Abstract
120만개 이미지를분류하는 ImageNet LSVRC-2012 Contest에서 우리가 만든 모
델이 기존에 가장 좋은 성능을 보였던 모델보다 더 좋은 성능을 보임.
Network Model
• 60million parameter와 65,000 neurons를 가진 신경망은 5개의 convolutional layers와
max-pooling layers 그리고 3개의 fully-connected layers와 1000개의 softmax로 구성함.
훈련을 빠르게 시키기 위해 non-saturating neurons를 사용하고
더 효율적인 convolution 연산을 구현함.
GPU Fully-connected layer에 overfitting을 줄이기 위해 dropout을 적용함.
ILSVRC-2012 competition에서 error rate 15.3%를 기록하며 우승함.
2
4.
1. Introduction
Objectsrecognition은 아직도 어려움을 많이 갖고 있음.
Object recognition을 학습 시키기 위해서는 많은 수의 dataset이 더 필요한데 최
근에 많은 dataset(LabelMe, ImageNet 등)들이 등장함.
CNN을 이용하여 Large dataset에 고화질 이미지를 적용하기에는 여전히 비용이
비싸지만 GPU가 좋아지고 Dataset들이 충분히 labeled 된 예들을 많이 갖고 있
어서 처리가 수월해짐.
이 논문의 기여 내용
• CNN을 이용하여 ImageNet Data를 훈련시켰고 최고의 결과를 보임.
• 최적화 된 2D Convolution GPU 구현.
• 훈련 시간을 줄이고 성능 개선을 위해 특별한 feature 사용.
• Convolution Layer를 제거해보면서 depth의 중요성을 보임.
3
5.
2. The Dataset
ImageNet
• 22000 카테고리를 가진 15 million의 labeled images의 Dataset임.
• 이미지는 Web에서 모아져 왔고 Amazon’s Mechanical Turk crowd-sourcing tool를
사용한 human labelers에 의해 labeled 되어짐.
• 매년 ImageNet-Large-Scale Visual Recognition Challenge(ILSVRC)를 개최함.
ILSVRC
• 대략 1000개 카테고리마다 1000개의 이미지를 사용함.
1.2 million training images, 50,000 validation images, 150,000 testing images.
• Error-rate를 측정하기 위해 top-1 그리고 top-5를 사용함.
Top-1 : correct class와 모델에서 예측한 top class 같은가를 비교함.
Top-5 : correct class와 모델에서 예측한 가장 높은 5가지 class 중에 같은게 있는가를 비교함.
Our system
• 256 * 256 down sampling
• 이미지의 중앙의 256 * 256 cropping
• 각 픽셀마다 이미지의 평균값으로 뺌.
4
6.
3. The Architecture(1)
3.1 ReLU Nonlinearity
• 기존의 신경망 활성 함수로서 많이 사용되었던
tanh(x) or sigmoid(x) 함수는 트레이닝 시간이
올래 걸림.
tanh(x) , sigmoid(x)가 트레이닝 시간이 긴 이유는
saturating nonlinearity 특성을 갖고 있기 때문임.
• 이런 문제를 해결하기 위해 Rectified Linear
Units(ReLUs)가 나옴.[Hinton]
ReLU는 non-saturating nonlinearity
(f(x) = max(0,x).
• 오른쪽 그림은 error-rate가 25%가 될 때까지의
걸린 epochs를 보여준 그래프임.
ReLU가 tanh보다 6배 더 빠르게 학습률을 달성함.
5
7.
3. The Architecture(2)
3.2 Training on Multiple GPUs
• 1.2 million 이미지를 처리하기에는 GPU 하나로는 부족했음.(GTX580 메모리 3GB).
• 커널의 절반을 나눠서 GPU 2개로 처리하였음.
• GPU 1개보다 처리 시간이 덜 걸렸음.
3.3 Local Response Normalization
• ReLU는 좋은 특징 중 하나는 input normalization이 필요로 하지 않음.
• 그러나 Local Normalization은 Generalization을 올리기 위해 좋음.
Normalization 적용 후 ReLU function 적용함.
식은 아래와 같음.
N : 해당 레이어에 총 커널 수
i : 커널 인덱스
𝑎 𝑥,𝑦
𝑖
: i 커널에서의 x, y 위치의 값.
K, 𝛼, 𝛽 Hyper-parameters : validation set을 통해 값을 찾음.
결과적으로 이것을 적용했을 때 error-rate가 top-1에서는 1.4%
그리고 top-5에서는 1.2% 줄일 수 있었음.
CIFAR-10 dataset에서 CNN에 적용해본 결과 Normalization 없을 때는 13%,
있을 때는 11% Error-rate보임.
6
8.
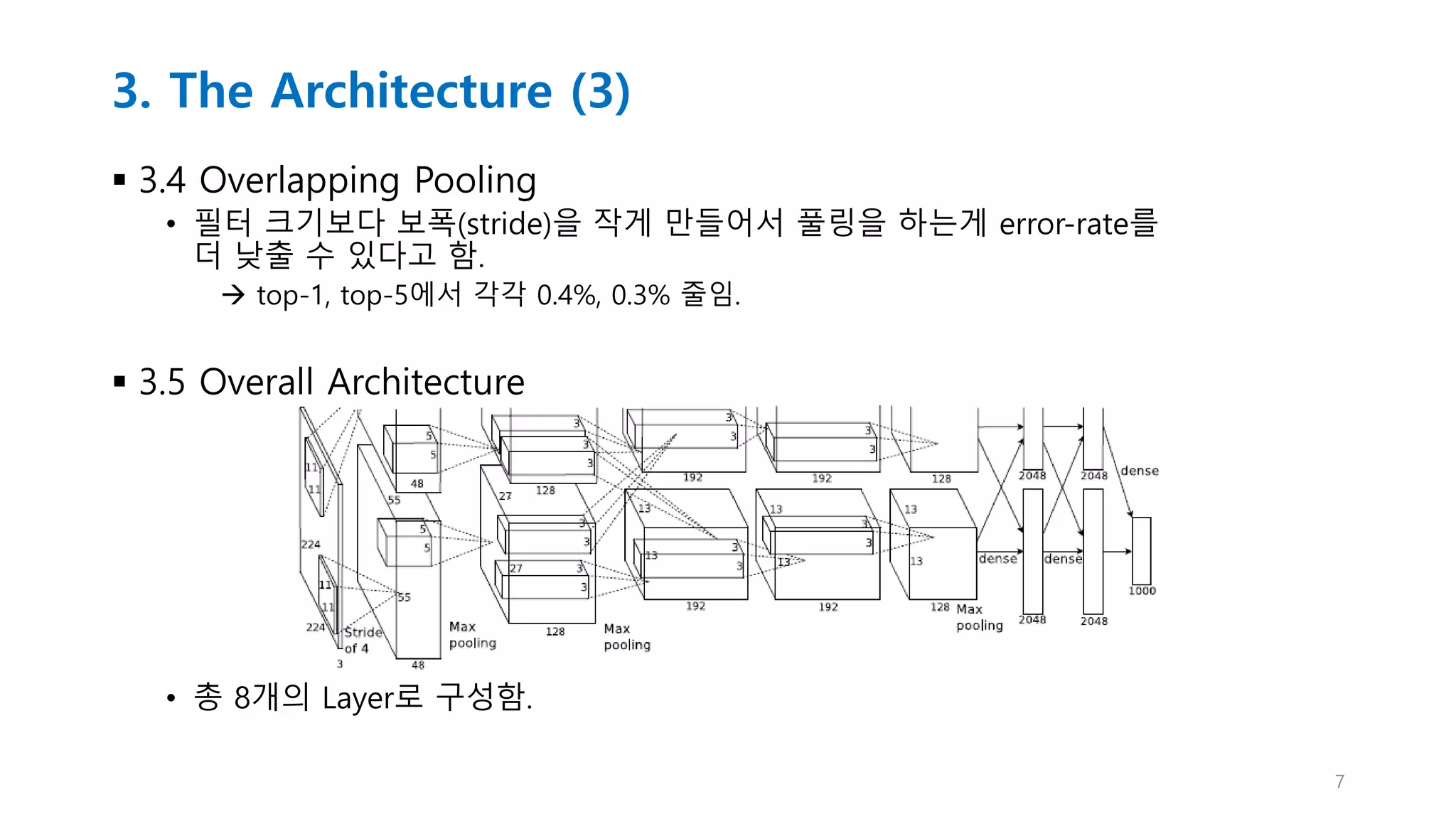
3. The Architecture(3)
3.4 Overlapping Pooling
• 필터 크기보다 보폭(stride)을 작게 만들어서 풀링을 하는게 error-rate를
더 낮출 수 있다고 함.
top-1, top-5에서 각각 0.4%, 0.3% 줄임.
3.5 Overall Architecture
• 총 8개의 Layer로 구성함.
7
9.
3. The Architecture(4)
• 5개의 Convolutional과 3개의 Fully connected layers로 구성됨.
• 1000 class를 분류하기 위한 Softmax가 마지막에 output으로 있음.
• 2, 4, 5 layer는 각각 나눠진 GPU 처리 결과를 나눠서 처리함.
과정
• 1 layer에서 224*244*3 input image를 96 kernals 11*11*3 filtering함.(stride 4)
• Response-normalized(1,2 layer에서만)와 ReLU, pooling 작업을 함.
• 2 layer에서 256 kernals 5*5*48로 filtering 후 위와 동일한 과정 거침. (stride 2)
• 3,4,5 layer는 pooling과 normalization 과정 없이 conv 처리하고
fully connected layer를 거쳐서 softmax를 통해 분류를 하게 됨.
8
10.
4. Reducing Overfitting
4.1 Data Augmentation
• Label-preserving transformation
Translation, Horizontal reflection
• Altering the intensities of the RGB channels
Training image에 PCA 적용함.
+
- P : 공분산 행렬의 i번째 고유벡터, 𝜆 : i번째 공유치, 𝛼 : 랜덤한 가중치
4.2 Drop out
• Hidden Layer에서 랜덤하게 몇 개의 Neuron들만 사용하여 학습시키는 방법임.
이 논문에서는 50%의 Neuron만 사용함.
50% Neuron들은 Output값을 0으로 만듦.
• Drop out된 Neuron들은 forward pass하거나 backpropagation을 하지 않음.
• 네트워크가 컸을 때 훈련시키는 시간을 단축시킬 수 있음.
• Drop out을 사용하지 않았을 경우 상당한 overfitting이 발생함.
9
11.
5. Details oflearning
Stochastic gradient descent(SGD)를 사용함.
• Batch size 128
momentum 0.9, weight decay 0.0005
• 작은 Weight decay 값이 모델의 training error를 줄여줌.
Update rule for weight w
Weight들은 zero-mean Gaussian distribution를 사용하여 초기화함.
• 표준편차 0.01
2,4,5 Layer와 Fully-connected layer에서 bias는 1로 초기화 나머지는 0으로 초기
화함.
Learning rate는 0.01로 초기화함.
1.2 million images를 90번 훈련시켰고 5~6일 걸림.
10
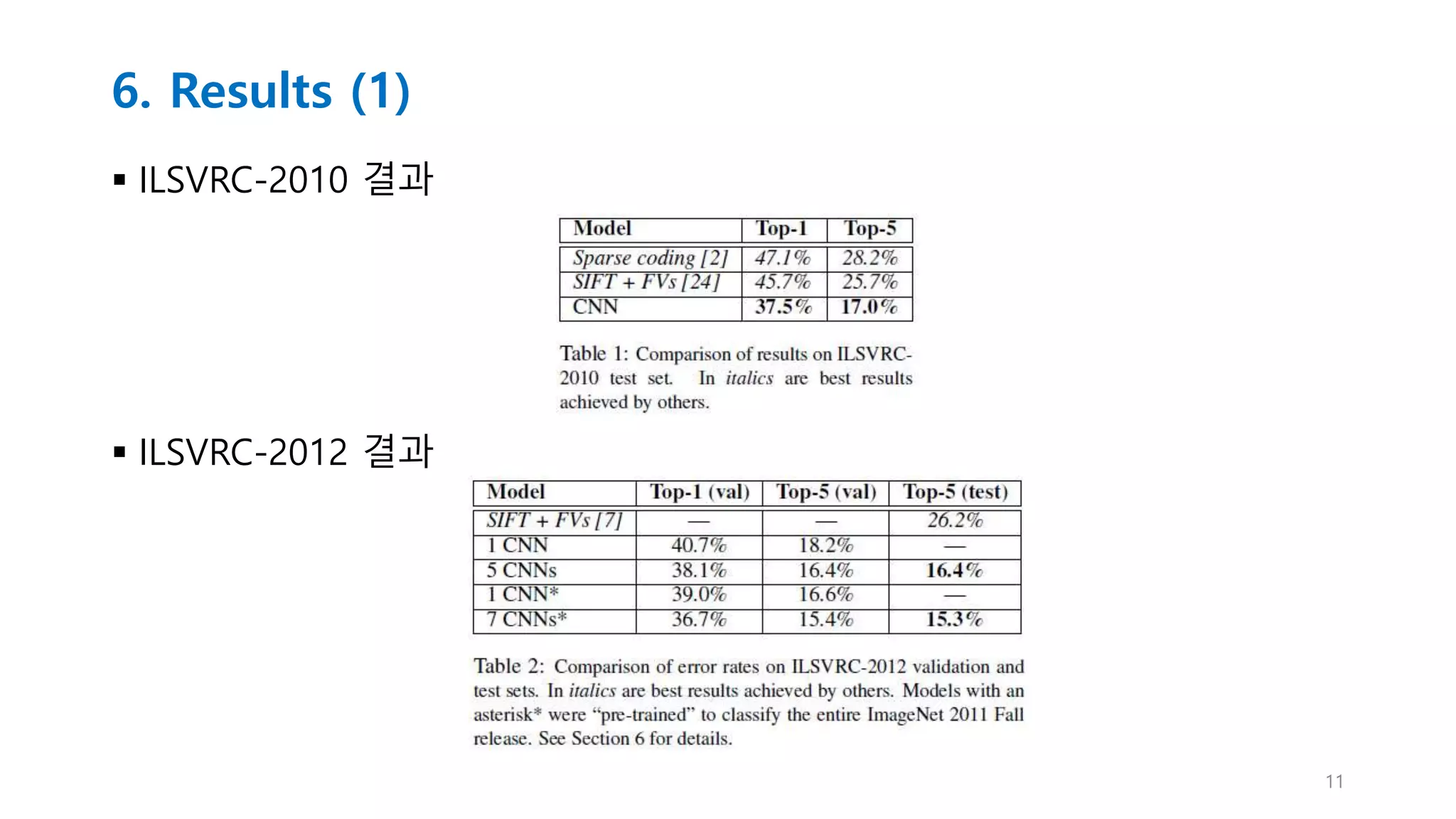
6. Results (2)
Qualitative Evaluations
• Figure3
위에 3줄은 GPU1에서의 kernal
아래 3줄은 GPU2에서의 kernal임.
GPU1에서의 kernal은 color-agnostic하고
GPU2에서의 kernal은 color-specific함.
• Figure4
왼쪽은 8개의 이미지에서 예측값이 가장
높은 5개 Label을 보여주고 있음.
- mite 중앙과 멈에도 인지함.
- Grille, cherry 애매함.
오른쪽은 첫번째 열은 test image이고
나머지는 test image와 유사한
training image임.
- Feature vector들 사이에 유클리디안
거리가 가까운거.
- 훈련 시에 auto-encode를 쓰면 더 효율적임.
12
14.
7. Discussion
우리의모델이 이전에 가장 좋았던 성능의 모델 기록을 깸.
우리 모델에서 중간 레이어를 제거하면 성능이 2% 떨어지는 것을
확인함(top-1 기준). 즉, 모델의 깊이는 중요함.
궁극적으로 우리는 비디오 시퀀스에서 매우 크고 깊은 convolutional nets
을 사용하길 원함.
13





![3. The Architecture (1)
3.1 ReLU Nonlinearity
• 기존의 신경망 활성 함수로서 많이 사용되었던
tanh(x) or sigmoid(x) 함수는 트레이닝 시간이
올래 걸림.
tanh(x) , sigmoid(x)가 트레이닝 시간이 긴 이유는
saturating nonlinearity 특성을 갖고 있기 때문임.
• 이런 문제를 해결하기 위해 Rectified Linear
Units(ReLUs)가 나옴.[Hinton]
ReLU는 non-saturating nonlinearity
(f(x) = max(0,x).
• 오른쪽 그림은 error-rate가 25%가 될 때까지의
걸린 epochs를 보여준 그래프임.
ReLU가 tanh보다 6배 더 빠르게 학습률을 달성함.
5](https://image.slidesharecdn.com/imagenetclassificationwithdeepconvolutionalneuralnetworks2-171204122829/75/Image-net-classification-with-deep-convolutional-neural-networks-6-2048.jpg)









![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)



































![[Paper Review] Visualizing and understanding convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/visualizingandunderstandingconvolutionalnetworks-171116075511-thumbnail.jpg?width=640&height=640&fit=bounds)







