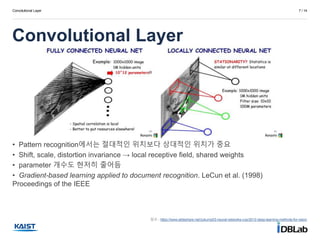
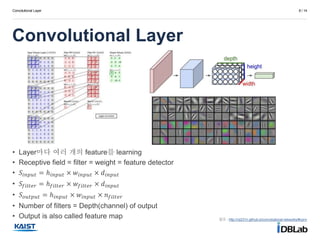
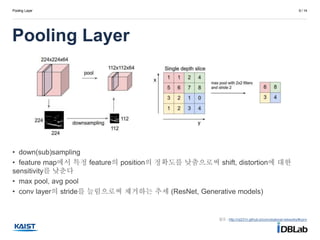
Perceptron
Perceptron
3 / 14
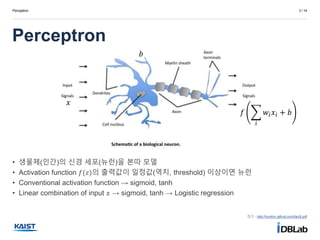
•생물체(인간)의 신경 세포(뉴런)을 본따 모델
• Activation function 𝑓(𝑧)의 출력값이 일정값(역치, threshold) 이상이면 뉴런
• Conventional activation function → sigmoid, tanh
• Linear combination of input 𝑥 → sigmoid, tanh → Logistic regression
참조 - http://hunkim.github.io/ml/lec8.pdf
𝑓
𝑖
𝑤𝑖 𝑥𝑖 + 𝑏
𝑥
𝑏
4.
Perceptron
Perceptron
4 / 14
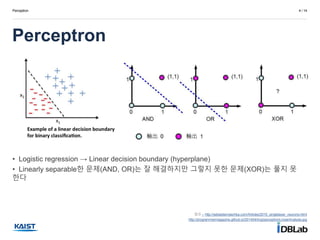
•Logistic regression → Linear decision boundary (hyperplane)
• Linearly separable한 문제(AND, OR)는 잘 해결하지만 그렇지 못한 문제(XOR)는 풀지 못
한다
참조 – http://sebastianraschka.com/Articles/2015_singlelayer_neurons.html
http://programmermagazine.github.io/201404/img/perceptronLinearAnalysis.jpg
5.
MLP
Multi-layer Perceptron (MLP)
5/ 14
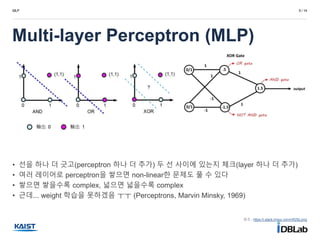
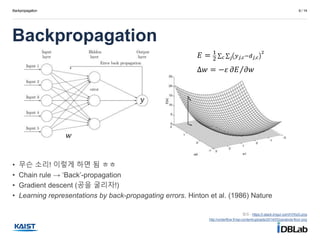
• 선을 하나 더 긋고(perceptron 하나 더 추가) 두 선 사이에 있는지 체크(layer 하나 더 추가)
• 여러 레이어로 perceptron을 쌓으면 non-linear한 문제도 풀 수 있다
• 쌓으면 쌓을수록 complex, 넓으면 넓을수록 complex
• 근데... weight 학습을 못하겠음 ㅜㅜ (Perceptrons, Marvin Minsky, 1969)
참조 - https://i.stack.imgur.com/nRZ6z.png
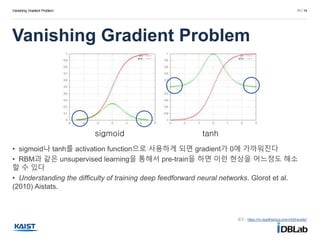
Vanishing Gradient Problem
VanishingGradient Problem
11 / 14
• sigmoid나 tanh를 activation function으로 사용하게 되면 gradient가 0에 가까워진다
• RBM과 같은 unsupervised learning을 통해서 pre-train을 하면 이런 현상을 어느정도 해소
할 수 있다
• Understanding the difficulty of training deep feedforward neural networks. Glorot et al.
(2010) Aistats.
참조 - https://nn.readthedocs.io/en/rtd/transfer/
sigmoid tanh
12.
ReLU
Rectified Linear Unit
12/ 14
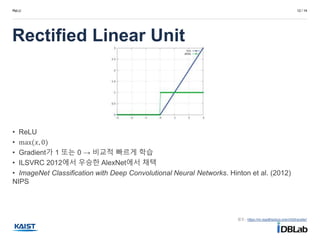
• ReLU
• max(𝑥, 0)
• Gradient가 1 또는 0 → 비교적 빠르게 학습
• ILSVRC 2012에서 우승한 AlexNet에서 채택
• ImageNet Classification with Deep Convolutional Neural Networks. Hinton et al. (2012)
NIPS
참조 - https://nn.readthedocs.io/en/rtd/transfer/
13.
ReLU
Rectified Linear Unit
13/ 14
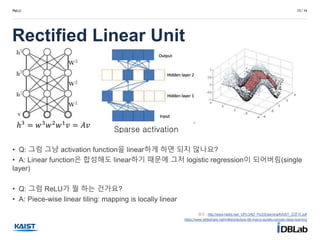
• Q: 그럼 그냥 activation function을 linear하게 하면 되지 않나요?
• A: Linear function은 합성해도 linear하기 때문에 그저 logistic regression이 되어버림(single
layer)
• Q: 그럼 ReLU가 뭘 하는 건가요?
• A: Piece-wise linear tiling: mapping is locally linear
ℎ3 = 𝑤3 𝑤2 𝑤1 𝑣 = 𝐴𝑣
참조 - http://www.hellot.net/_UPLOAD_FILES/semina/KAIST_김준모.pdf
https://www.slideshare.net/milkers/lecture-06-marco-aurelio-ranzato-deep-learning
Sparse activation
14.
Dropout
Dropout
14 / 14
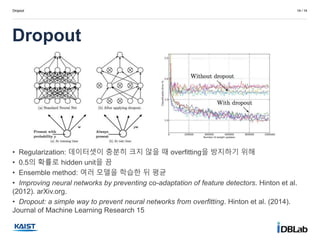
•Regularization: 데이터셋이 충분히 크지 않을 때 overfitting을 방지하기 위해
• 0.5의 확률로 hidden unit을 끔
• Ensemble method: 여러 모델을 학습한 뒤 평균
• Improving neural networks by preventing co-adaptation of feature detectors. Hinton et al.
(2012). arXiv.org.
• Dropout: a simple way to prevent neural networks from overfitting. Hinton et al. (2014).
Journal of Machine Learning Research 15
15.
ILSVRC
ImageNet Large-Scale VisualRecognition Challenge
15 / 14
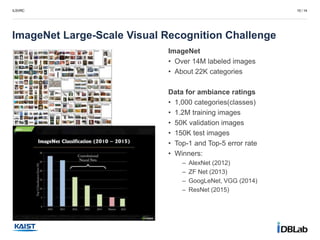
ImageNet
• Over 14M labeled images
• About 22K categories
Data for ambiance ratings
• 1,000 categories(classes)
• 1.2M training images
• 50K validation images
• 150K test images
• Top-1 and Top-5 error rate
• Winners:
– AlexNet (2012)
– ZF Net (2013)
– GoogLeNet, VGG (2014)
– ResNet (2015)












![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)


![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)



![[PR12] image super resolution using deep convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/pr12imagesuper-resolutionusingdeepconvolutionalnetworks-170424004350-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[신경망기초] 심층신경망개요](https://cdn.slidesharecdn.com/ss_thumbnails/nn10-180318142325-thumbnail.jpg?width=640&height=640&fit=bounds)







![[논문발표] 20160801 A Sentiment-Enhanced Personalized Location Recommendation System](https://cdn.slidesharecdn.com/ss_thumbnails/20160801asentiment-enhancedpersonalizedlocationrecommendationsystem-160819055329-thumbnail.jpg?width=640&height=640&fit=bounds)
![[세미나] 20160819 Java 프로그래머를 위한 Scala 튜토리얼](https://cdn.slidesharecdn.com/ss_thumbnails/20160819javascala-160819055041-thumbnail.jpg?width=640&height=640&fit=bounds)
![[논문발표] 20160725 A Random Walk Around the City: New Venue Recommendation in Lo...](https://cdn.slidesharecdn.com/ss_thumbnails/20160725arandomwalkaroundthecity-160726112403-thumbnail.jpg?width=640&height=640&fit=bounds)
![[세미나] 20160520 Gradle](https://cdn.slidesharecdn.com/ss_thumbnails/20160520gradle-160523005620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[논문발표] 20160404 Supporting Serendipitous Social Interaction Using Human Mobil...](https://cdn.slidesharecdn.com/ss_thumbnails/20160404serendipitoussocialinteraction-160404123918-thumbnail.jpg?width=640&height=640&fit=bounds)