This document discusses the role of tensors in large-scale machine learning, highlighting their ability to encode multi-dimensional data such as images and videos. It explores various applications, including visual question answering, long-term forecasting, and topic modeling, while emphasizing the advantages of tensor algebra over traditional matrix methods. Additionally, it introduces Amazon SageMaker as a platform for efficient machine learning training and inference.
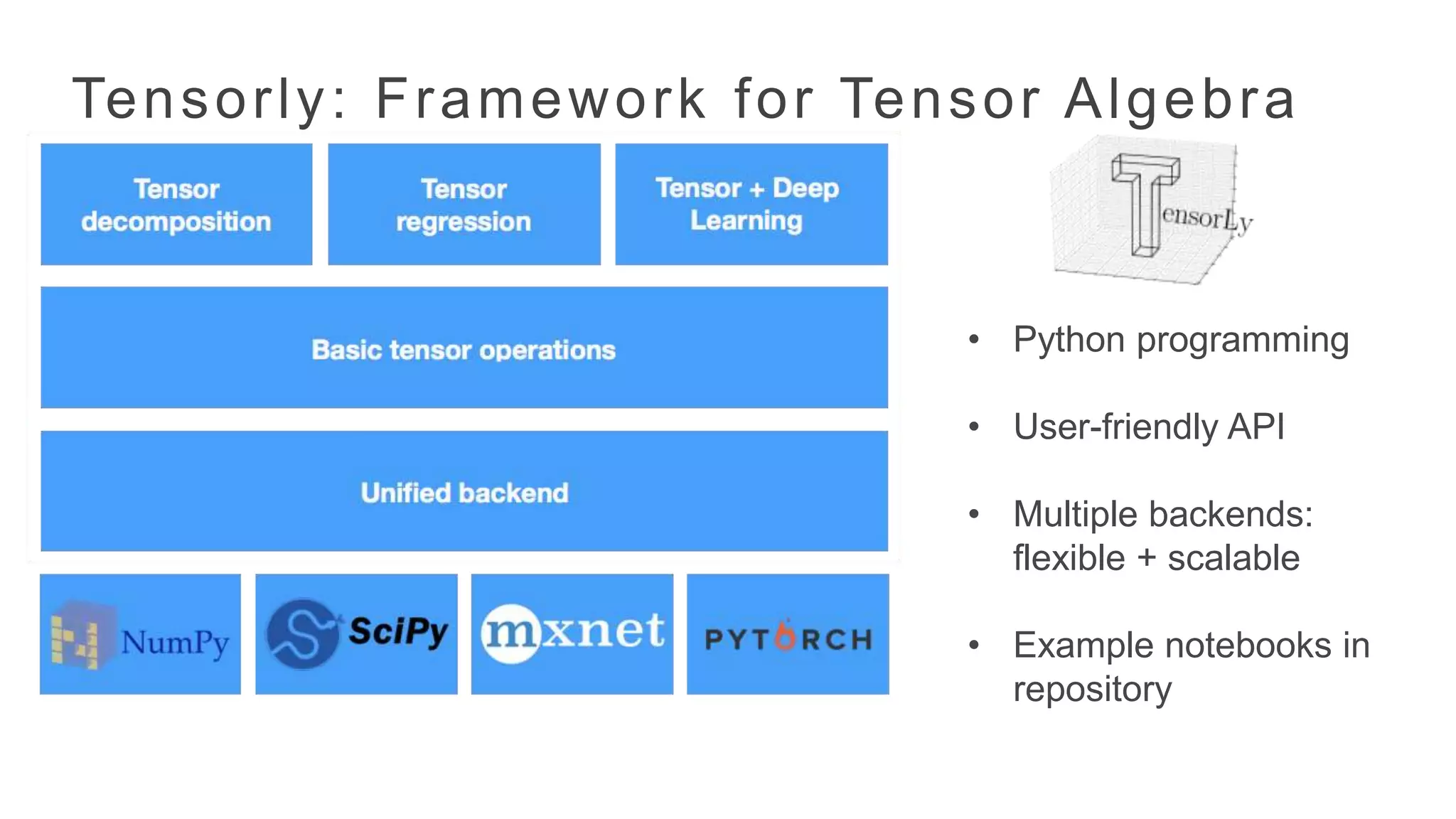
Tensorly: Framework forTensor Algebra
• Python programming
• User-friendly API
• Multiple backends:
flexible + scalable
• Example notebooks in
repository
15.
Tensorly with Pytorchbackend
import tensorly as tl
from tensorly.random import tucker_tensor
tl.set_backend(‘pytorch’)
core, factors = tucker_tensor((5, 5, 5),
rank=(3, 3, 3))
core = Variable(core, requires_grad=True)
factors = [Variable(f, requires_grad=True) for f in factors]
optimiser = torch.optim.Adam([core]+factors, lr=lr)
for i in range(1, n_iter):
optimiser.zero_grad()
rec = tucker_to_tensor(core, factors)
loss = (rec - tensor).pow(2).sum()
for f in factors:
loss = loss + 0.01*f.pow(2).sum()
loss.backward()
optimiser.step()
Set Pytorch backend
Attach gradients
Set optimizer
TuckerTensor form
16.
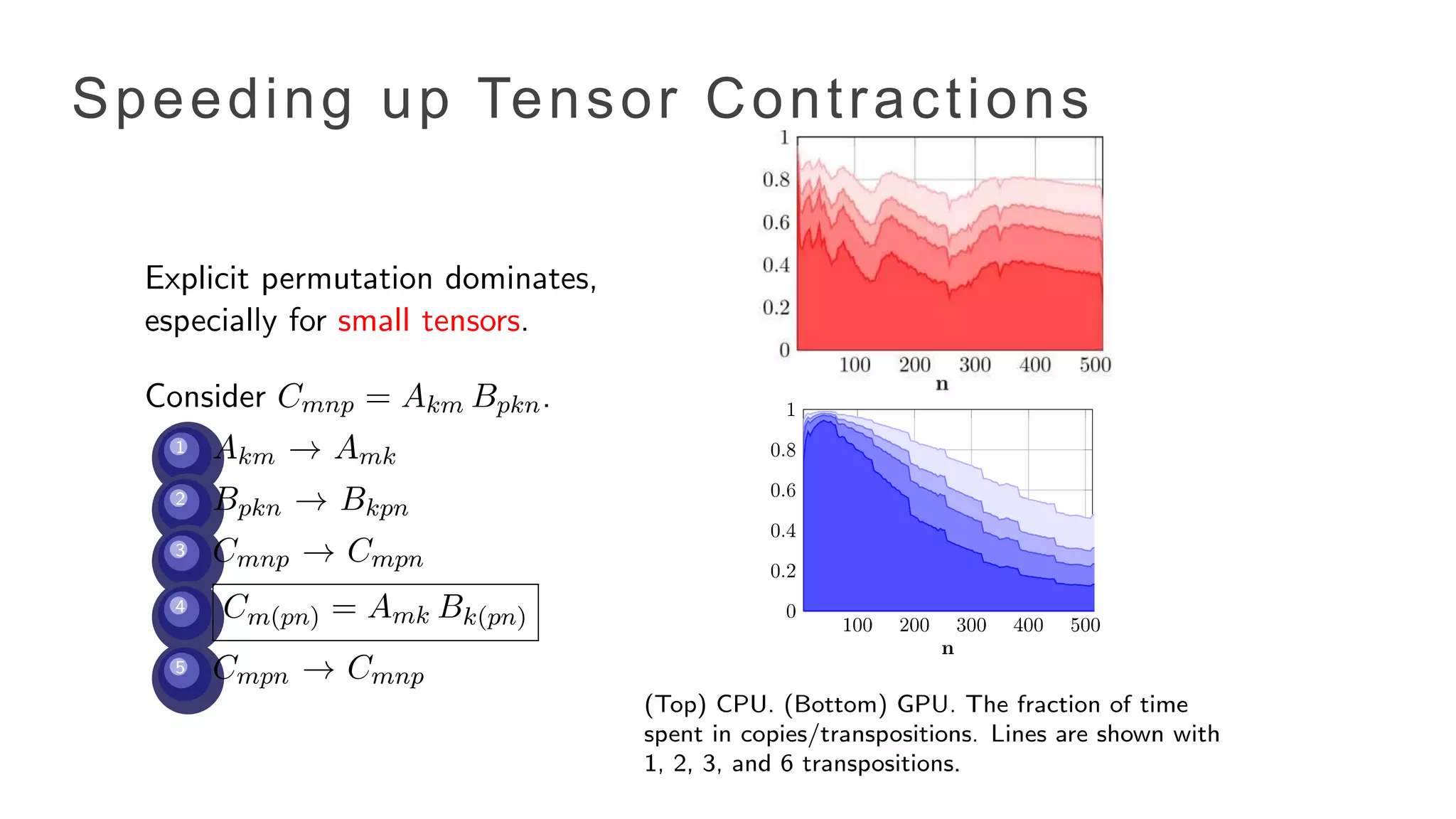
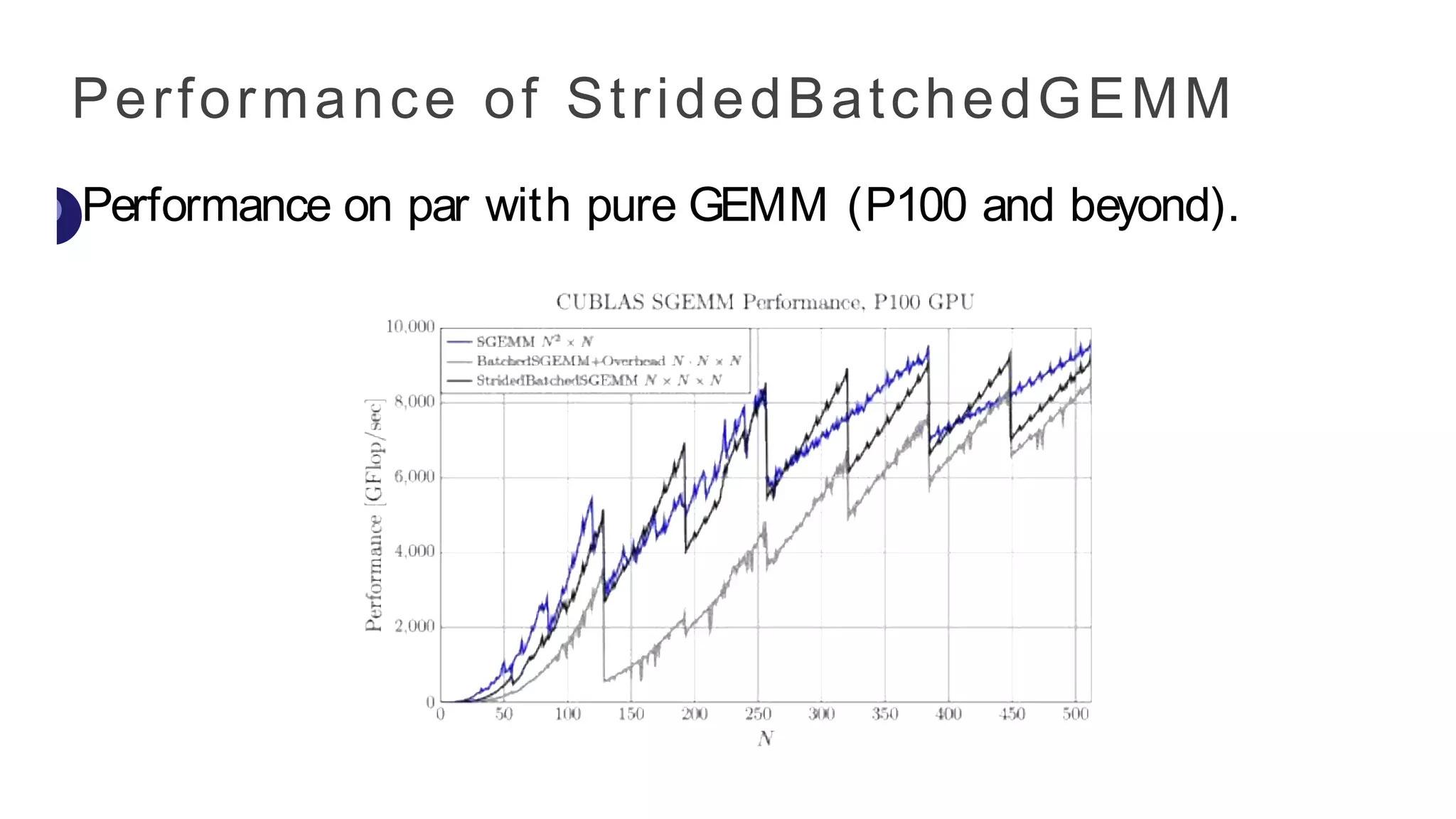
Speeding up TensorContractions
h t t p s : / / g i t h u b . c o m / a w s l a b s / a m a z o n - s a g e m a k e r - e x a m p l e s
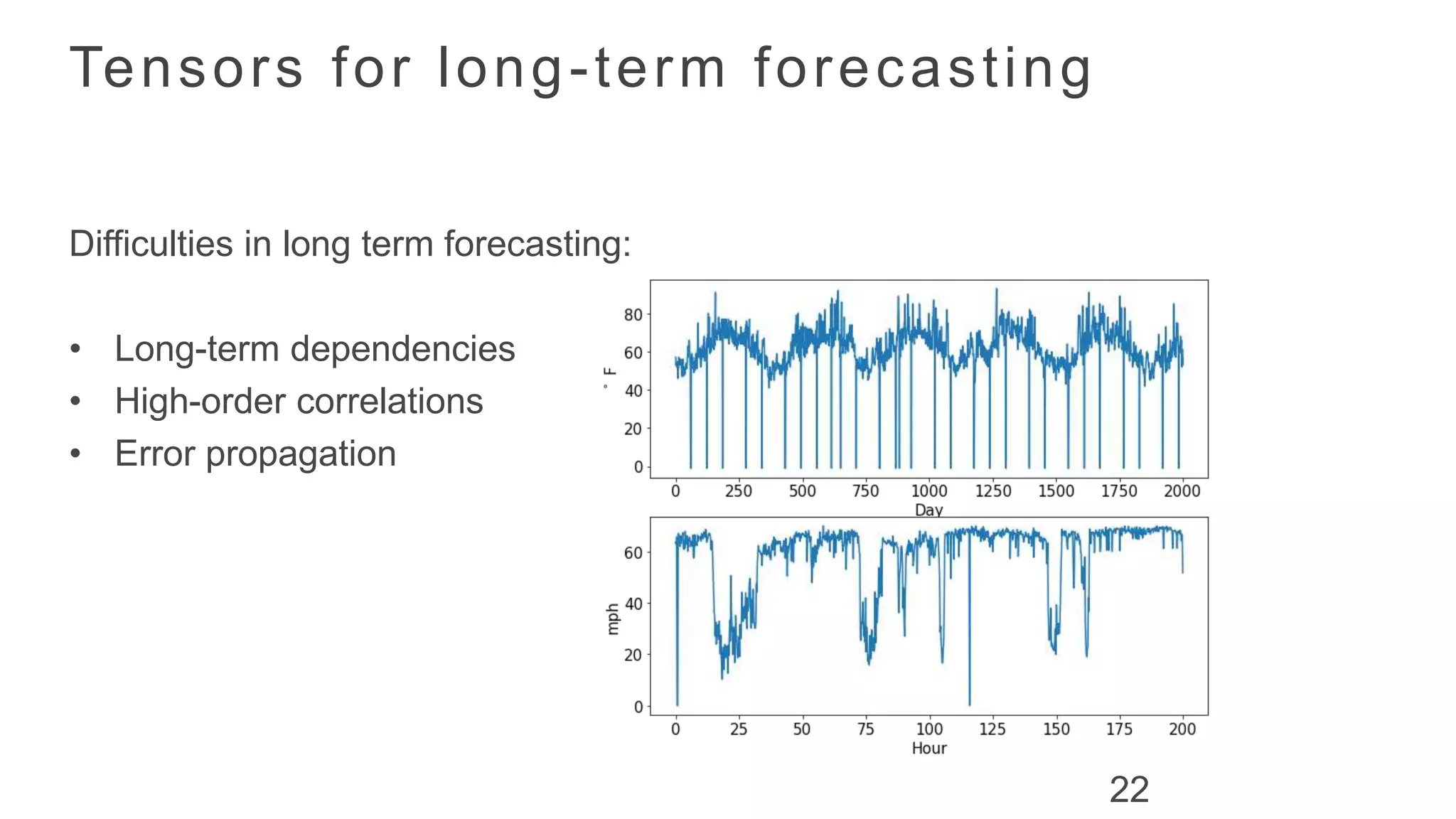
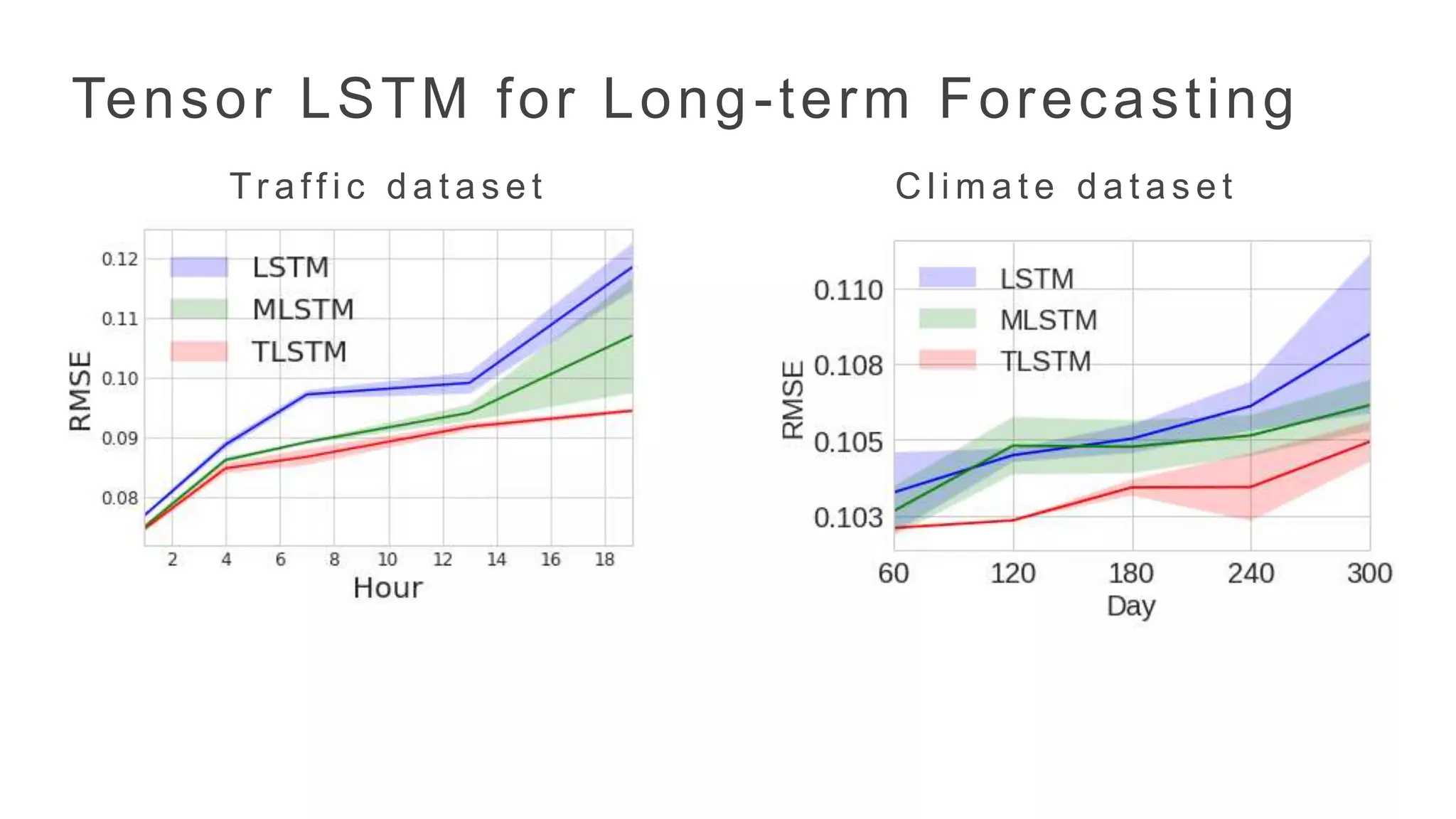
C l im a t e d a t a s e tTr a ff i c d a t a s e t
Tensor LSTM for Long-term Forecasting
28.
Approximation Guarantees
Theorem 1[Yu et al 2017]: Let the state transition function 𝑓 ∈ ℋ𝜇
𝑘
be a
Hölder continuous, with bounded derivatives up to order k and finite
Fourier magnitude distribution 𝐶𝑓. Then a single layer Tensor Train RNN
can approximate 𝑓 with an estimation error of 𝜀 using with ℎ hidden units:
ℎ ≤
𝐶𝑓
2
𝜀
𝑑 − 1
𝑟 + 1 − 𝑘−1
𝑘 − 1
+
𝐶𝑓
2
𝜀
𝐶 𝑘 𝑝−𝑘
Where 𝑑 is the size of the state space, 𝑟 is the tensor-train rank and 𝑝 is
the degree of high-order polynomials i.e., the order of tensor.
• Easier to approximate if function is smooth
• Polynomial interactions are more efficient
Long-term Forecasting usingTensor-Train RNNs by R.Yu, S. Zheng, A,Y.Yue, 2017.
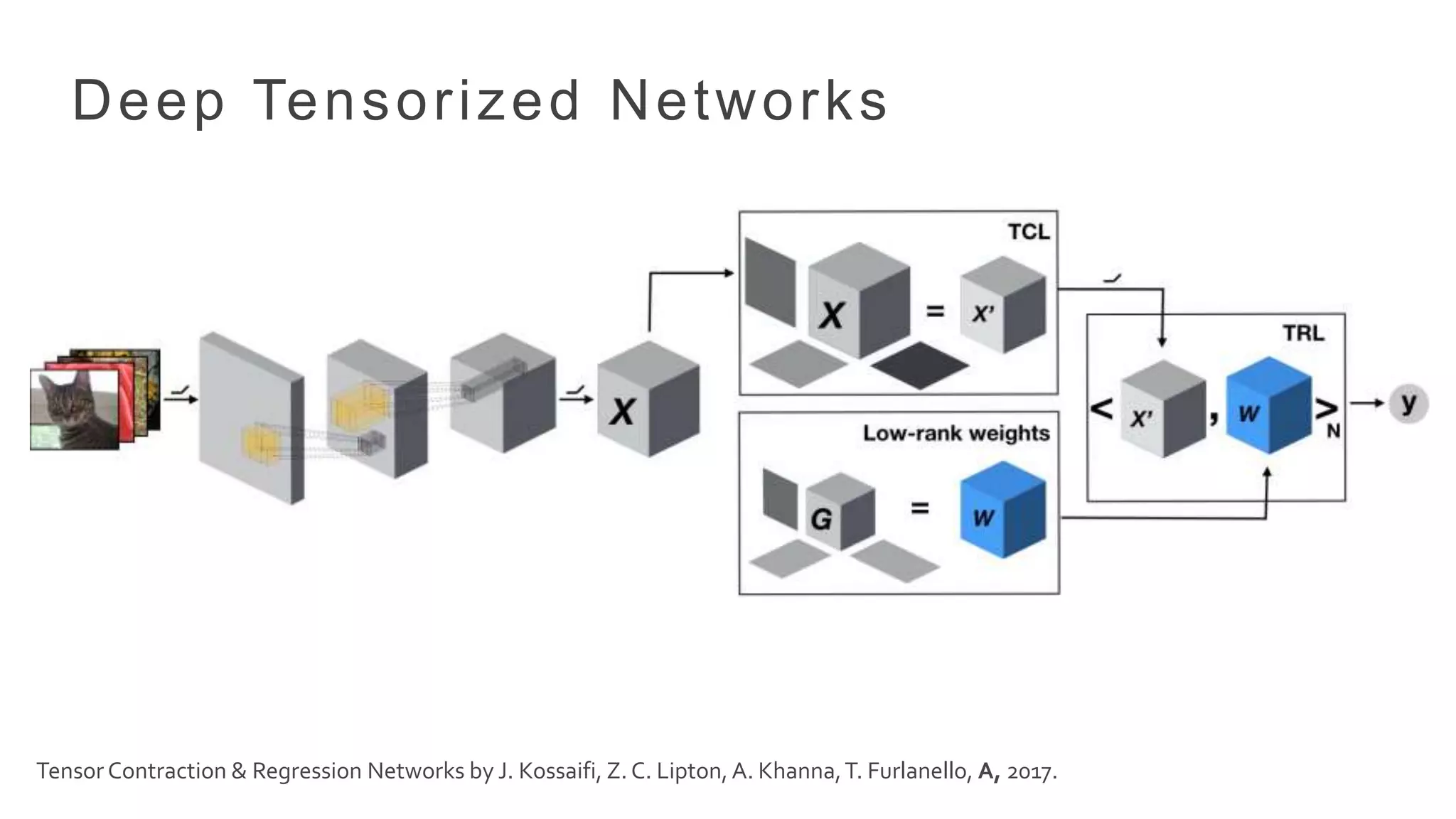
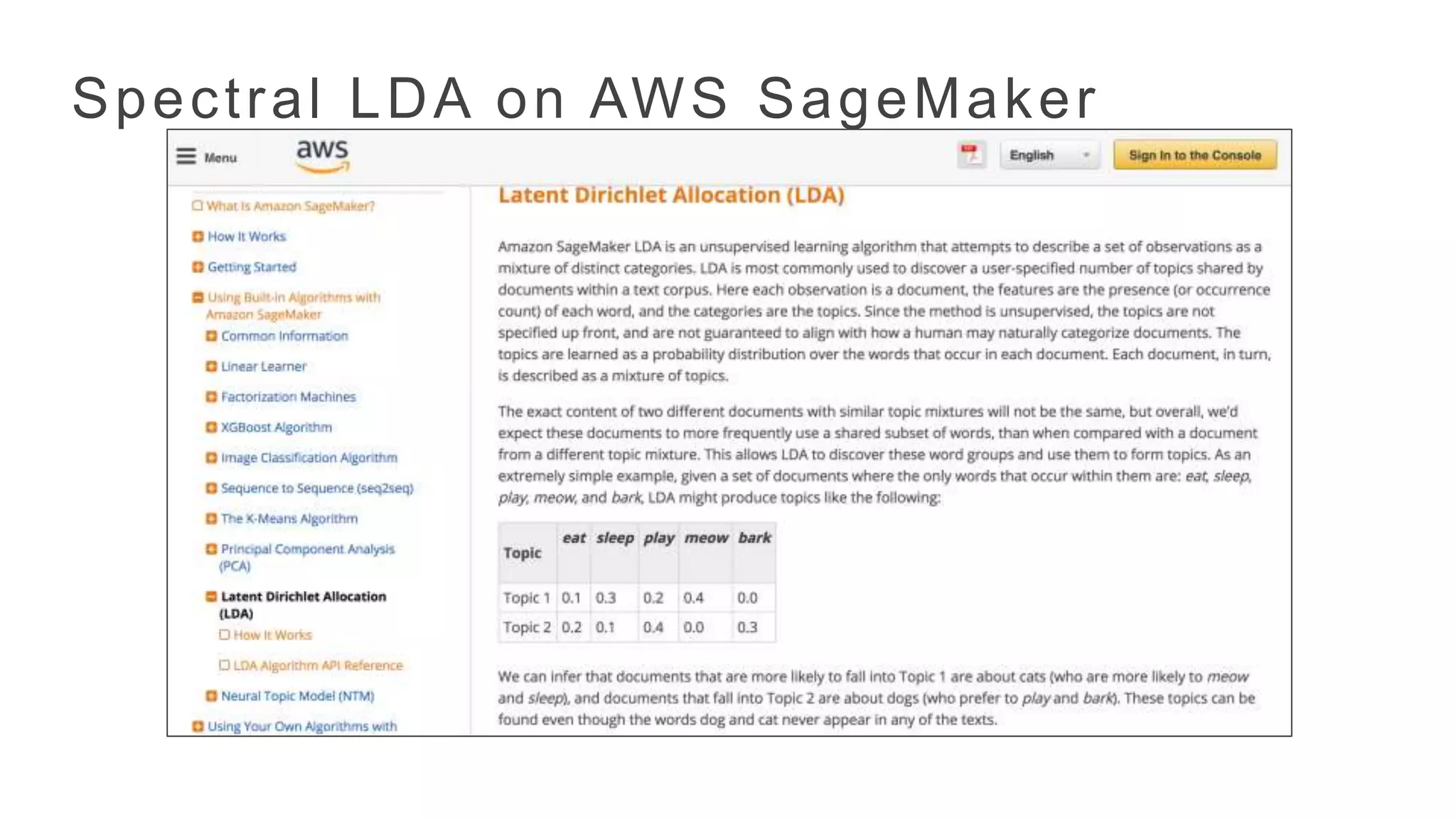
Topic-word matrix [word= i|topic = j ]
Topic proportions P[topic = j|document]
Moment Tensor: Co-occurrence of Word Triplets
= + +
crim
e
Sports
Educa
on
Learning LDA Model
37.
Topic-word matrix [word= i|topic = j ]
Topic proportions P[topic = j|document]
Moment Tensor: Co-occurrence of Word Triplets
= + +
crim
e
Sports
Educa
on
Learning LDA Model
Why Tensors?
Statistical reasons:
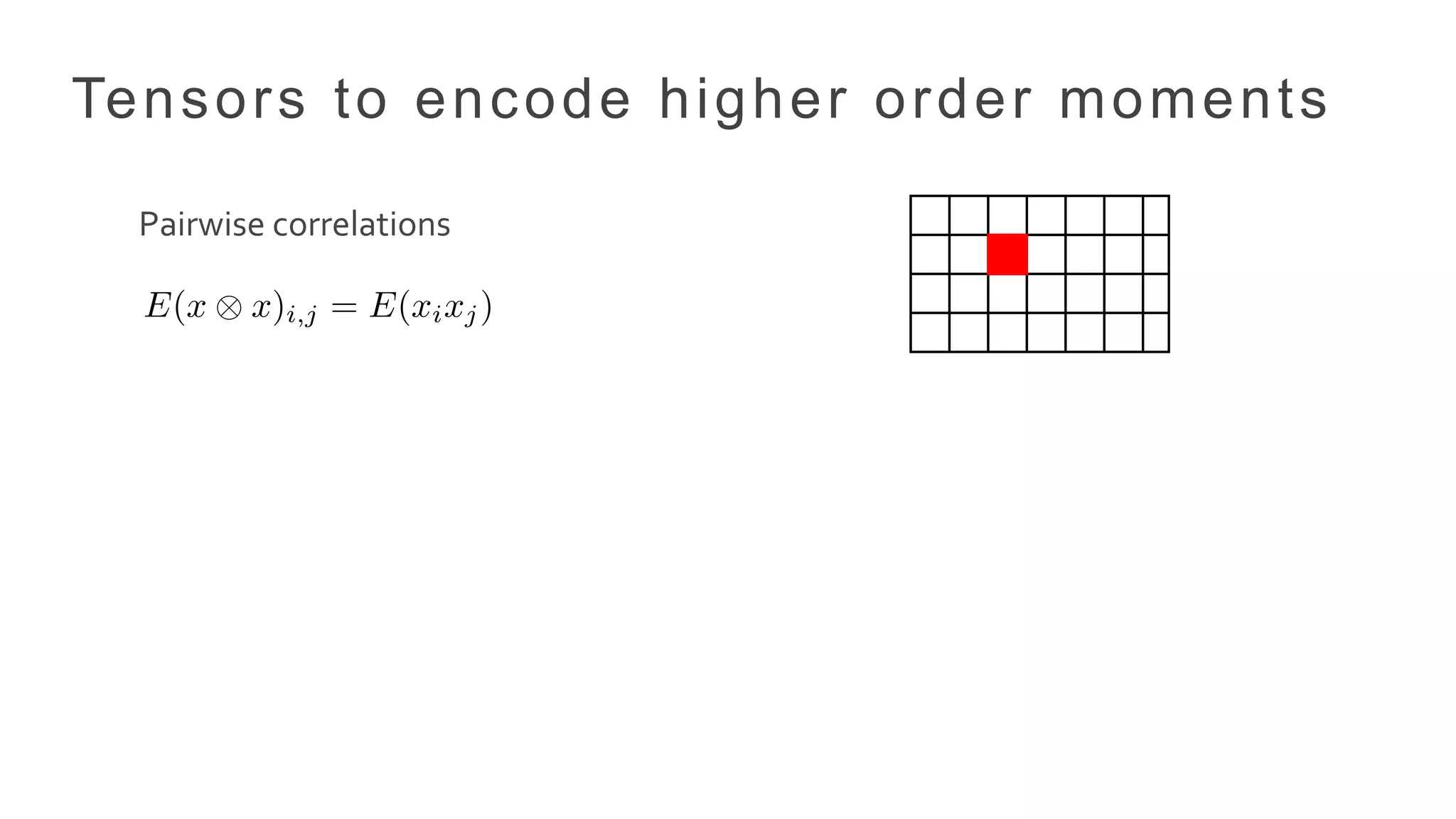
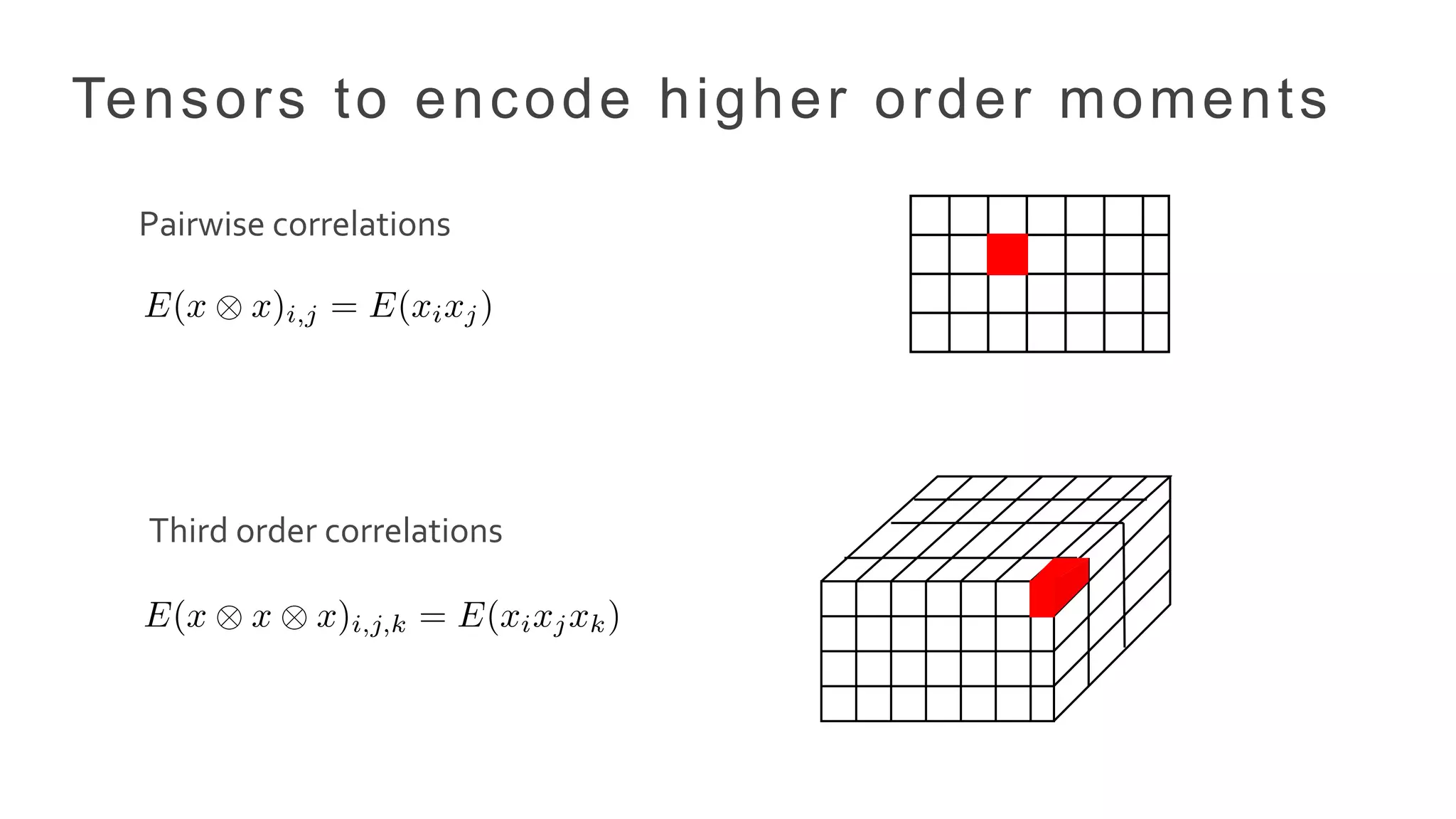
•Incorporate higher order relationships in data
• Discover hidden topics (not possible with matrix methods)
A. Anandkumar etal,Tensor Decompositions for Learning Latent Variable Models, JMLR 2014.
40.
Why Tensors?
Statistical reasons:
•Incorporate higher order relationships in data
• Discover hidden topics (not possible with matrix methods)
Computational reasons:
• Tensor algebra is parallelizable like linear algebra.
• Faster than other algorithms for LDA
• Flexible: Training and inference decoupled
• Guaranteed in theory to converge to global optimum
A. Anandkumar etal,Tensor Decompositions for Learning Latent Variable Models, JMLR 2014.
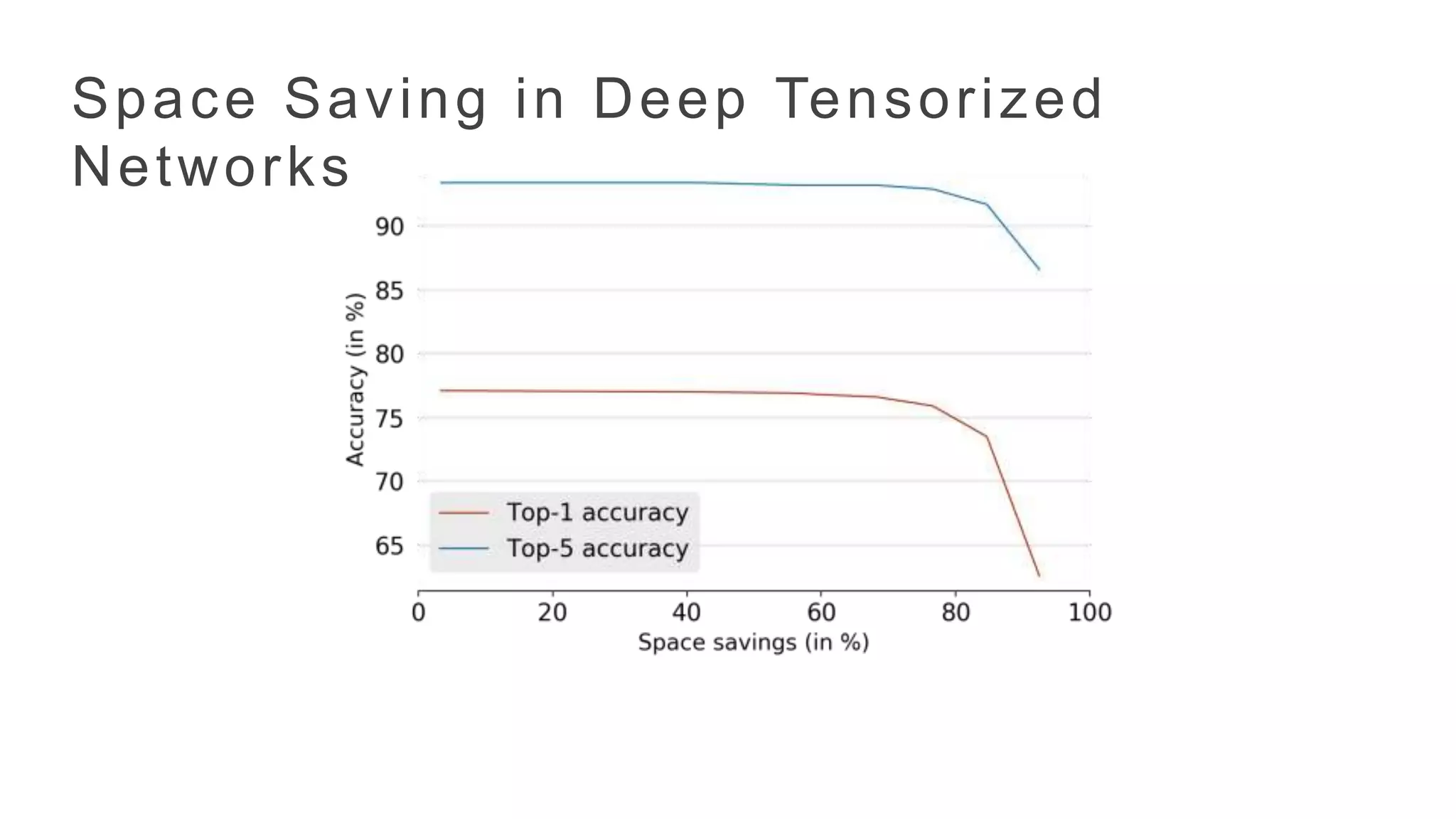
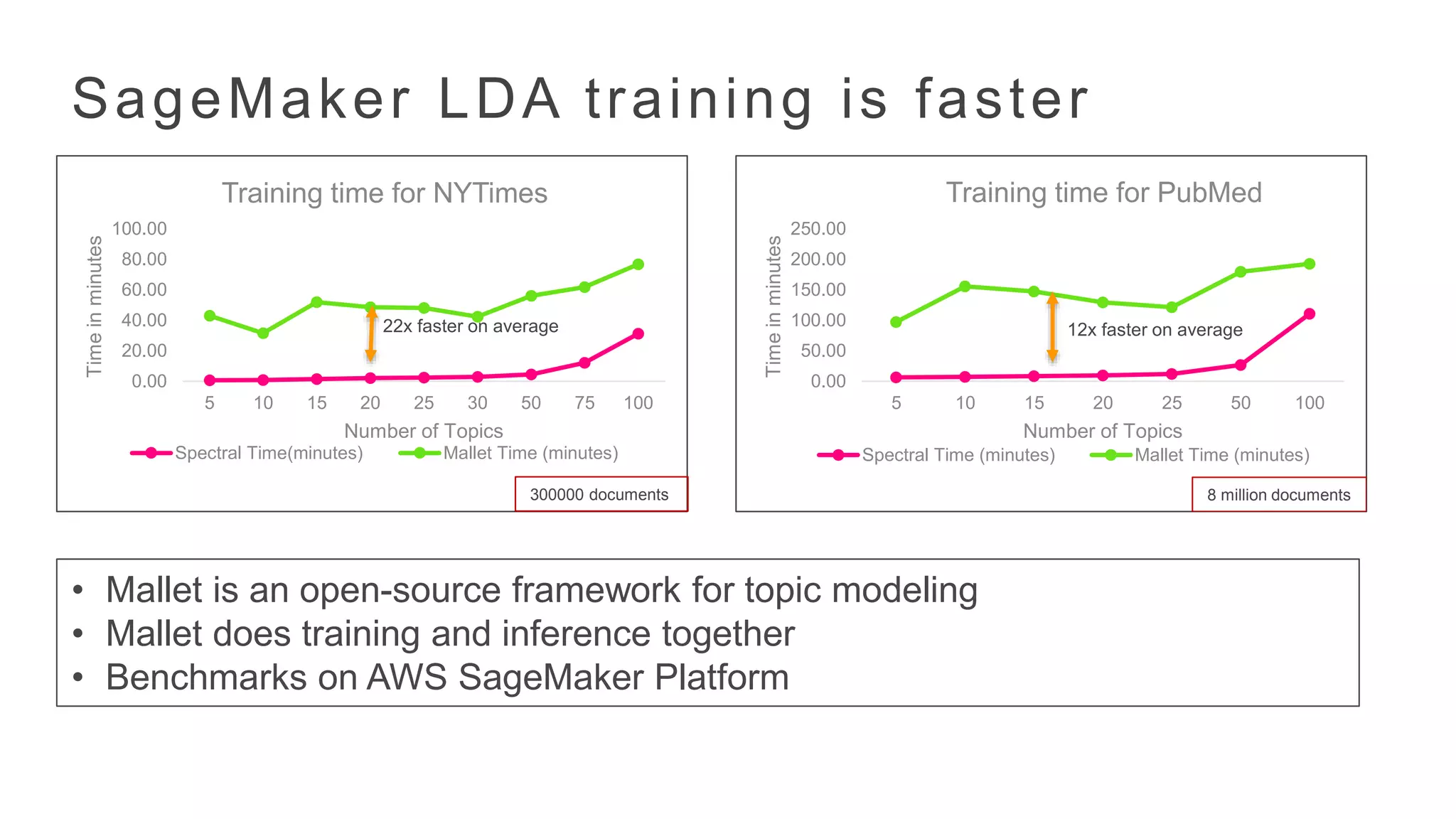
SageMaker LDA trainingis faster
0.00
20.00
40.00
60.00
80.00
100.00
5 10 15 20 25 30 50 75 100
Timeinminutes
Number of Topics
Training time for NYTimes
Spectral Time(minutes) Mallet Time (minutes)
0.00
50.00
100.00
150.00
200.00
250.00
5 10 15 20 25 50 100
Timeinminutes
Number of Topics
Training time for PubMed
Spectral Time (minutes) Mallet Time (minutes)
8 million documents
22x faster on average 12x faster on average
• Mallet is an open-source framework for topic modeling
• Mallet does training and inference together
• Benchmarks on AWS SageMaker Platform
300000 documents
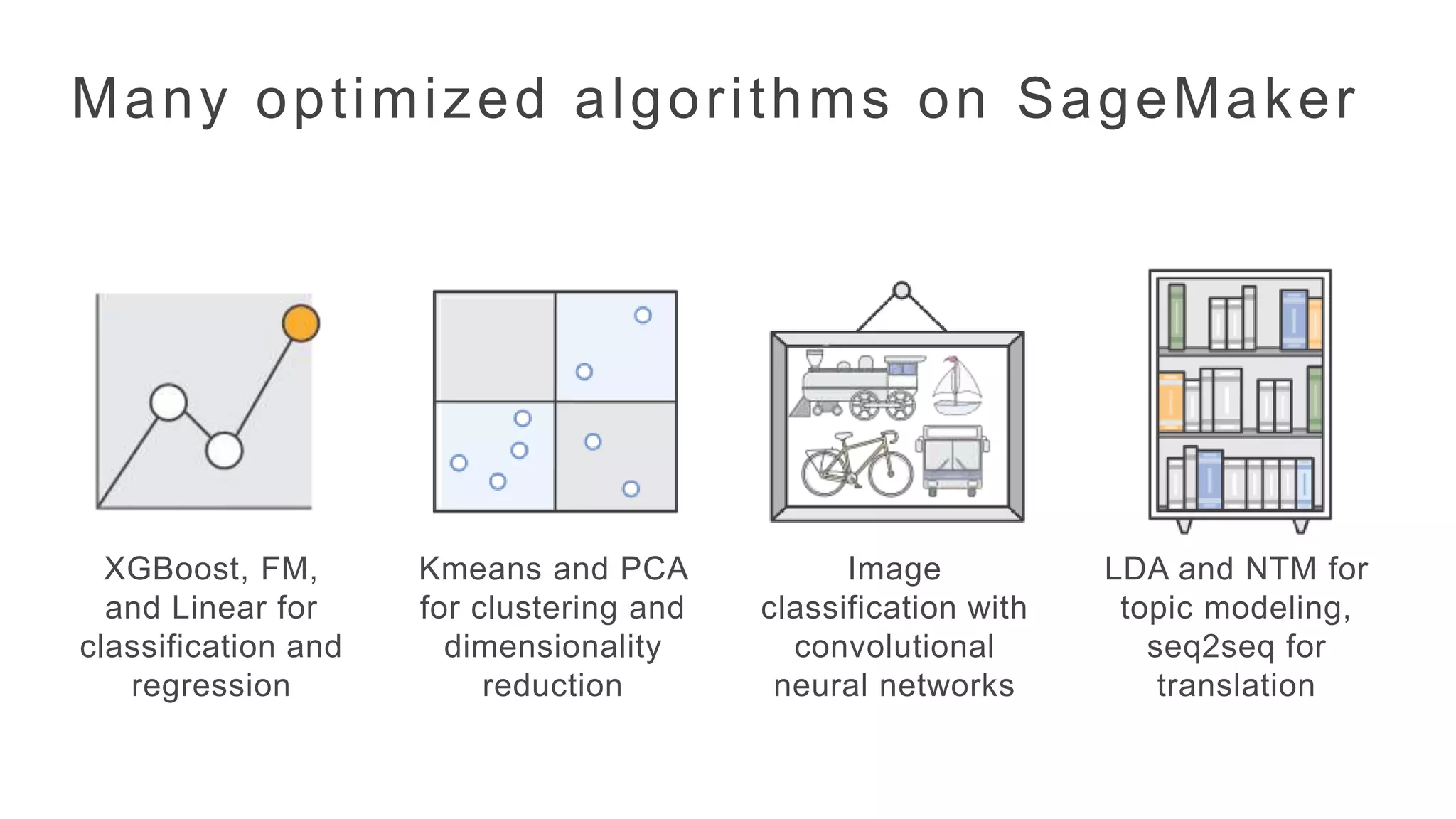
XGBoost, FM,
and Linearfor
classification and
regression
Kmeans and PCA
for clustering and
dimensionality
reduction
Image
classification with
convolutional
neural networks
LDA and NTM for
topic modeling,
seq2seq for
translation
Many optimized algorithms on SageMaker
45.
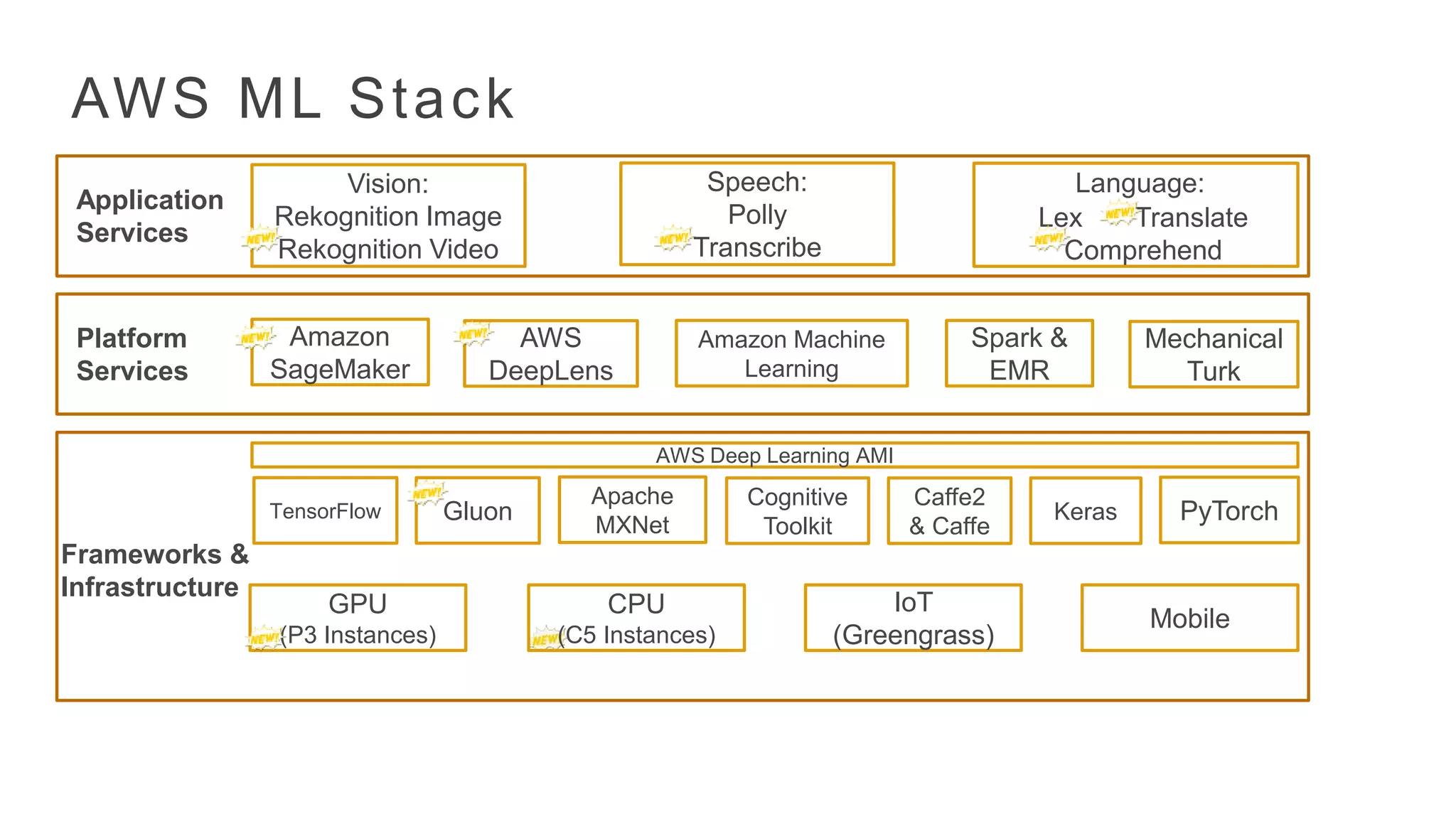
AWS ML Stack
Frameworks&
Infrastructure
AWS Deep Learning AMI
GPU
(P3 Instances)
Mobile
CPU
(C5 Instances)
IoT
(Greengrass)
Vision:
Rekognition Image
Rekognition Video
Speech:
Polly
Transcribe
Language:
Lex Translate
Comprehend
Apache
MXNet
PyTorch
Cognitive
Toolkit
Keras
Caffe2
& Caffe
TensorFlow Gluon
Application
Services
Platform
Services
Amazon Machine
Learning
Mechanical
Turk
Spark &
EMR
Amazon
SageMaker
AWS
DeepLens
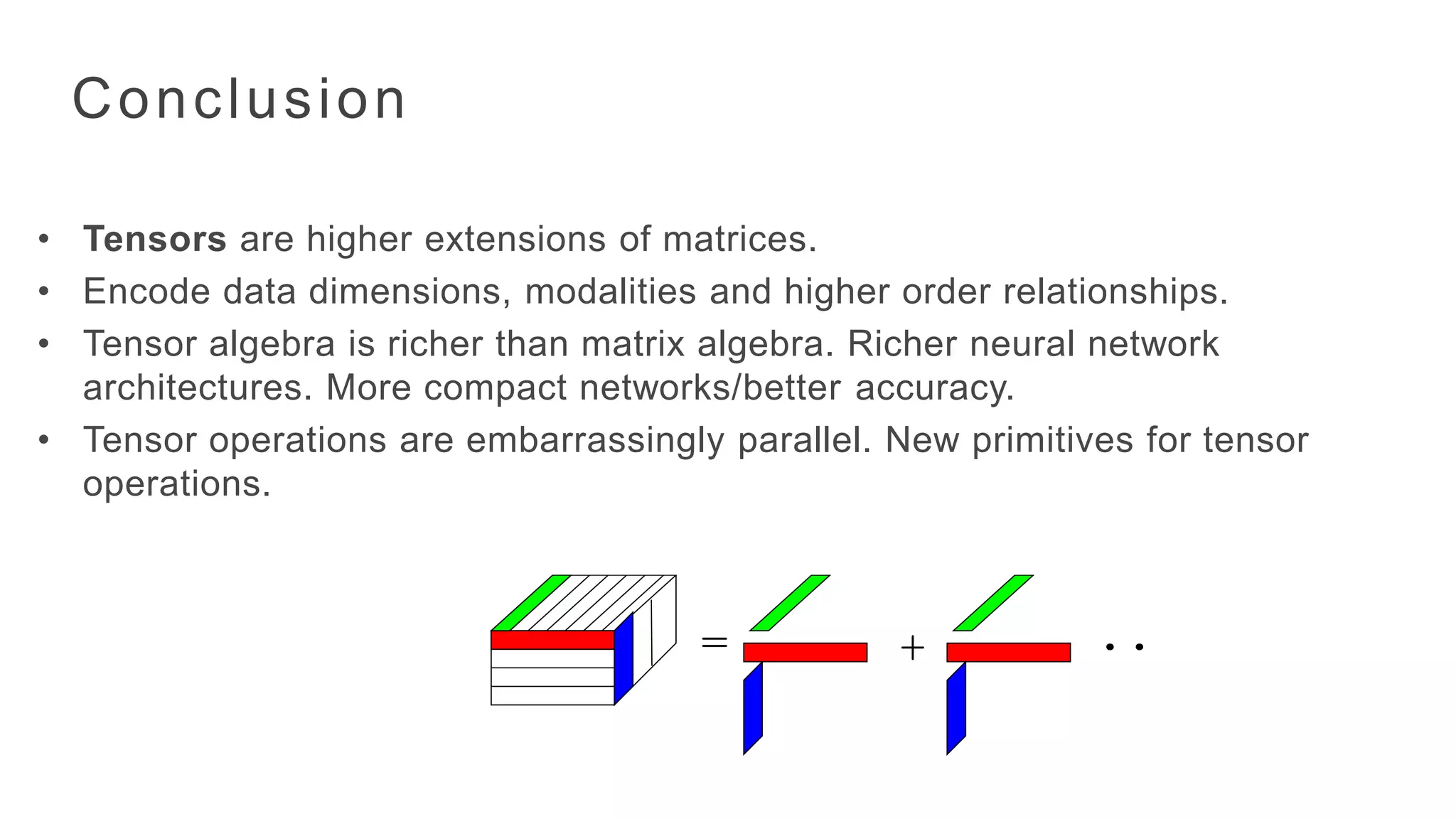
Conclusion
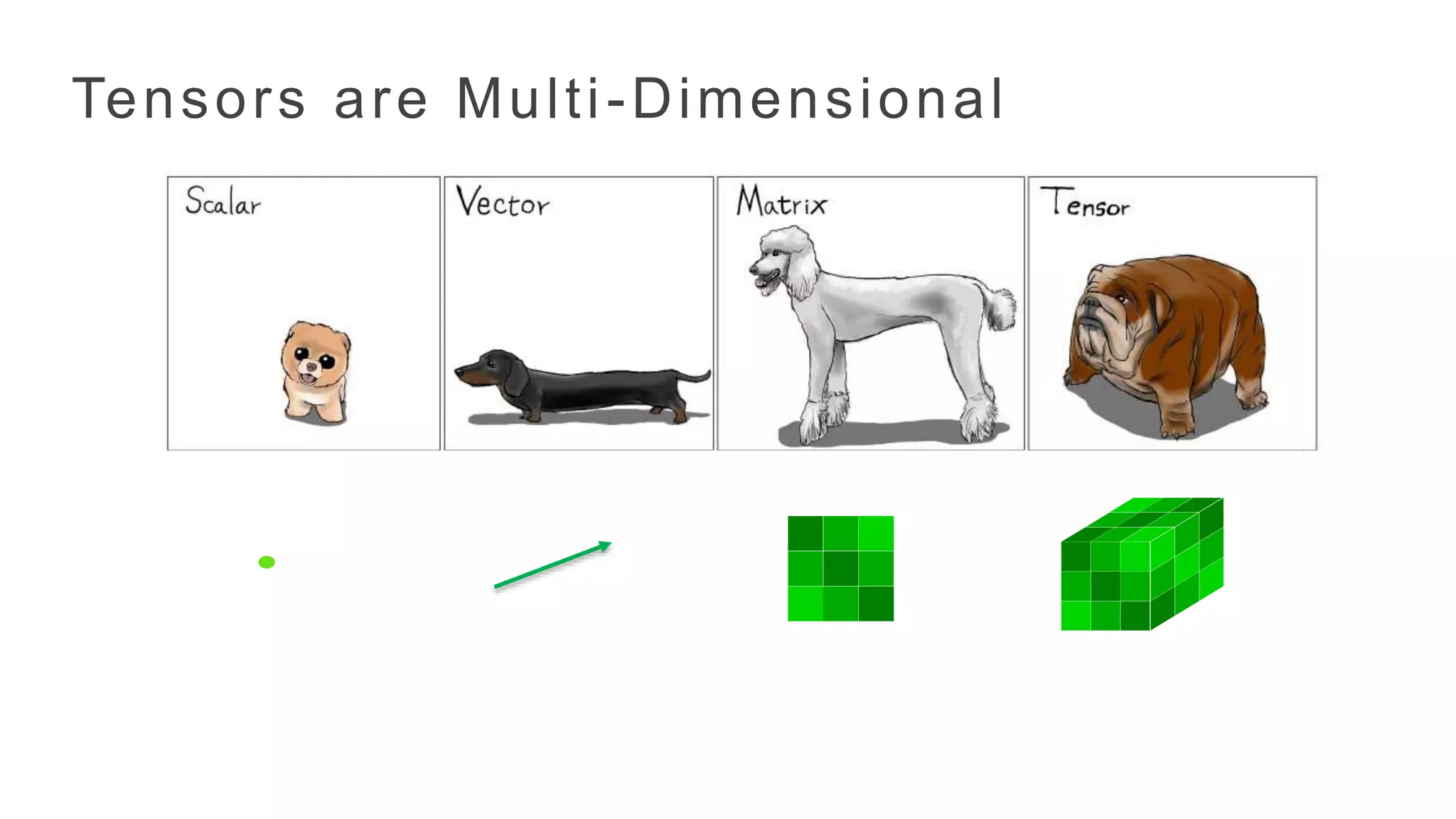
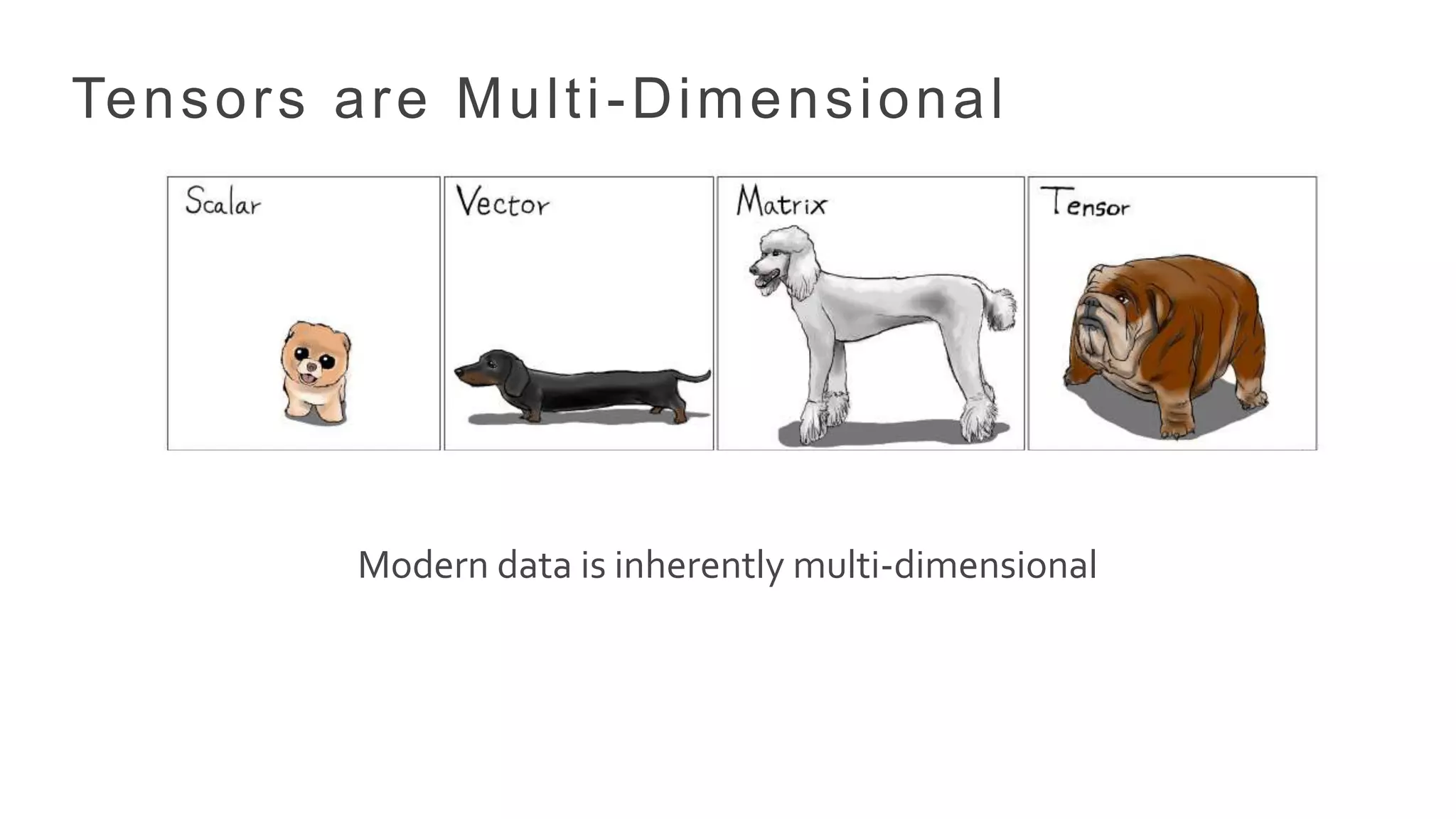
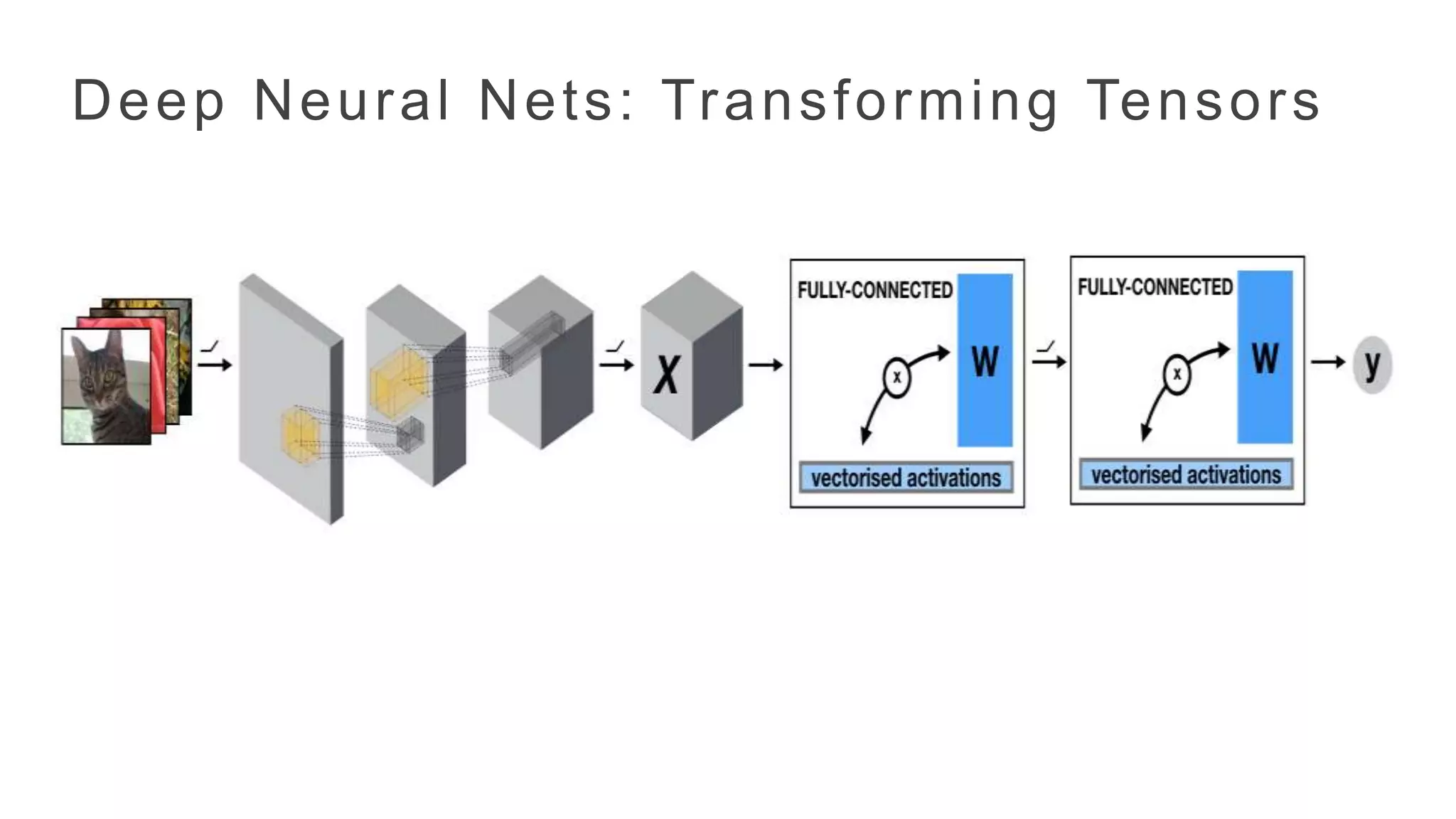
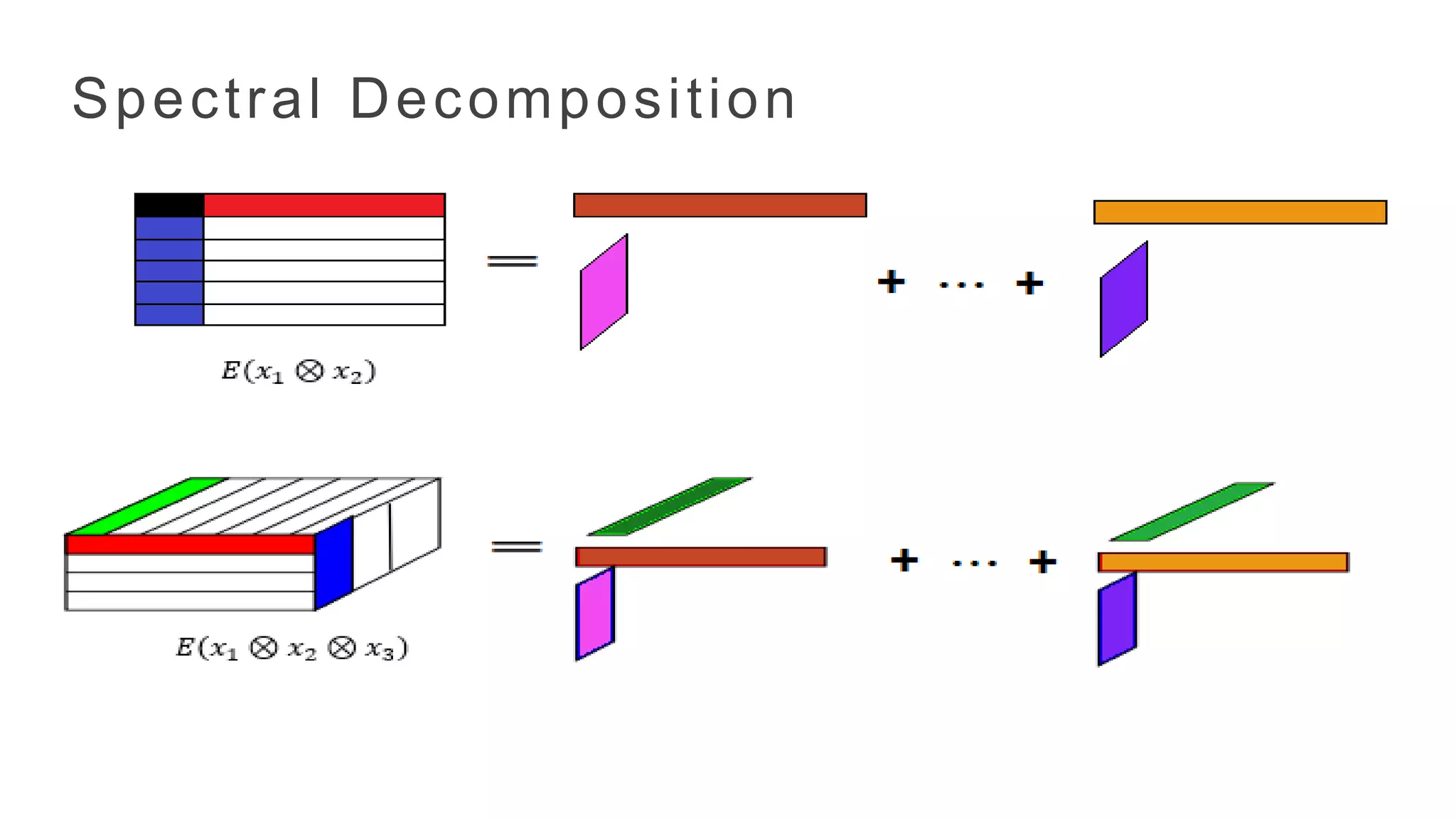
• Tensors arehigher extensions of matrices.
• Encode data dimensions, modalities and higher order relationships.
• Tensor algebra is richer than matrix algebra. Richer neural network
architectures. More compact networks/better accuracy.
• Tensor operations are embarrassingly parallel. New primitives for tensor
operations.
= + ..
#44 End-to-End Machine Learning Platform
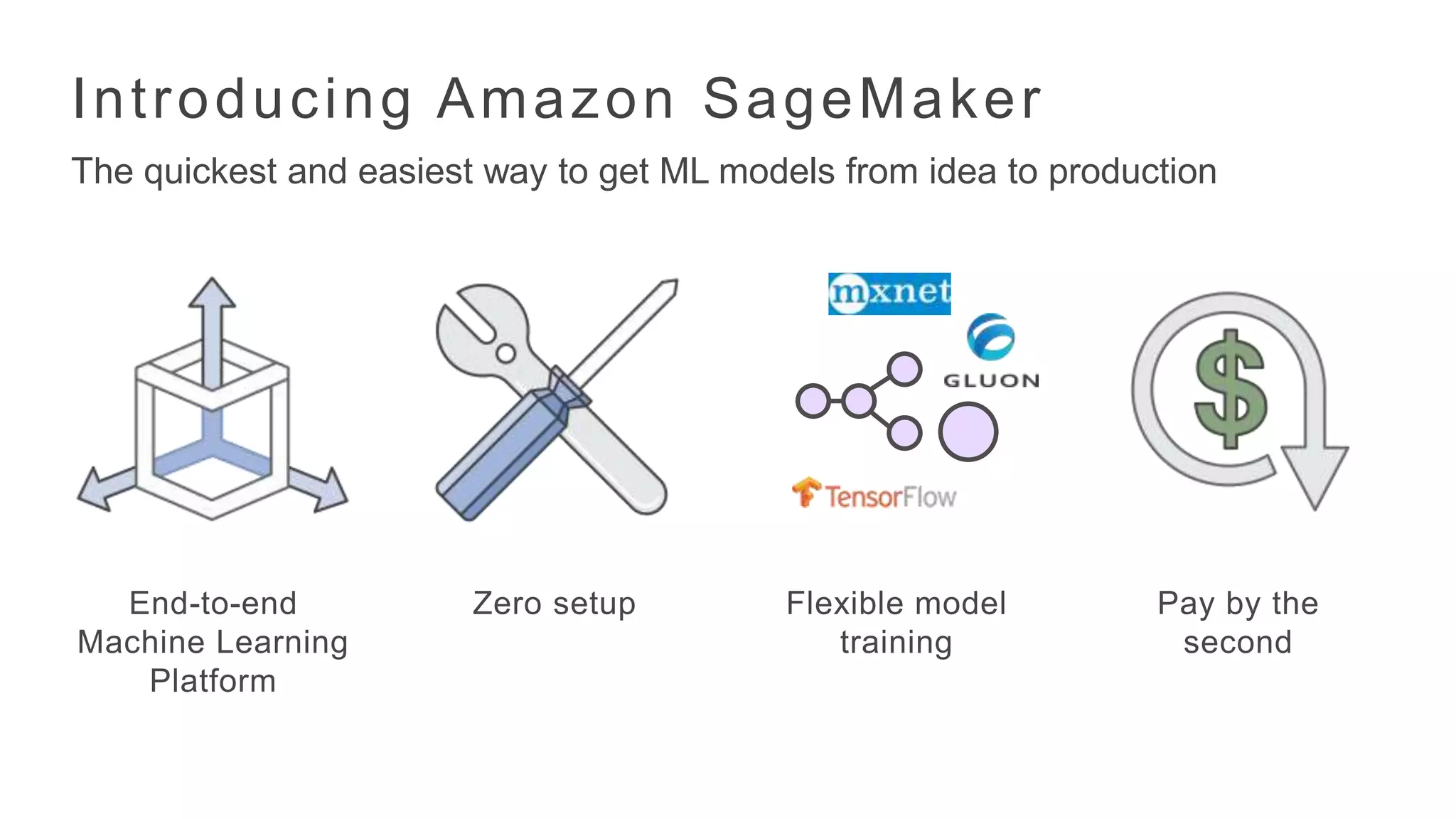
Amazon SageMaker offers a familiar integrated development environment so that you can start processing your training dataset and developing your algorithms immediately. With one-click training, Amazon SageMaker provides a distributed training environment complete with high-performance machine learning algorithms, and built-in hyperparameter optimization for auto-tuning your models. When you’re ready to deploy, launching a secure and elastically scalable production environment is as simple as clicking a button in the Amazon SageMaker management console.
Zero Setup
Amazon SageMaker provides hosted Jupyter notebooks that require no setup, so you can begin processing your training datasets and developing your algorithms immediately. With a few clicks in the Amazon SageMaker console, you can create a fully managed notebook instance, pre-loaded with useful libraries for machine learning and deep learning frameworks like TensorFlow, and Apache MXNet. You need only add your data.
Flexible Model Training
With native support for bring-your-own-algorithms and frameworks, model training in Amazon SageMaker is flexible. Amazon SageMaker provides native Apache MXNet and TensorFlow support, and offers a range of built-in, high performance machine learning algorithms, in addition to supporting popular open source algorithms. If you want to train against another algorithm or with an alternative deep learning framework, you simply bring your own algorithms or deep learning frameworks via a Docker container.
Pay by the second
With Amazon SageMaker , you pay only for what you use. Authoring, training, and hosting is billed by the second, with no minimum fees and no upfront commitments. Pricing within Amazon SageMaker is broken down by on-demand ML instances, ML storage, and fees for data processing in notebooks and hosting instances.
#45 The result of this is
1) Linear Learner - Regression
2) Linear Learner - Classification
3) K-means
4) Principal Component Analysis
5) Factorization Machines
6) Neural Topic Modeling
7) Latent Dirichlet Allocation
8) XGBoost
9) Seq2Seq
10) Image classification (ResNet)






![Tensorly with Pytorch backend
import tensorly as tl
from tensorly.random import tucker_tensor
tl.set_backend(‘pytorch’)
core, factors = tucker_tensor((5, 5, 5),
rank=(3, 3, 3))
core = Variable(core, requires_grad=True)
factors = [Variable(f, requires_grad=True) for f in factors]
optimiser = torch.optim.Adam([core]+factors, lr=lr)
for i in range(1, n_iter):
optimiser.zero_grad()
rec = tucker_to_tensor(core, factors)
loss = (rec - tensor).pow(2).sum()
for f in factors:
loss = loss + 0.01*f.pow(2).sum()
loss.backward()
optimiser.step()
Set Pytorch backend
Attach gradients
Set optimizer
TuckerTensor form](https://image.slidesharecdn.com/scaled-ml-2018-180529212354/75/Role-of-Tensors-in-Machine-Learning-15-2048.jpg)



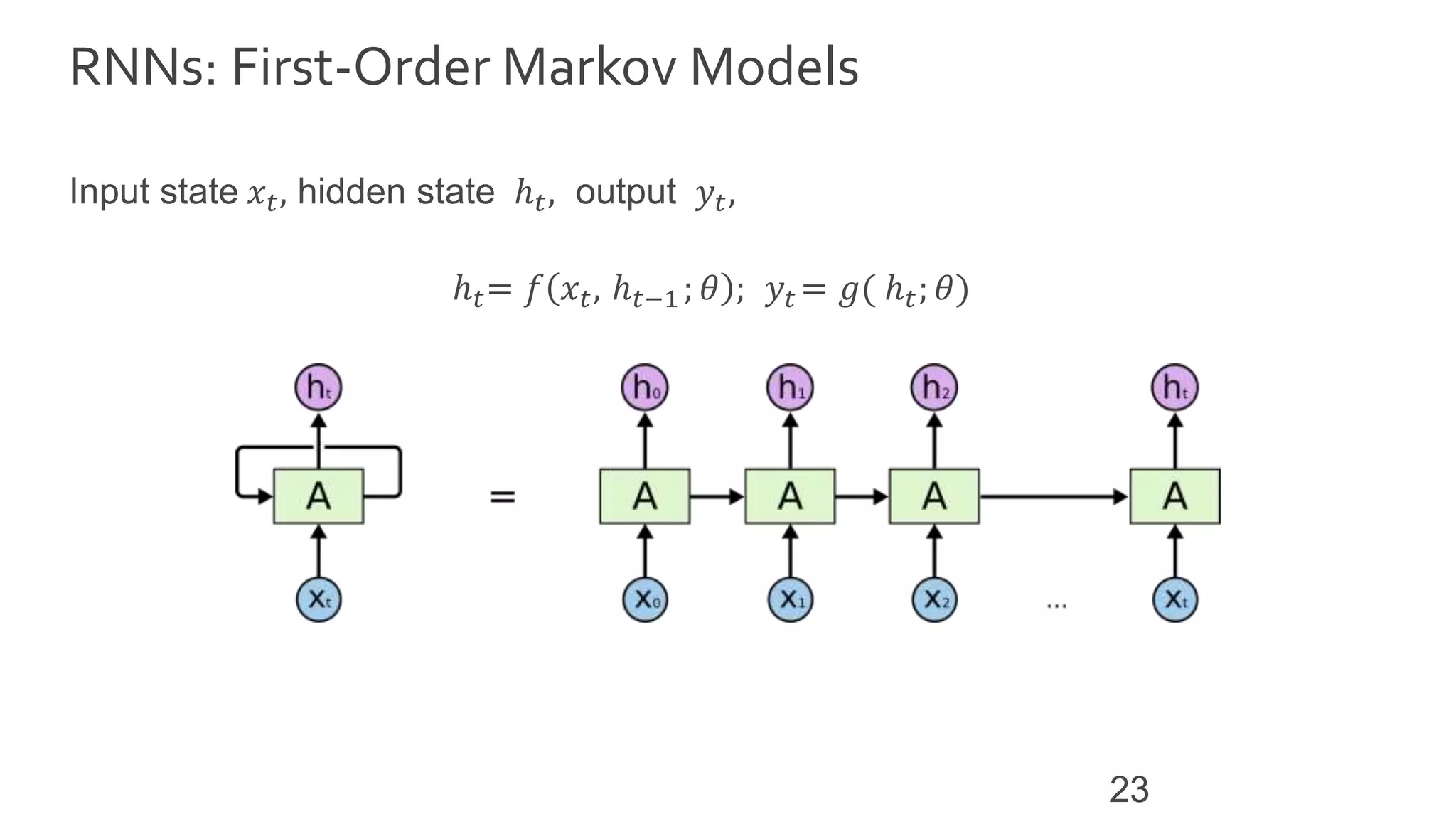
![Tensorized RNNs
L-order Markov
ℎ 𝑡= 𝑓 𝑥𝑡, ℎ 𝑡−1 , ℎ 𝑡−2 , … ℎ 𝑡−𝐿 ; 𝜃 ; 𝑦𝑡 = 𝑔( ℎ 𝑡; 𝜃)
Polynomial Interactions
𝑠𝑡−1 = [1, ℎ 𝑡−1, ℎ 𝑡−2 , … ℎ 𝑡−𝐿 ]
ℎ 𝑡,𝛼 = 𝑓 𝑊ℎ𝑥
𝑥𝑡 + 𝒲 𝛼,𝑖1,…𝑖 𝑃
𝑠𝑡−1;𝑖1
⨂ … ⨂𝑠𝑡−1;𝑖 𝑃
; 𝜃 ;
24](https://image.slidesharecdn.com/scaled-ml-2018-180529212354/75/Role-of-Tensors-in-Machine-Learning-24-2048.jpg)
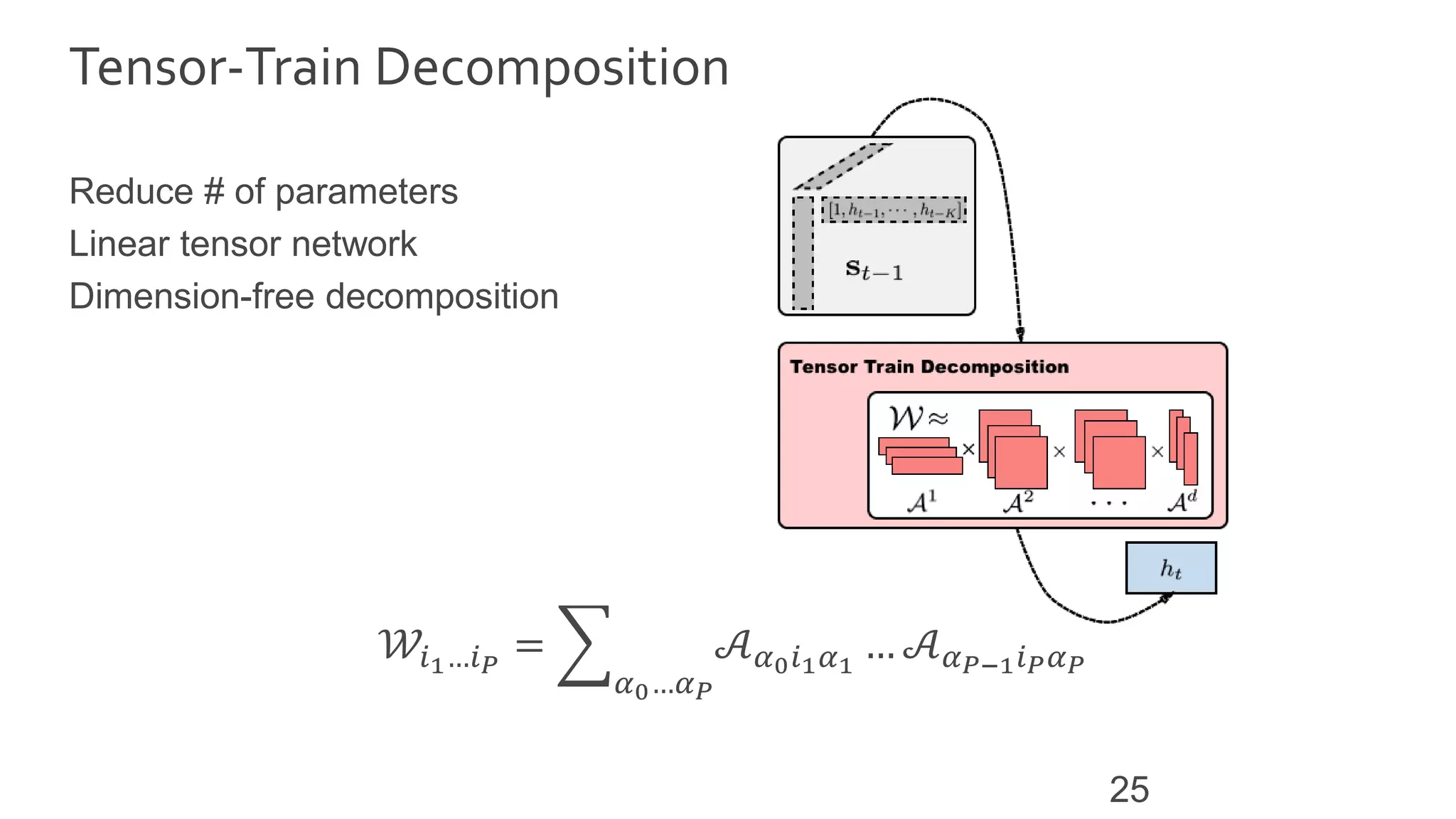
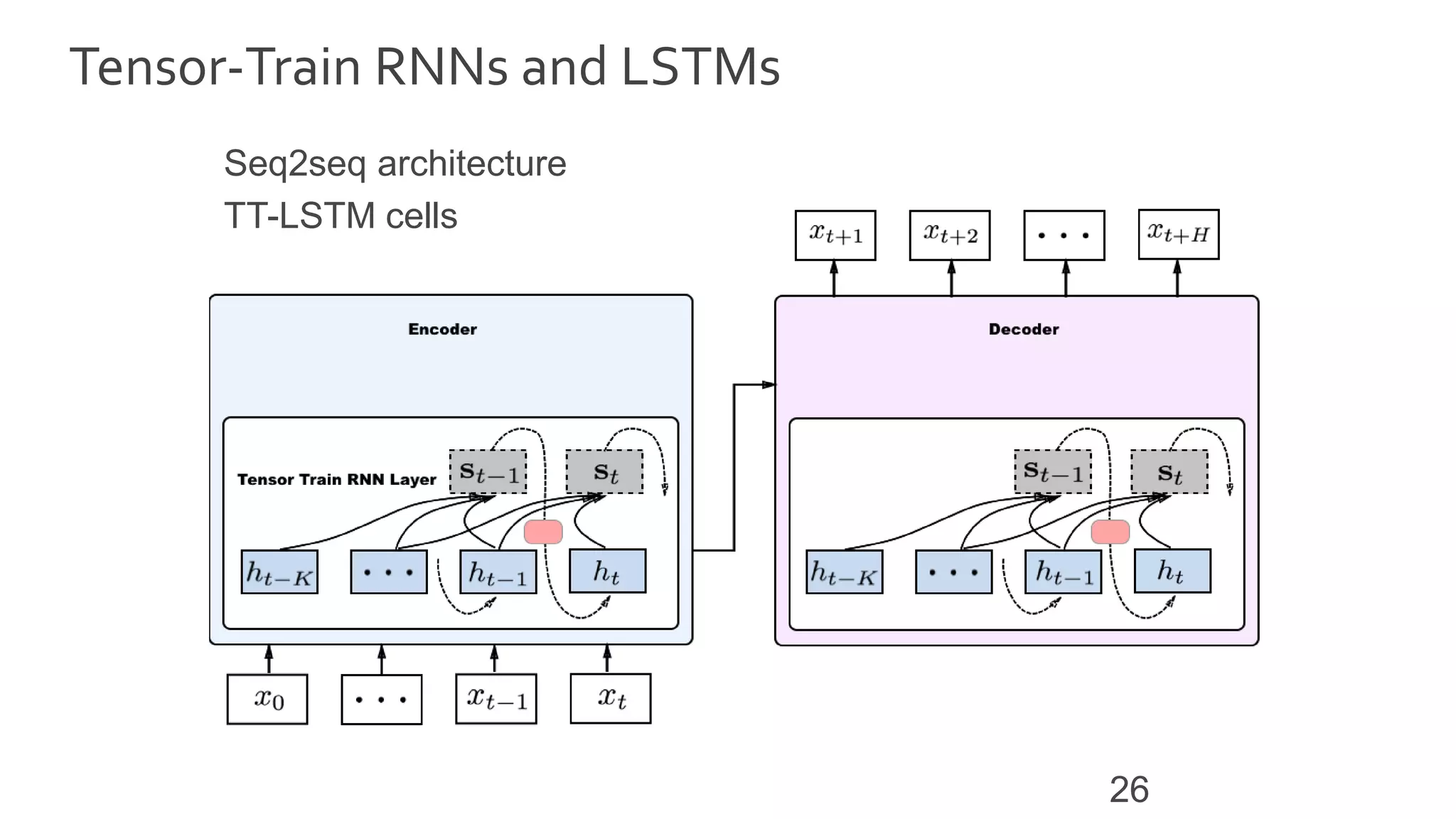
![Approximation Guarantees
Theorem 1 [Yu et al 2017]: Let the state transition function 𝑓 ∈ ℋ𝜇
𝑘
be a
Hölder continuous, with bounded derivatives up to order k and finite
Fourier magnitude distribution 𝐶𝑓. Then a single layer Tensor Train RNN
can approximate 𝑓 with an estimation error of 𝜀 using with ℎ hidden units:
ℎ ≤
𝐶𝑓
2
𝜀
𝑑 − 1
𝑟 + 1 − 𝑘−1
𝑘 − 1
+
𝐶𝑓
2
𝜀
𝐶 𝑘 𝑝−𝑘
Where 𝑑 is the size of the state space, 𝑟 is the tensor-train rank and 𝑝 is
the degree of high-order polynomials i.e., the order of tensor.
• Easier to approximate if function is smooth
• Polynomial interactions are more efficient
Long-term Forecasting usingTensor-Train RNNs by R.Yu, S. Zheng, A,Y.Yue, 2017.](https://image.slidesharecdn.com/scaled-ml-2018-180529212354/75/Role-of-Tensors-in-Machine-Learning-28-2048.jpg)




![Topic-word matrix [word = i|topic = j ]
Topic proportions P[topic = j|document]
Moment Tensor: Co-occurrence of Word Triplets
= + +
crim
e
Sports
Educa
on
Learning LDA Model](https://image.slidesharecdn.com/scaled-ml-2018-180529212354/75/Role-of-Tensors-in-Machine-Learning-36-2048.jpg)
![Topic-word matrix [word = i|topic = j ]
Topic proportions P[topic = j|document]
Moment Tensor: Co-occurrence of Word Triplets
= + +
crim
e
Sports
Educa
on
Learning LDA Model](https://image.slidesharecdn.com/scaled-ml-2018-180529212354/75/Role-of-Tensors-in-Machine-Learning-37-2048.jpg)

















![[AIoTLab]attention mechanism.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/aiotlabattentionmechanism-230406114603-e5ba0365-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)









































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





