2014 2015 20172016
딥러닝을위한
TensorFlow
Sequence Model
and the RNN API
Open Stack으로
바라보는 클라우드
플랫폼
Machine Learning
In SPAM
Python Network
Programming
Neural Network의
변천사를 통해
바라본 R에서 Deep
Neural Net활용
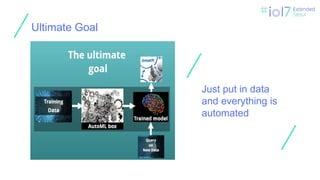
Change the world in
IOT (Falinux)
Game based on the
IOT (KGC)
ㅍ
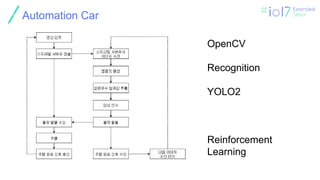
Automation Car
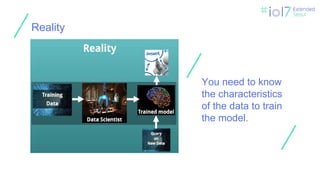
❏ Environmentalfactors
❏ Heavy Rain
❏ Tremendous Mist
❏ Snow
❏ Unexpected Situation
❏ Suddenly a child appears
❏ Dogs and cats run around.
❏ Wild animals appear at a speed of 100 km / h.
Flexible model
needed to
handle
situations
6.
ㅍ
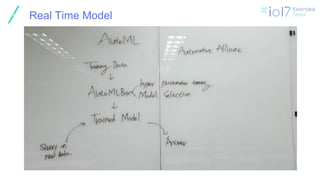
Accracy rate &Model
❏ Most fixed models are used in formal data analysis and natural language
processing.
❏ However, for autonomous vehicles that require precise motion or do not
tolerate errors, you must change the real-time model.
❏ Because it is directly connected with life.
❏ Why have they been commissioning self-driving vehicles for years?
❏ This is because the accuracy of the Reinforcement Model and the
maximization of the Accuracy Rate are required.
ㅍ
YOLO
❏ You onlylook once 최첨단 실시간 물체 탐지 시스템
❏ Detection Mechanizm Improvement
❏ 이전의 Dection 시스템은 분류기나 로컬라이저를 사용하여 감지
❏ YOLO 하나의 신경망을 전체 이미지에 적용
❏ 이 네트워크는 이미지를 영역으로 분할
❏ 각 영역의 경계 상자(bounding box)와 확률을 예측
❏ 테스트 시간에 전체 이미지를 보고 이미지 글로벌 context로 예측
정보를 알려줌
❏ 단일 이미지에 수천개가 필요한 R-CNN과 달리 단일 네트워크 평가로
예측
❏ R-CNN보다 1,000배 이상 빠르며, Fast R-CNN보다 100배 빠름
ㅍ
ㅍ
ㅍ
ㅍ
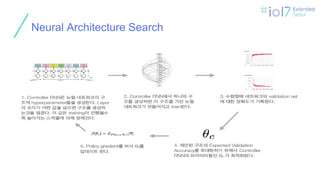
새로운 구조를 gradient
기반으로찾는 Neural
Architecture Search라는
방법을 제안
neural network의 structure와
connectivity를 가변 길이의 configuration
string으로 지정한다는 관찰에서 시작
하나는 CIFAR-10을 사용한 image
classification
다른 하나는 Penn Treebank를 사용한
language modeling
전제조건
https://www.cs.toronto.edu/~kriz/cifar.html
13.
ㅍ
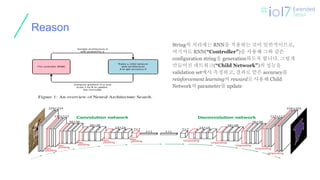
Reason
String의 처리에는 RNN을적용하는 것이 일반적이므로,
여기서도 RNN(“Controller”)을 사용해 그와 같은
configuration string을 generation하도록 합니다. 그렇게
만들어진 네트워크(“Child Network”)의 성능을
validation set에서 측정하고, 결과로 얻은 accuracy를
reinforcement learning의 reward로 사용해 Child
Network의 parameter를 update
ㅍ
ㅍ
ㅍ
ㅍ
맨 아래 부분Neural
Architecture Search로
만든 구조들이
DenseNet을 비롯한
인간이 설계한
state-of-the-art에
근접하는 성능을
보이는 것을 볼 수
있습니다.
Learning Convolutional
Architectures for CIFAR-10
20.
ㅍ
ㅍ
ㅍ
ㅍ
language modeling task에
적용할RNN cell을 생성
[add, elem_mult] 등의
combination method와
[identity, tanh, sigmoid, relu]
등의 activation method를
조합해서 tree의 각 node를
표현
실험에는 400개의 CPU를
사용했고, 총 15,000개의 child
network을 만들어 평가했다고
합니다. 실험 결과로 만들어진
RNN cell은 LSTM 대비 0.5
BLEU의 향상
Learning Recurrent Cells for Penn
Treebank
21.
ㅍ
Conclusion
이 논문에서는 신경네트워크 구조를 구성하기 위해 반복적 인 신경망을 사용하는 아이디어 인 신경 구조
검색 (Neural Architecture Search)을 소개
반복적인 네트워크를 컨트롤러로 사용함으로써 우리의 방법은 가변적이어서 가변 길이 아키텍처 공간을
검색 할 수 있습니다.
우리의 방법은 매우 까다로운 벤치 마크에서 강한 경험적 성과를 보이며 훌륭한 신경 네트워크 아키텍처를
자동으로 찾는 새로운 연구 방향을 제시합니다.
이 논문에서 사용한 코드는 GitHub TensorFlow Models 페이지에 공개될 예정이며, 앞에서 만든 RNN cell은
NASCell이라는 이름으로 TensorFlow API에 추가되었습니다.
ㅍ
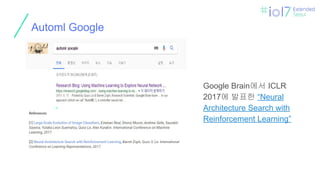
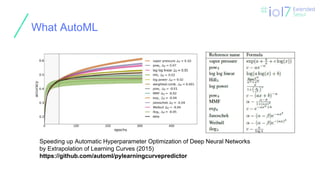
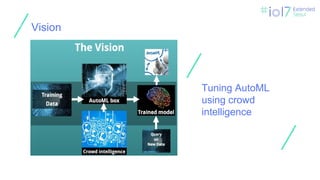
What AutoML
Speeding upAutomatic Hyperparameter Optimization of Deep Neural Networks
by Extrapolation of Learning Curves (2015)
https://github.com/automl/pylearningcurvepredictor
ㅍ
Data
❏ 30 datasets (5 per rounds)
❏ Various domaines: pharma, medicine, marketing, finance...
❏ Divers formats: text, image, video, speech...
❏ Participants don't know about the domain nor the format
❏ Given: dense or sparse matrix
❏ Numerical, categorical, binary
❏ Missing values or not
❏ Noisy or not
❏ Various proportion of Large test sets, ensuring statistical significance
32.
ㅍ
Data
❏ Binary classification
❏Multi-class classification (10 to 100's)
❏ Multi-labels classification
❏ Regression/Prediction
❏ Difficulty = Medium to hard, 10 to 20% error at best
❏ Time budget = Limited
❏ Computational resources & memory = Fixed
33.
ㅍ
AutoML strategies
❏ Bayesianapproache for Hyper Parameters (HP) optimization
❏ Global approches including in search space:
HP, models, features engineering, data pre-processing
❏ Ensemble methods
❏ Meta-learning
❏ Memory & time management
ㅍ
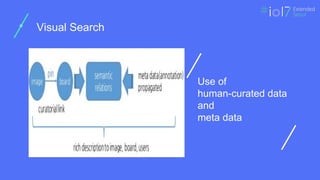
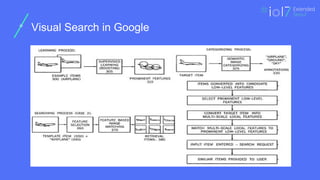
Visual Search
❏ ImageRepresentation and Features
❏ Incremental Fingerprinting Service
❏ Search Infrastructure
43.
ㅍ
Image Representation andFeatures
❏ Extract various features from image
❏ Local feature
❏ Deep feature (CNN)
❏ AlexNet and VGGNet
❏ Binarized feature : for efficiency
❏ Compared using Hamming distance
❏ Salient color signatures
44.
ㅍ
ㅍ
ㅍ
ㅍ
페이지
타이틀
ㅍ
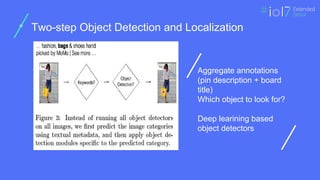
Two-step Object Detectionand Localization
Aggregate annotations
(pin description + board
title)
Which object to look for?
Deep learining based
object detectors
45.
ㅍ
ㅍ
ㅍ
ㅍ
페이지
타이틀
ㅍ
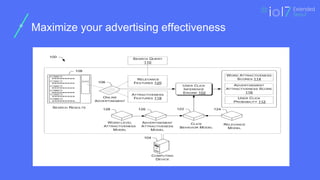
Click Prediction
CUR /CTR is often used
in search ranking,
recommendation
systems, and ads
targeting.
Click Through Rate (ratio) 광고 노출횟수
대비 클릭 수
Click User Rate
How to find out which images in Visual content are most interested in users
46.
ㅍ
Click Prediction
❏ CNNhas recently become the most dominant approach to semantic
prediction
❏ However, many data sets and time are required to learn
❏ Fine-tuning pre-made models
❏ Compared with traditional computer vision techniques (baseline)
❏ PHOW + SVM
❏ PHOW (Pyramid Histogram of Visual Word)
❏ SVM (Support Vector Machine)













![ㅍ
ㅍ
ㅍ
ㅍ
language modeling task에
적용할 RNN cell을 생성
[add, elem_mult] 등의
combination method와
[identity, tanh, sigmoid, relu]
등의 activation method를
조합해서 tree의 각 node를
표현
실험에는 400개의 CPU를
사용했고, 총 15,000개의 child
network을 만들어 평가했다고
합니다. 실험 결과로 만들어진
RNN cell은 LSTM 대비 0.5
BLEU의 향상
Learning Recurrent Cells for Penn
Treebank](https://image.slidesharecdn.com/io17exautomlautodraw-170701102057/85/Io17ex-automl-autodraw-20-320.jpg)































![[224] 번역 모델 기반_질의_교정_시스템](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)


![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Tf2017] day3 jwkang_pub](https://cdn.slidesharecdn.com/ss_thumbnails/tf2017day3jwkangpub-171028122627-thumbnail.jpg?width=640&height=640&fit=bounds)









































