Introduction
• Neural ArchitectureSearch with Reinforcement Learning(NAS) 후속 논문
• NAS : CNN(CIFAR-10), RNN(Penn Treebank) 구조 설계
• CIFAR-10 이라는 작은 데이터셋 학습에 800 GPU, 28days 소요 큰 데이터셋은??
• Learning Transferable Architectures for Scalable Image Recognition (2018, CVPR)
• CNN에 초점을 맞추어 이식 가능하고 더 효율적인 architecture를 제안(NASNet)
• CIFAR-10으로 찾은 Convolution Cell을 이용하여 ImageNet에 적용 SOTA 성능 달성!
• NAS 대비 학습에 소요되는 시간 단축 (500GPU, 4days 소요, x7 speed up)
* NAS : Nvidia K40 GPU / NASNet : Nvidia P100s GPU
4.
Contribution(1)
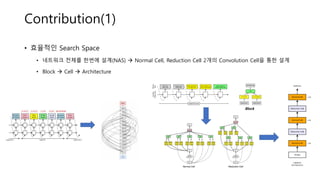
• 효율적인 SearchSpace
• 네트워크 전체를 한번에 설계(NAS) Normal Cell, Reduction Cell 2개의 Convolution Cell을 통한 설계
• Block Cell Architecture
Block
5.
Contribution(2)
• Transferability &Good Performance
• CIFAR-10으로 찾은 Convolution Cell을 이용하여 더 큰 Dataset에 적용 가능
• CIFAR-10, ImageNet 기준 SOTA 성능 달성
• Object Detection에 NASNet 구조를 적용하였을 때 높은 성능
6.
Method(1)
• Overall architecturesof the convolutional nets are manually
predetermined
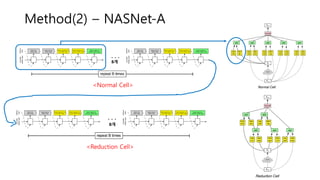
• Normal Cell - convolutional cells that return a feature map of the same
dimension
• Reduction Cell - convolutional cells that return a feature map where the
feature map height and width is reduced by a factor of two (Initial
operation with stride of two conv)
• Using common heuristic to double the number of filters in the
output whenever the spatial activation size is reduced
• N, 첫 convolution cell의 filter 개수는 User가 지정해주어야 하는 변수
7.
Method(2)
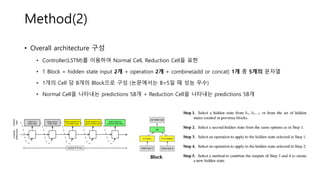
• Overall architecture구성
• Controller(LSTM)를 이용하여 Normal Cell, Reduction Cell을 표현
• 1 Block = hidden state input 2개 + operation 2개 + combine(add or concat) 1개 총 5개의 문자열
• 1개의 Cell 당 B개의 Block으로 구성 (논문에서는 B=5일 때 성능 우수)
• Normal Cell을 나타내는 predictions 5B개 + Reduction Cell을 나타내는 predictions 5B개
Block
8.
Method(2)
• Overall architecture구성 (Cont.)
• Controller(LSTM)를 이용하여 Normal Cell, Reduction Cell을 표현
• 1 Block = hidden state input 2개 + operation 2개 + combine(add or concat) 1개 총 5개의 문자열
• Operation 종류는 잘 알려진 방법론 중 13개
• stride = 1 (Normal Cell) / stride = 1 or 2 (Reduction Cell)
Training with RL
•Controller(LSTM)를 이용하여 예측한 Cell을 통해 Architecture 생성
• 강화학습 알고리즘으로 REINFORCE 대신 Proximal Policy Optimization(PPO) 사용
• PPO : 2017, OpenAI
• 전체적인 학습 방법은 NAS와 거의 유사
• State : controller의 hidden state
• Action : controller가 생성한 predictions
• Reward : Overall architecture의 accuracy
12.
Result(CIFAR-10)
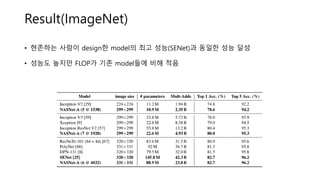
• 기존의 SOTA로알려진 network에 비해
우수한 성능!
• NAS의 CNN architecture보다 우수한
성능
• 표의 결과는 5번 수행하여 평균 낸 결과
• Best performance : 2.19%
• 괄호 안의 숫자
• (N @ # of Filters in 1st Conv Cell)
Result(ImageNet)
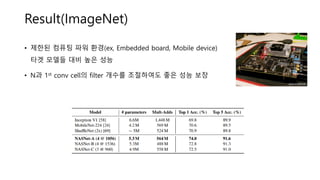
• 제한된 컴퓨팅파워 환경(ex, Embedded board, Mobile device)
타겟 모델들 대비 높은 성능
• N과 1st conv cell의 filter 개수를 조절하여도 좋은 성능 보장
15.
Result(COCO_detection)
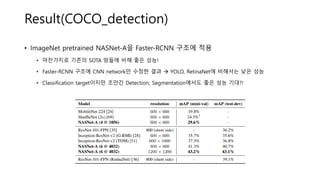
• ImageNet pretrainedNASNet-A을 Faster-RCNN 구조에 적용
• 마찬가지로 기존의 SOTA 망들에 비해 좋은 성능!
• Faster-RCNN 구조에 CNN network만 수정한 결과 YOLO, RetinaNet에 비해서는 낮은 성능
• Classification target이지만 조만간 Detection, Segmentation에서도 좋은 성능 기대?!
16.
Result(Random Search와 비교)
•강화학습을 적용하였을 때와, Random Search를 하였을 때의 성능 차이 비교
• RL을 사용하였을 때가 RS를 사용하였을 때 보다
• NAS의 RL vs RS 그래프 대비 격차가 줄어듦 제안한 Search space가 효율적임을 증명
17.
Discussion
• CNN, Classification타겟으로 좋은 성능과 확장성을 보여준 연구
• 이미지의 size가 큰 경우에도 좋은 성능 기대
• 제조업 데이터에서도 좋은 분류 성능이 나올 것으로 생각!
• 여전히 긴 학습 시간(500GPU, 4days) ENAS!
• Detection, Segmentation에서는 아직 괄목할 만한 연구는 나오지 않음
• Classification을 정복하였으니 조만간 나올 것으로 기대






















![[한국어] Neural Architecture Search with Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/nas-170612232020-thumbnail.jpg?width=640&height=640&fit=bounds)















![[paper review] 손규빈 - Eye in the sky & 3D human pose estimation in video with ...](https://cdn.slidesharecdn.com/ss_thumbnails/190321eyeposegyubin-190517100712-thumbnail.jpg?width=640&height=640&fit=bounds)








![[부스트캠프 Tech Talk] 배지연_Structure of Model and Task](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkbaejiyeon-211210113740-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Paper Review] Visualizing and understanding convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/visualizingandunderstandingconvolutionalnetworks-171116075511-thumbnail.jpg?width=640&height=640&fit=bounds)




















