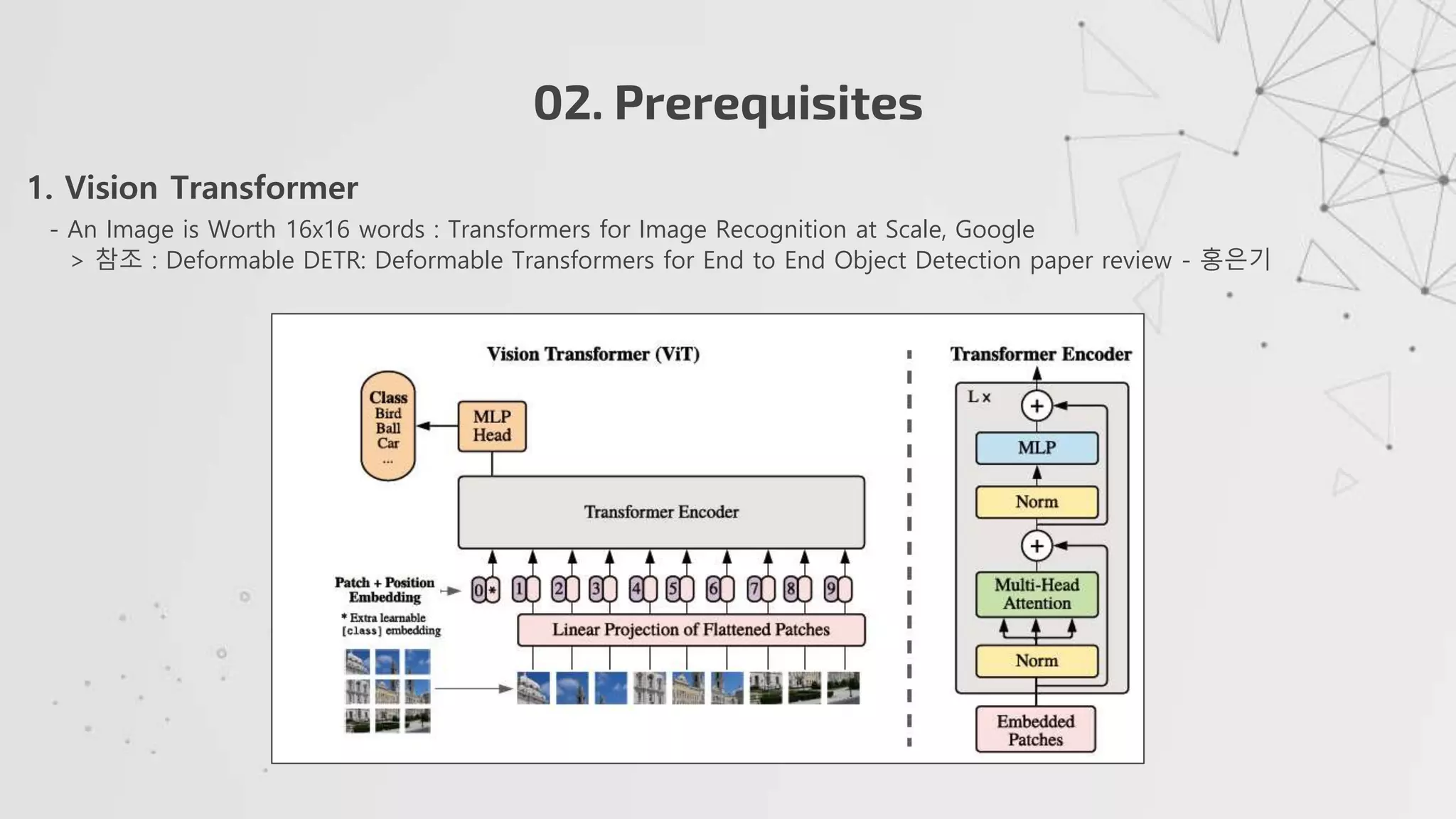
1. VisionTransformer
- An Image is Worth 16x16 words : Transformers for Image Recognition at Scale, Google
> 참조 : Deformable DETR: Deformable Transformers for End to End Object Detection paper review - 홍은기
7.
02. Prerequisites
1. VisionTransformer
- Training Dataset : JFT-300M
- Pre-train : Low Resolution, Fine-tunning : High Resolution
> Position Embedding : Bicubic Interpolation
8.
02. Prerequisites
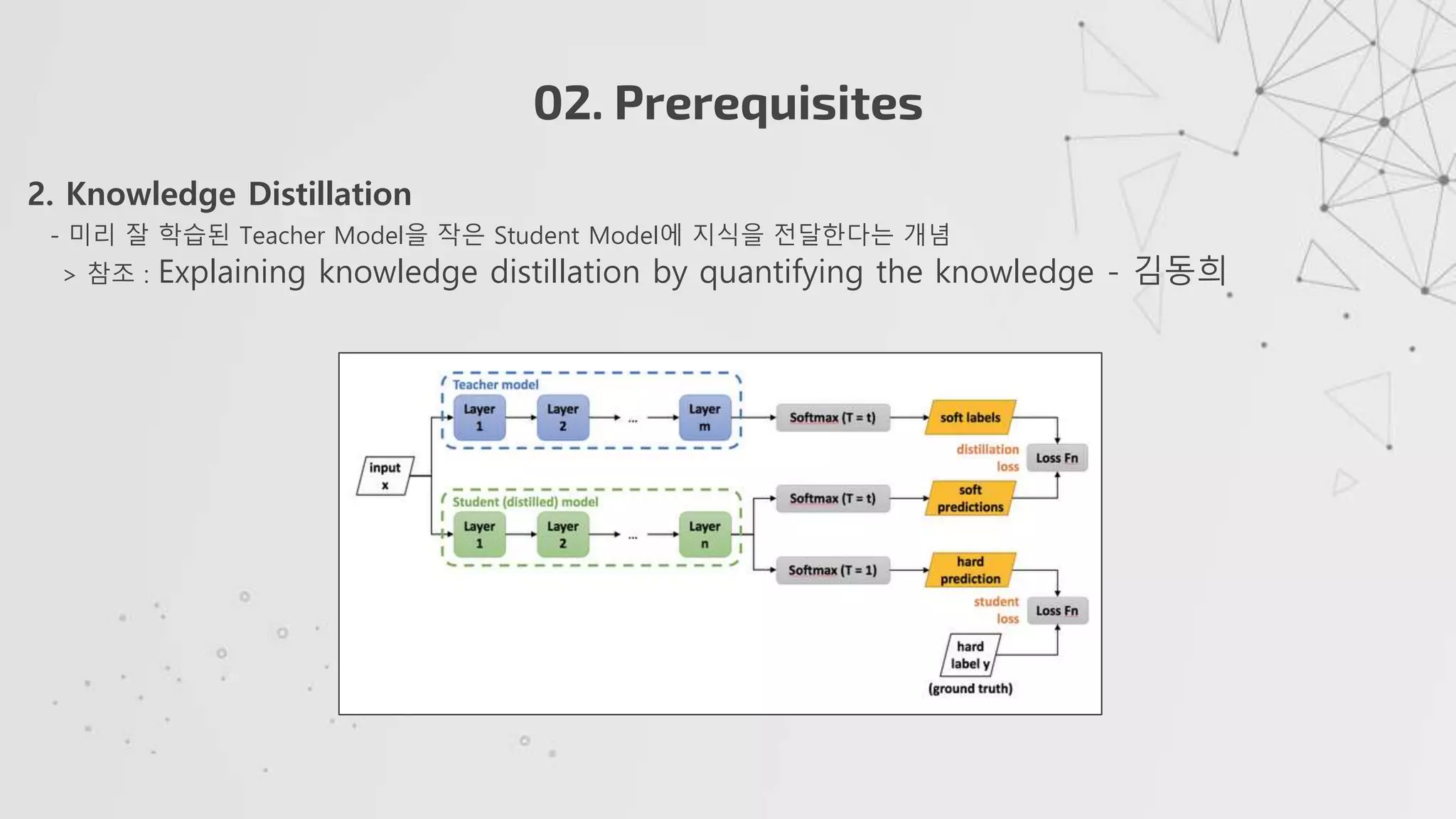
2. KnowledgeDistillation
- 미리 잘 학습된 Teacher Model을 작은 Student Model에 지식을 전달한다는 개념
> 참조 : Explaining knowledge distillation by quantifying the knowledge - 김동희
03. Architecture
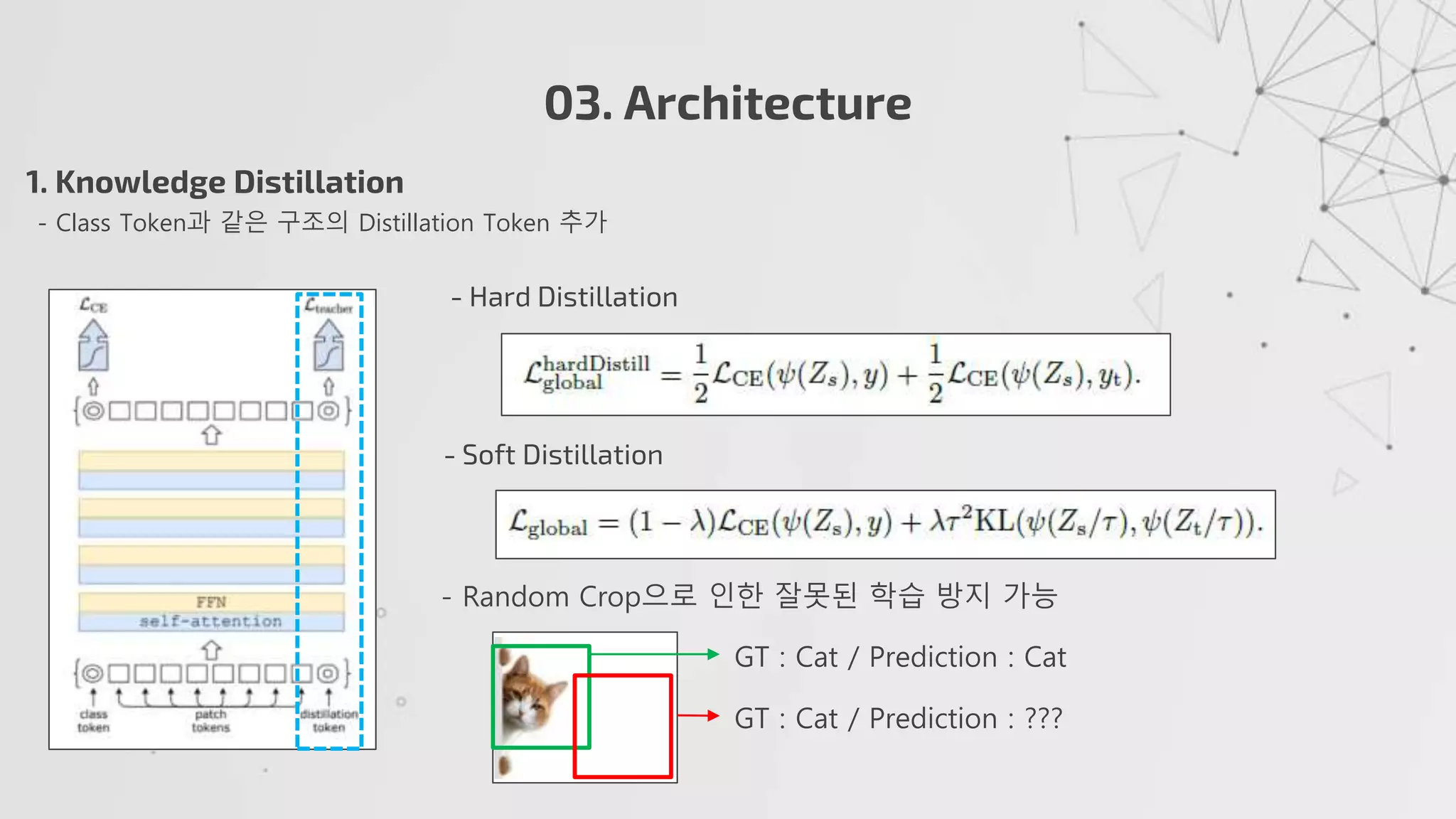
1. KnowledgeDistillation
- Class Token과 같은 구조의 Distillation Token 추가
- Soft Distillation
- Hard Distillation
- Random Crop으로 인한 잘못된 학습 방지 가능
GT : Cat / Prediction : Cat
GT : Cat / Prediction : ???
12.
03. Architecture
2. Bagof Tricks
- 기본적으로, ViT 구조를 그대로 사용 (ViT-B = DeiT-B)
> 기본적인 학습 방법 동일
> Hyper parameter Tunning으로 성능 향상
04. Experiments
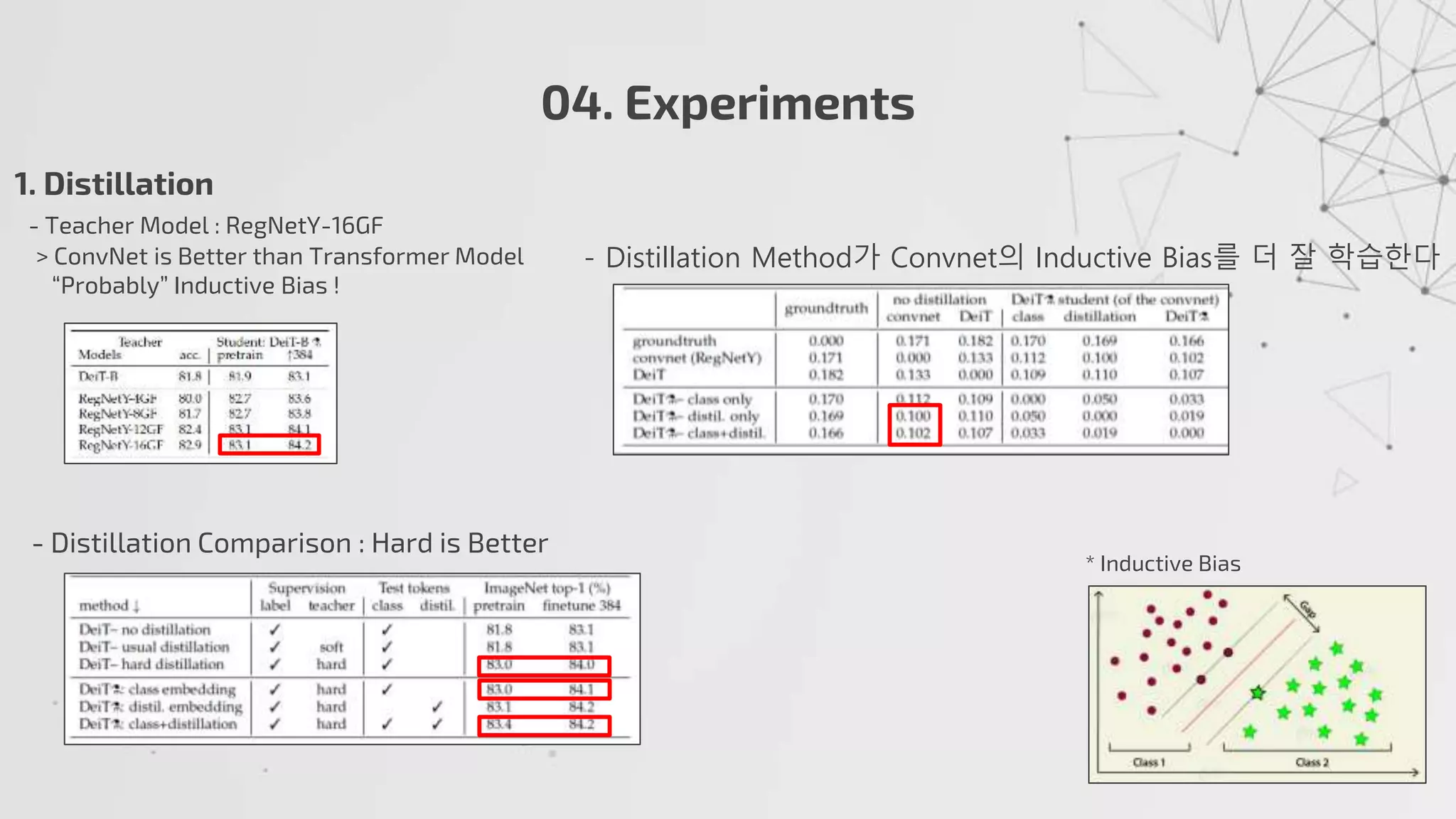
1. Distillation
-Teacher Model : RegNetY-16GF
> ConvNet is Better than Transformer Model
“Probably” Inductive Bias !
- Distillation Comparison : Hard is Better
* Inductive Bias
- Distillation Method가 Convnet의 Inductive Bias를 더 잘 학습한다
16.
04. Experiments
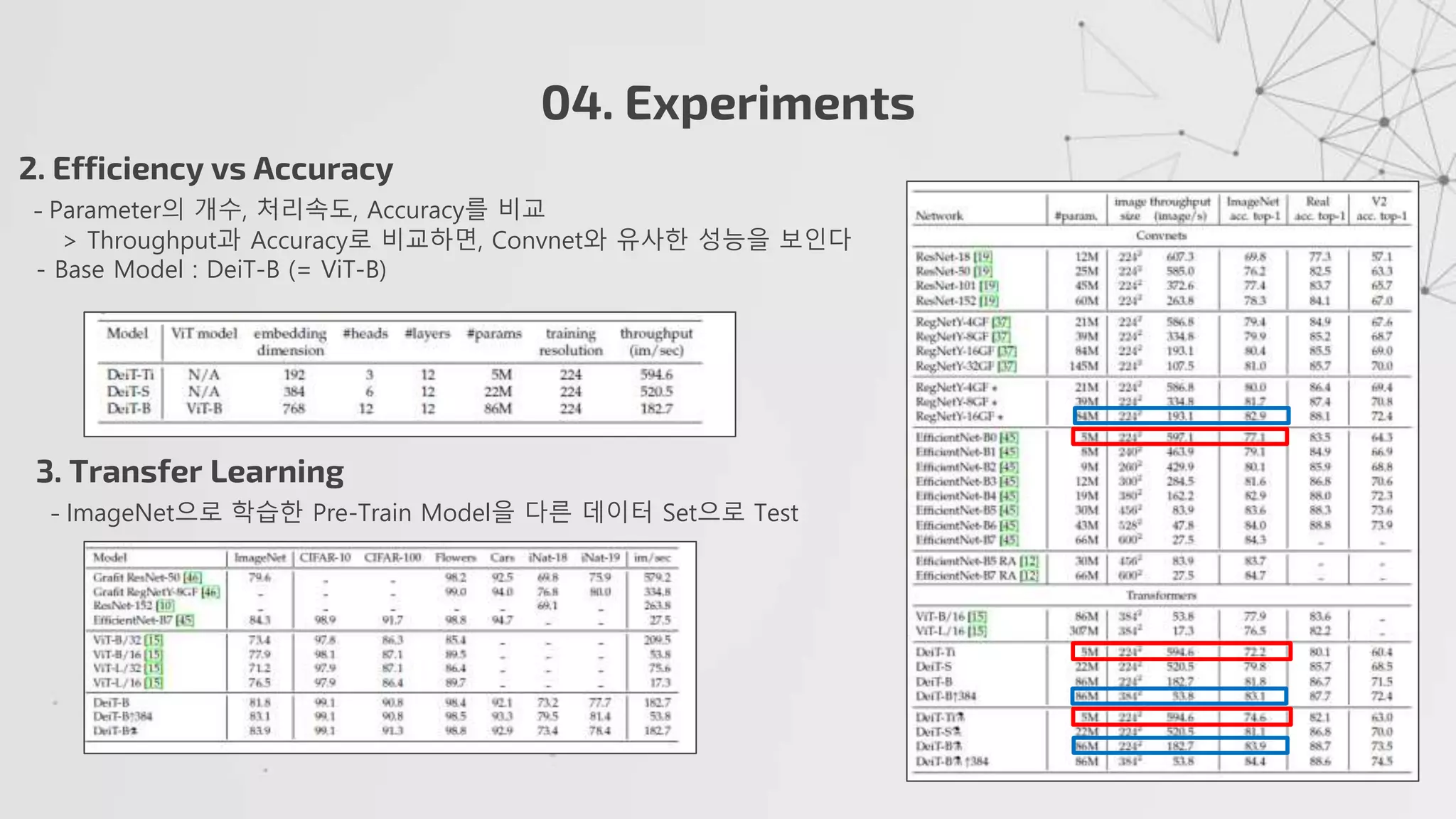
2. Efficiencyvs Accuracy
- Parameter의 개수, 처리속도, Accuracy를 비교
> Throughput과 Accuracy로 비교하면, Convnet와 유사한 성능을 보인다
- Base Model : DeiT-B (= ViT-B)
3. Transfer Learning
- ImageNet으로 학습한 Pre-Train Model을 다른 데이터 Set으로 Test
05. Discussion
1. Contribution
1)Transformer 기반의 ViT Model의 성능 향상 (Convnet X)
2) ViT보다 더 적은 Dataset으로 학습 및 학습속도 향상
3) SOTA Convnet과 유사한 성능 확인
4) 간편한 Knowledge Distillation 방법 제안
2. Opinion
1) 여전히 많은 Epoch 필요 (300~500Epoch)
2) Transformer의 단점이 드러남
> Hyper Parameter에 민감
> Convnet대비 많은 Dataset과 Training 시간이 필요
> 연구단계에서는 많은 연구 가능, 현업에 적용하기에는 어려움
3) Deep Learning 개발 초기단계의 연구 방식
> Quantitative Research (Experiment Theory)
> Experiment의 결과를 충분히 해석하지 못함
3. Conclusion
1) 아직 연구가 많이 필요한 분야
2) 연구 초기단계임에도 불구하고 CNN과 유사한 성능을 나타낸다는 것은
NLP에서의 변화처럼, CNN을 대체할 수 있을 가능성을 확인할 수 있음























































![[PR12] PR-026: Notes for CVPR Machine Learning Sessions](https://cdn.slidesharecdn.com/ss_thumbnails/pr-026notesforcvprmachinelearningsessions-170731034245-thumbnail.jpg?width=640&height=640&fit=bounds)


























