PR-383: Solving ImageNet: a Unified Scheme for Training any Backbone to Top Results
Tensorflow KR PR-12 season4 slide
PR-383: Solving ImageNet: a Unified Scheme for Training any Backbone to Top Results Reviewer: Sunghoon Joo (VUNO Inc.)
Paper link: https://arxiv.org/abs/2204.03475
YouTube link: https://youtu.be/WeYuLO1nTmE
2. Methods
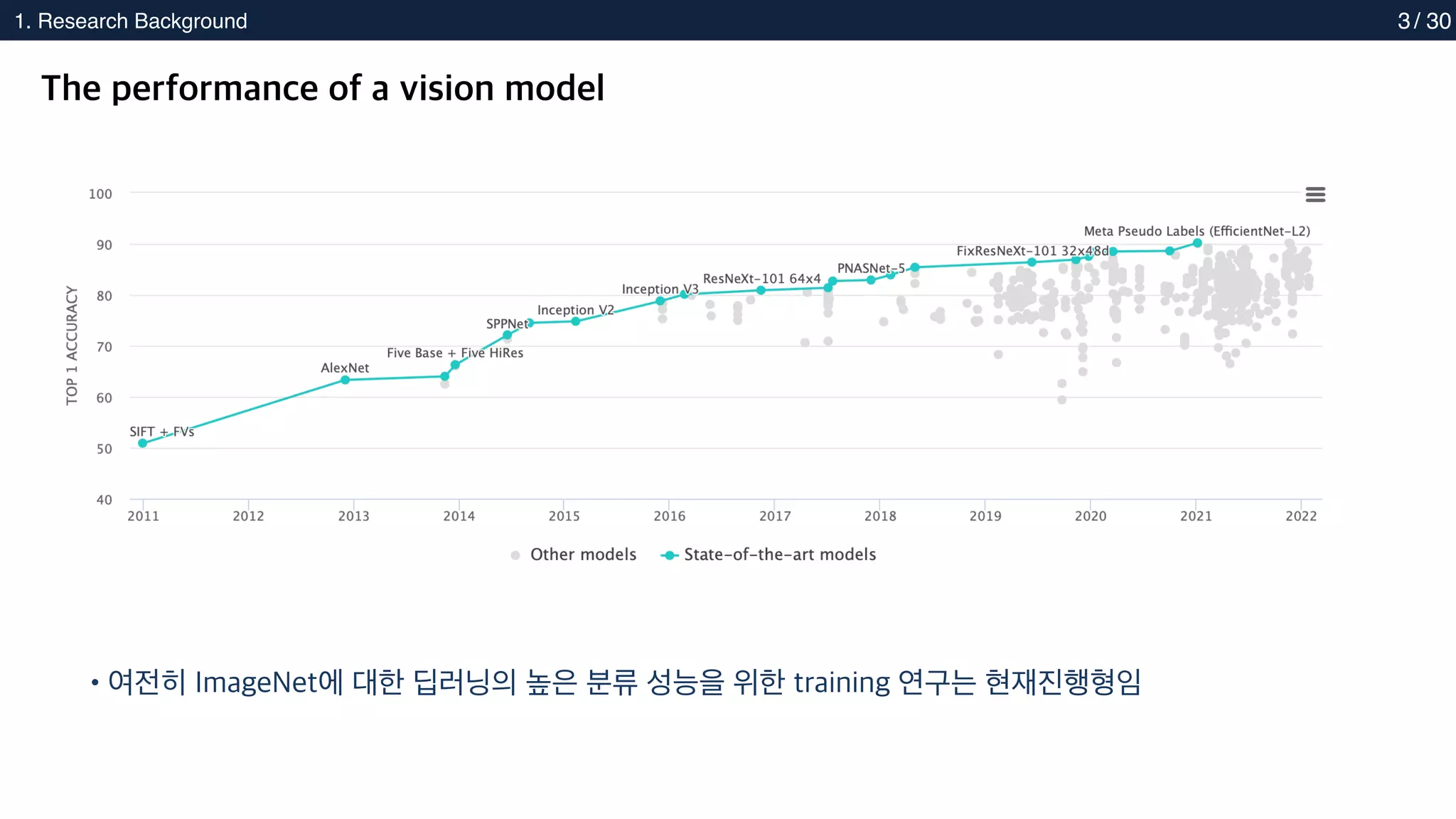
1. ResearchBackground 3
The performance of a vision model
•여전히 ImageNet에 대한 딥러닝의 높은 분류 성능을 위한 training 연구는 현재진행형임
/ 30
4.
2. Methods
1. ResearchBackground 4
Previous works
•Regularizations
•Stronger augmentations: AutoAugment, RandAugment
•Image-based regularizations Cutout, Cutmix and Mixup
•Architecture regularizations like drop-path, drop-block
•Label-smoothing
•Progressive image resizing during training
•Different train-test resolutions
•Training configuration
•More training epochs
•Dedicated optimizer for large batch size(LAMB Optimizer), Scaling learning rate with batch size
•Exponential-moving average (EMA) of model weights
•Improved weights initializations
•Decoupled weight decay (AdamW)
Yun, S. et al., CutMix: Regularization strategy to train strong
classifiers with localizable features. ICCV 2019
Fixing the train-test resolution discrepancy. NeurIPS 2019
/ 30
5.
2. Methods
1. ResearchBackground 5
ResNeXt
Automated architecture search를 활용한 구조
[67 (NASNET), 41 (AmoebaNet: 83.9), 55 (EfficientNet-B7, 84.4%, 2019)].
Adapting self-attention to the visual domain
AA-ResNet-152, 79.1%, 2019
ViT-L/16 87.76±0.03%, 2020
LambdaResNet200 84.3%, 2021
Previous works
•Architecture
VGG
ResNet
Inception
ViT-L/16 87.76±0.03%, 2020
/ 30
6.
2. Methods
1. ResearchBackground 6
Motivation - Architecture와 관계없이 잘 작동하는 training scheme 제안 필요
•Architecture마다 맞춤형 training scheme이 적용됨
•ResNet 계열 (TResNet, SEResNet, ResNet-D …)
•일반적으로 다양한 training scheme에 잘 작동함.
•(Ross Wightman et al., 2021) 에서 제안한 방법이 ResNet 계열을 학습시키는데 standard가 됐다고 함.
•Mobile-oriented models
•Depth-wise convolutions에 많이 의존
•Their dedicated training schemes usually consist of RMSProp optimizer, waterfall learning rate scheduling
and EMA.
•Transformer-based, MLP-only models
•Inductive bias가 없어 훈련하기 어려움 -> longer training (1000 epochs), strong cutmix-mixup and drop-
path regularizations, large weight-decay and repeated augmentations
•어떤 한 모델에 대한 맞춤형 training scheme은 다른 모델에 적용하면 성능이 낮아짐
•ResNet50을 위한 training scheme을 EfficieneNetV2 model에 적용했을 때 맞춤형 training scheme을 적용할 떄 보다
3.3%의 성능 하락을 보임 (Mingxing Tan et al., PMLR, 2021)
/ 30
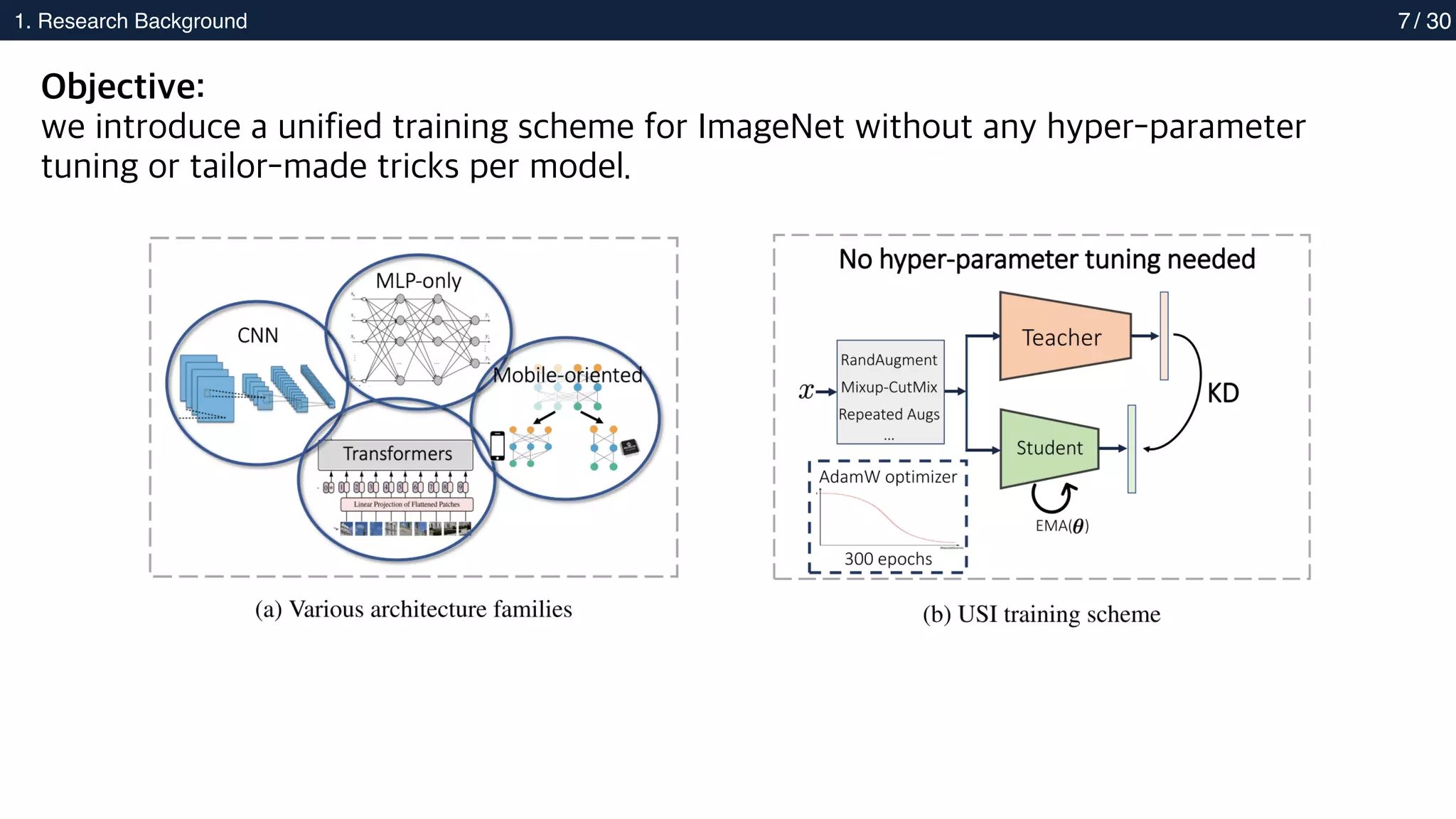
7.
2. Methods
1. ResearchBackground 7
Objective:
we introduce a unified training scheme for ImageNet without any hyper-parameter
tuning or tailor-made tricks per model.
/ 30
2. Methods
2. Methods9
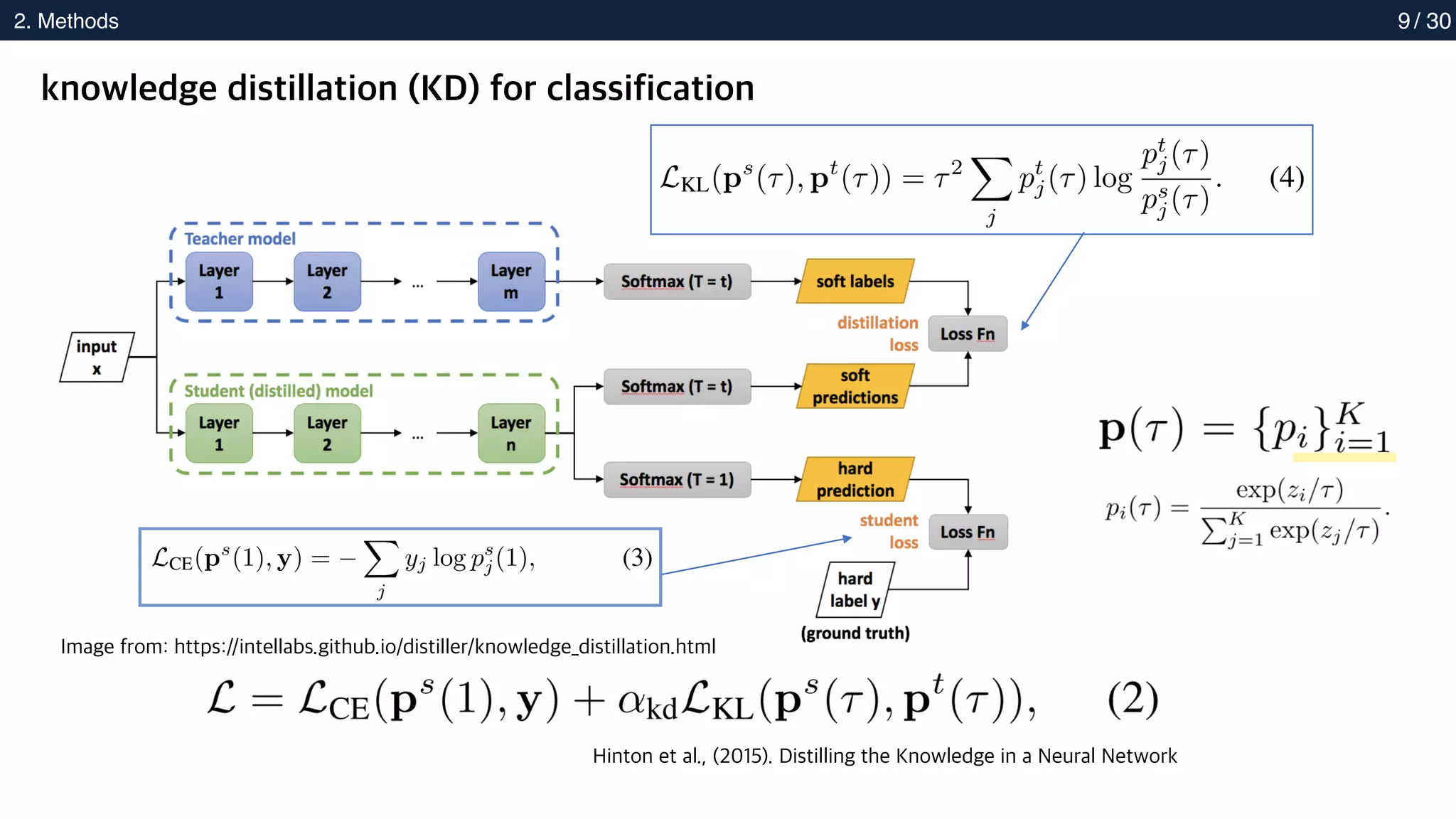
knowledge distillation (KD) for classification
Image from: https://intellabs.github.io/distiller/knowledge_distillation.html
Hinton et al., (2015). Distilling the Knowledge in a Neural Network
/ 30
10.
2. Methods
2. Methods10
knowledge distillation (KD) for classification
•KD의 적용 - Previous work
•Compounding the Performance Improvements of Assembled Techniques in a Convolutional Neural Network, 2021
•ResNet50의 image classification 성능 향상에 KD가 중요한 역할을 함을 보임
•DeIT (PR-297):
•ViT와 같은 구조를 사용하면서 Training 방법 개선과 distillation token을 사용하는 KD를 적용해 ImageNet data 만으로
EfficientNet보다 뛰어난 성능을 보여줌
•Once-for-All: Train One Network and Specialize it for Efficient Deployment, ICLR 2020
•Neural architecture search에 KD를 적용해 cost-effective한 sub-networks 훈련법 제안
•Circumventing outliers of autoaugment with knowledge distillation, ECCV 2020
•KD가 data augmentation에서 발생하는 noise를 줄여줌에 따라 더 강한 augmentation 적용이 가능함을 보임
•However, KD is not a common practice for ImageNet training.
/ 30
11.
2. Methods
2. Methods11
insight and motivation into the impact of KD
•Wing, warplane : Teacher network은 image가 완전히 mutually-exclusive하지 않은 case를 보완한다
•(c) hen 55.5% 사람이 봐도 애매한데 그 애매함을 teacher의 classification 결과가 반영한다.
•(d) Task로 보면 틀린 답안이지만 English setter가 이미지에서 main object라고 볼 수 있음
ImageNet ground-truth label Hen: 암탉, cock: 수탉, forklift: 지게차
English setter, Gordon setter: 개의 품종
Ice lolly : 아이스크림
/ 30
12.
2. Methods
2. Methods12
insight and motivation into the impact of KD
•Teacher label에 ground truth label보다 더 많은 정보가 포함되어 있음 (class간의 유사성과 상관관계)
•Label error를 보정할 수 있음, Label smoothing을 따로 할 필요가 없음
•Lead to a more effective and robust optimization process, compared to training with hard-labels only.
ImageNet ground-truth label Hen: 암탉, cock: 수탉, forklift: 지게차
English setter, Gordon setter: 개의 품종
Ice lolly : 아이스크림
/ 30
13.
2. Methods
2. Methods13
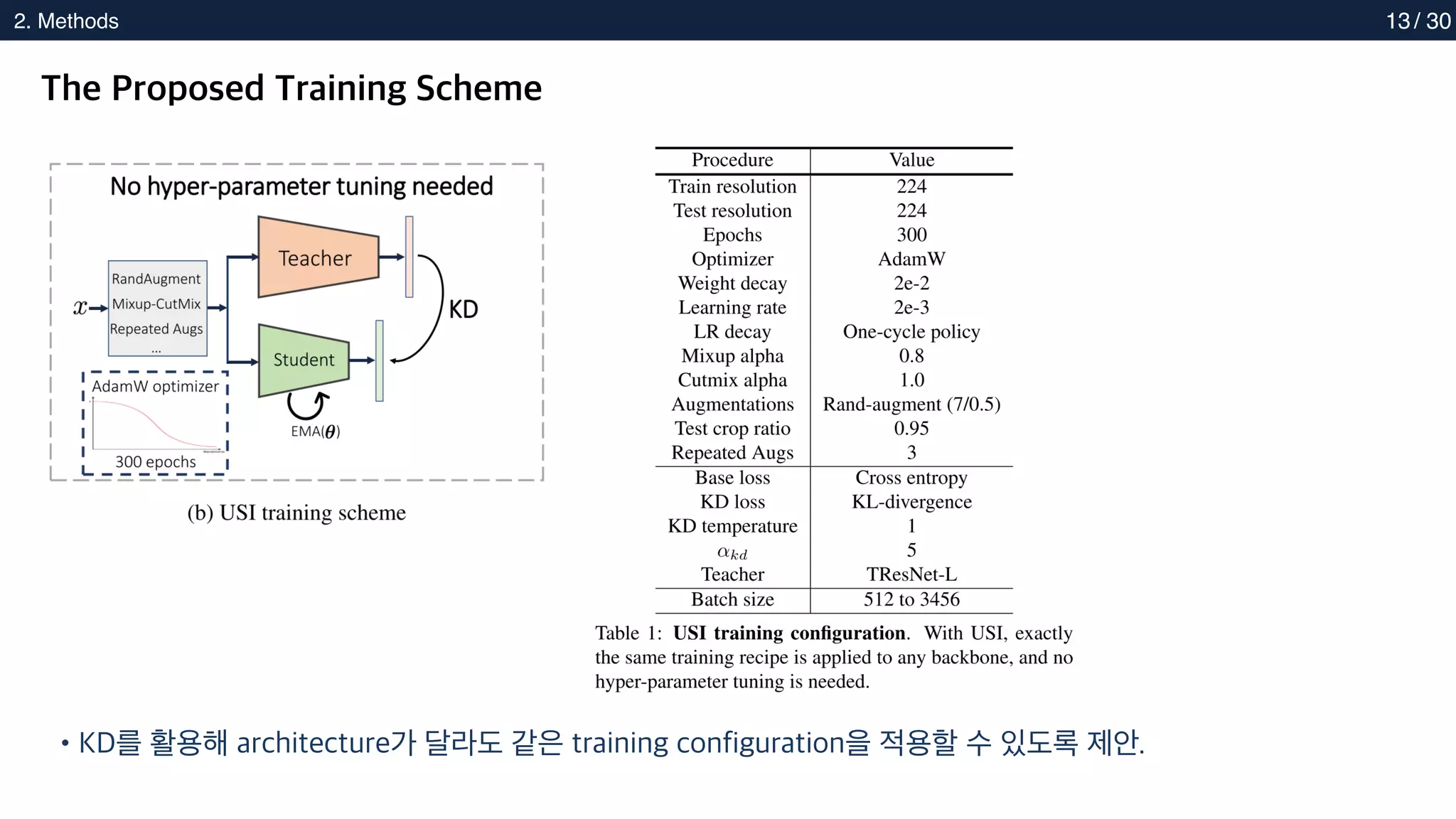
The Proposed Training Scheme
•KD를 활용해 architecture가 달라도 같은 training configuration을 적용할 수 있도록 제안.
/ 30
2. Methods
3. ExperimentalResults 15
•USI의 robustness 검증
•제안한 training scheme (KD), loss function이 잘 작동함을 확인
•추가로 성능 향상할 수 있는 방법 제안
•Application: Speed-Accuracy comparison
/ 30
16.
2. Methods
3. ExperimentalResults 16
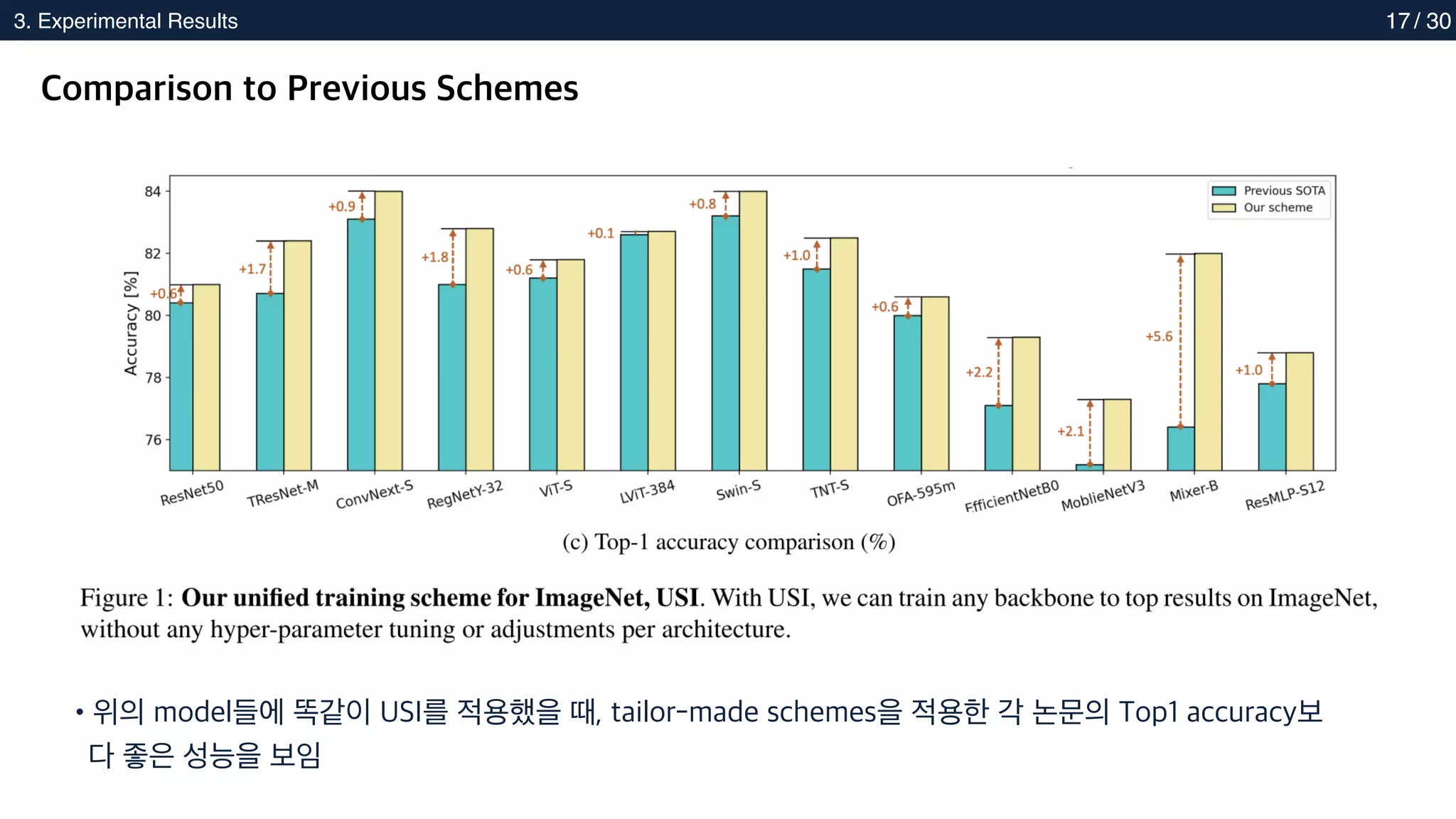
Comparison to Previous Schemes
•위의 model들에 똑같이 USI를 적용했을 때, tailor-made schemes을 적용한 각 논문의 Top1 accuracy보
다 좋은 성능을 보임
/ 30
17.
2. Methods
3. ExperimentalResults 17
Comparison to Previous Schemes
•위의 model들에 똑같이 USI를 적용했을 때, tailor-made schemes을 적용한 각 논문의 Top1 accuracy보
다 좋은 성능을 보임
/ 30
18.
2. Methods
3. ExperimentalResults 18
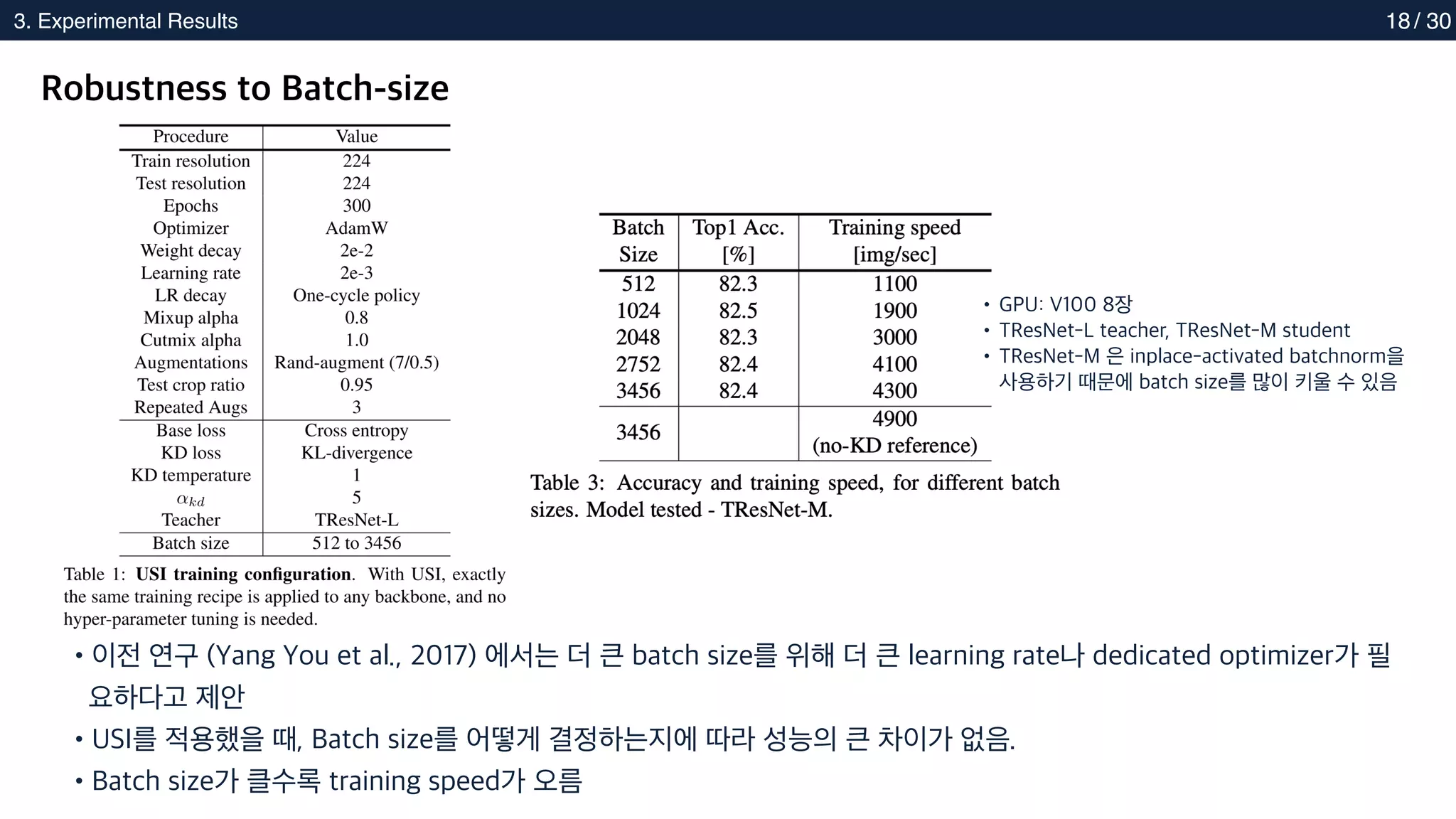
Robustness to Batch-size
•이전 연구 (Yang You et al., 2017) 에서는 더 큰 batch size를 위해 더 큰 learning rate나 dedicated optimizer가 필
요하다고 제안
•USI를 적용했을 때, Batch size를 어떻게 결정하는지에 따라 성능의 큰 차이가 없음.
•Batch size가 클수록 training speed가 오름
• GPU: V100 8장
• TResNet-L teacher, TResNet-M student
• TResNet-M 은 inplace-activated batchnorm을
사용하기 때문에 batch size를 많이 키울 수 있음
/ 30
19.
2. Methods
3. ExperimentalResults 19
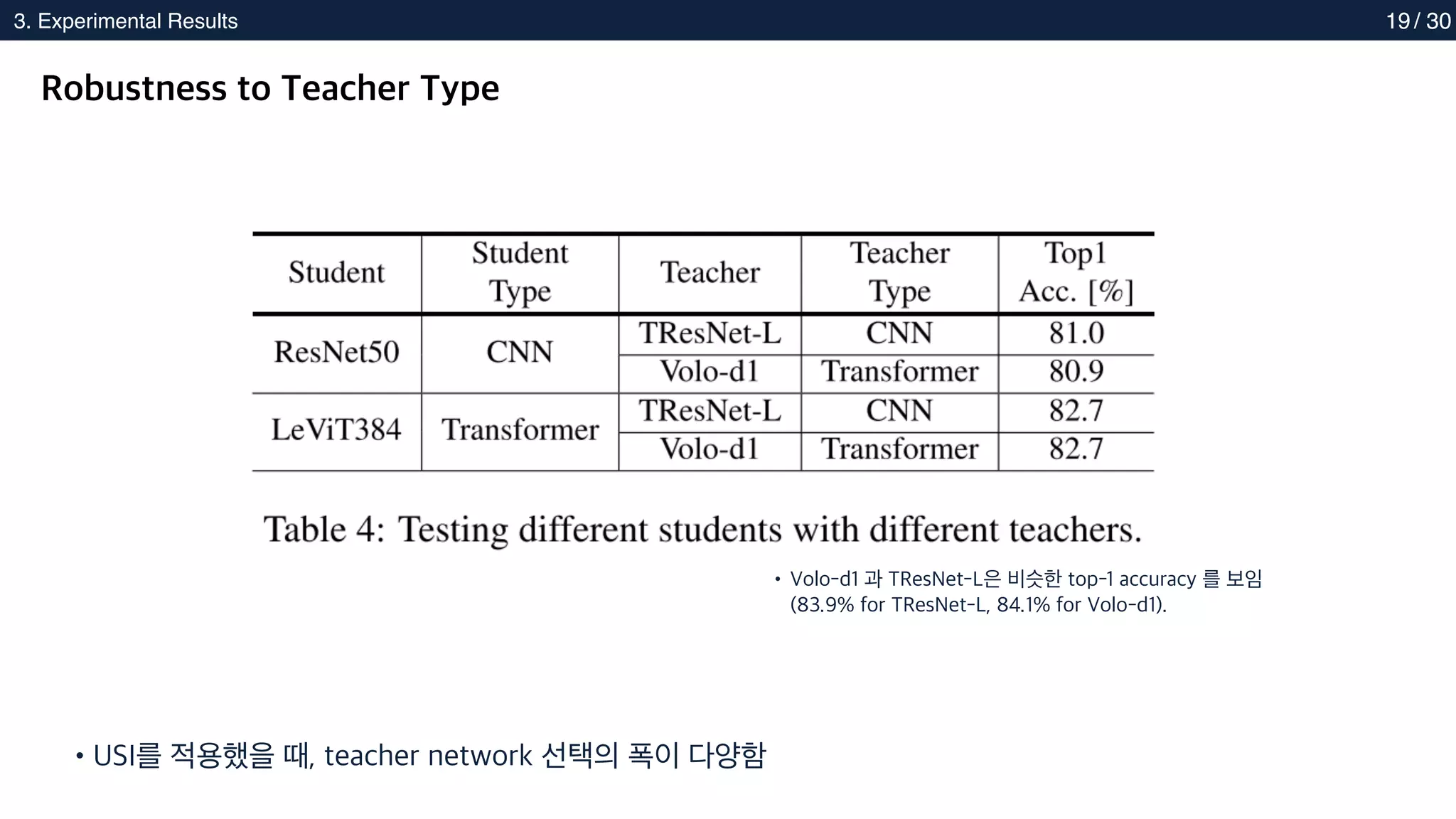
Robustness to Teacher Type
•USI를 적용했을 때, teacher network 선택의 폭이 다양함
• Volo-d1 과 TResNet-L은 비슷한 top-1 accuracy 를 보임
(83.9% for TResNet-L, 84.1% for Volo-d1).
/ 30
20.
2. Methods
3. ExperimentalResults 20
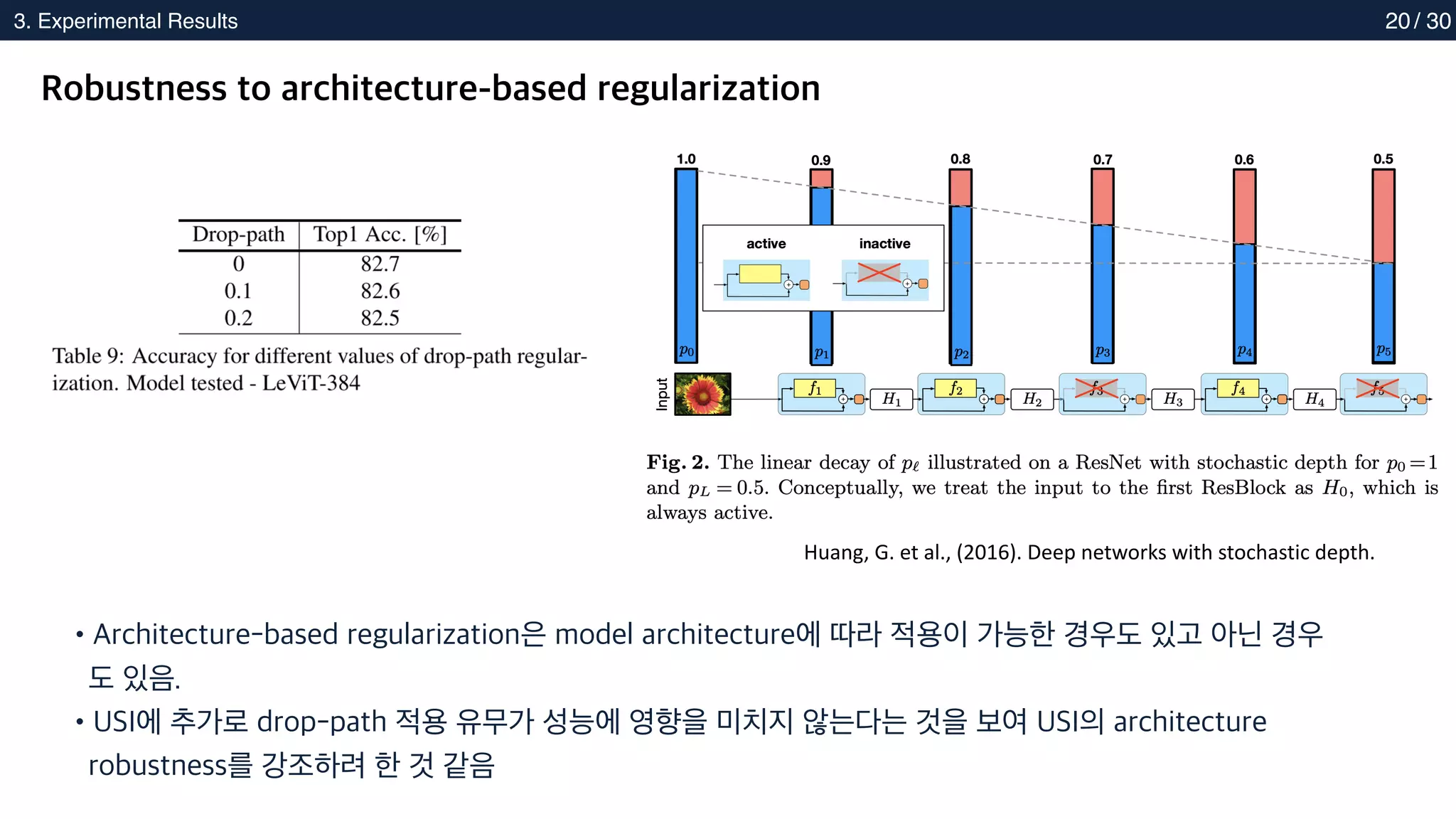
Robustness to architecture-based regularization
•Architecture-based regularization은 model architecture에 따라 적용이 가능한 경우도 있고 아닌 경우
도 있음.
•USI에 추가로 drop-path 적용 유무가 성능에 영향을 미치지 않는다는 것을 보여 USI의 architecture
robustness를 강조하려 한 것 같음
Huang, G. et al., (2016). Deep networks with stochastic depth.
/ 30
21.
2. Methods
3. ExperimentalResults 21
•USI의 robustness 검증
•제안한 training scheme (KD), loss function이 잘 작동함을 확인
•추가로 성능 향상할 수 있는 방법 제안
•Application: Speed-Accuracy comparison
/ 30
22.
2. Methods
3. ExperimentalResults 22
Ablations about loss function
•ImageNet training에서 KD가 효과적임을 입증
6.5% less than accuracy with the default
(Default)
•Relative weight αkd
/ 30
23.
2. Methods
3. ExperimentalResults 23
Ablations about loss function
•Vanilla softmax probabilities를 사용하는 것이 좋음
τ < 1 (sharpening the teacher predictions)
•KD Temperature (τ)
τ > 1 (softening the teacher predictions)
Class마다의 softmax output의 차이가 줄어듦
/ 30
24.
2. Methods
3. ExperimentalResults 24
•USI의 robustness 검증
•제안한 training scheme (KD), loss function이 잘 작동함을 확인
•추가로 성능 향상할 수 있는 방법 제안
•Application: Speed-Accuracy comparison
/ 30
25.
2. Methods
3. ExperimentalResults 25
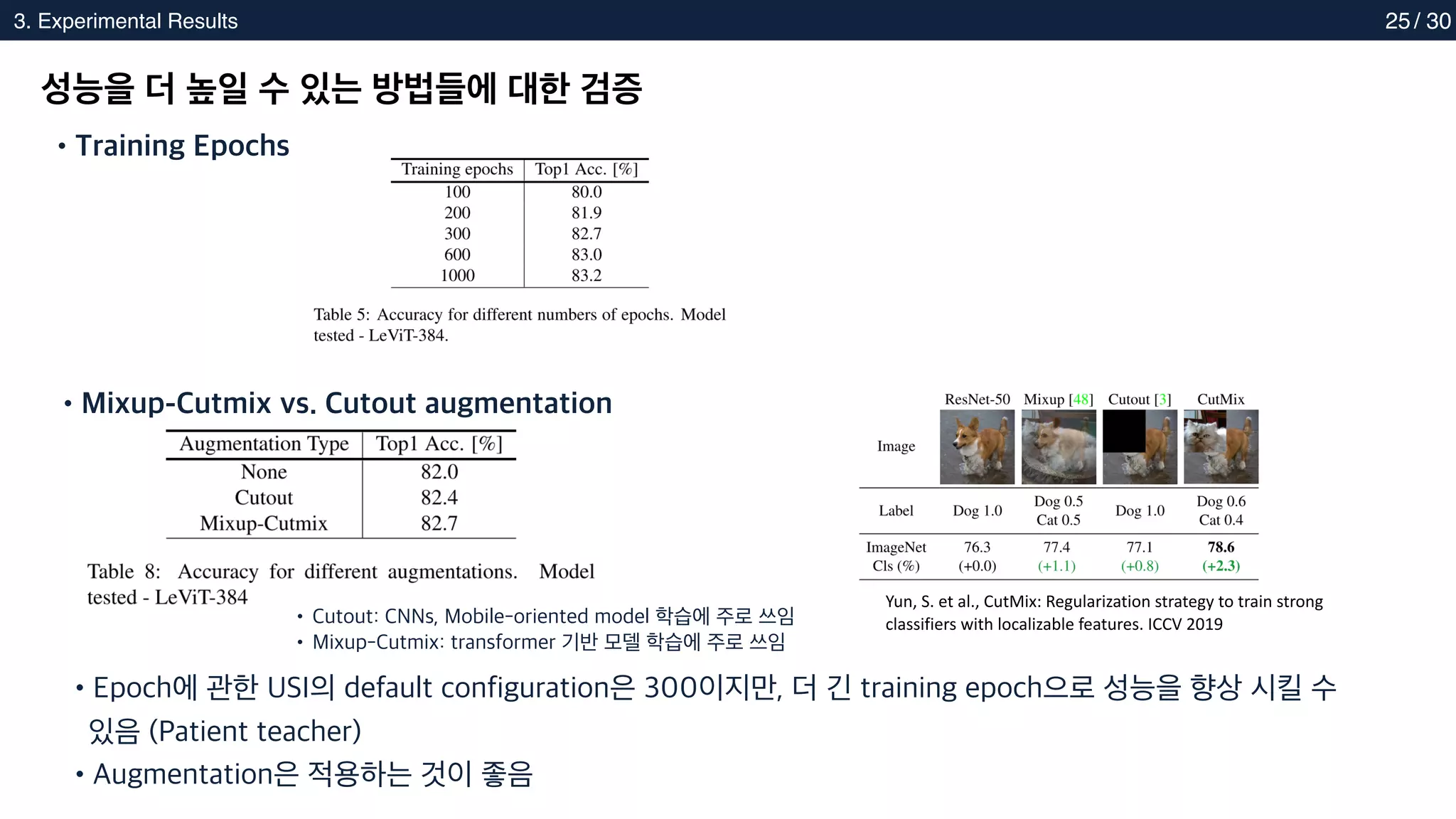
성능을 더 높일 수 있는 방법들에 대한 검증
•Epoch에 관한 USI의 default configuration은 300이지만, 더 긴 training epoch으로 성능을 향상 시킬 수
있음 (Patient teacher)
•Training Epochs
•Mixup-Cutmix vs. Cutout augmentation
Yun, S. et al., CutMix: Regularization strategy to train strong
classifiers with localizable features. ICCV 2019
• Cutout: CNNs, Mobile-oriented model 학습에 주로 쓰임
• Mixup-Cutmix: transformer 기반 모델 학습에 주로 쓰임
•Augmentation은 적용하는 것이 좋음
/ 30
26.
2. Methods
3. ExperimentalResults 26
•USI의 robustness 검증
•제안한 training scheme (KD), loss function이 잘 작동함을 확인
•추가로 성능 향상할 수 있는 방법 제안
•Application: Speed-Accuracy comparison
/ 30
27.
2. Methods
3. ExperimentalResults 27
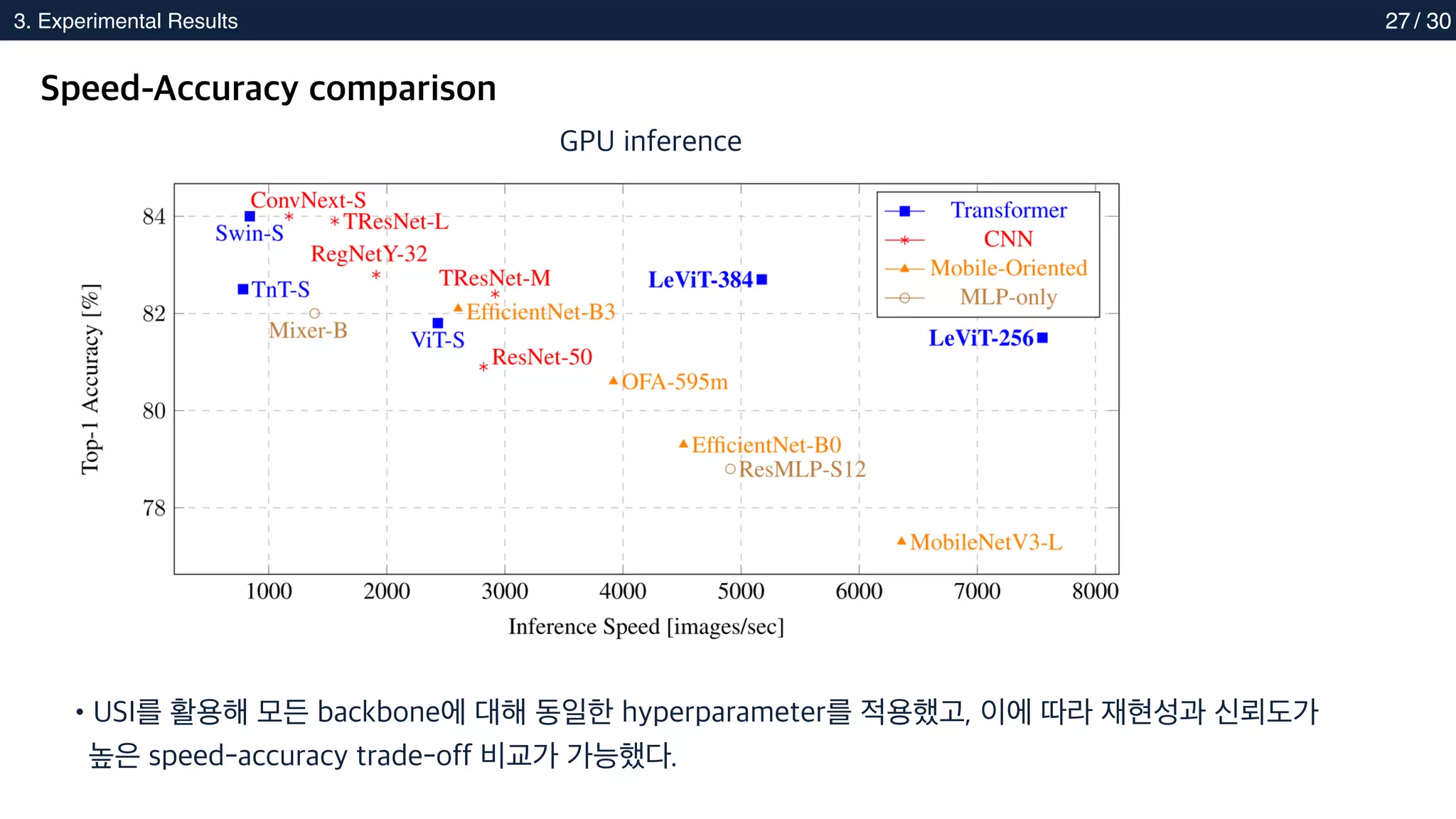
Speed-Accuracy comparison
•USI를 활용해 모든 backbone에 대해 동일한 hyperparameter를 적용했고, 이에 따라 재현성과 신뢰도가
높은 speed-accuracy trade-off 비교가 가능했다.
GPU inference
/ 30
28.
2. Methods
3. ExperimentalResults 28
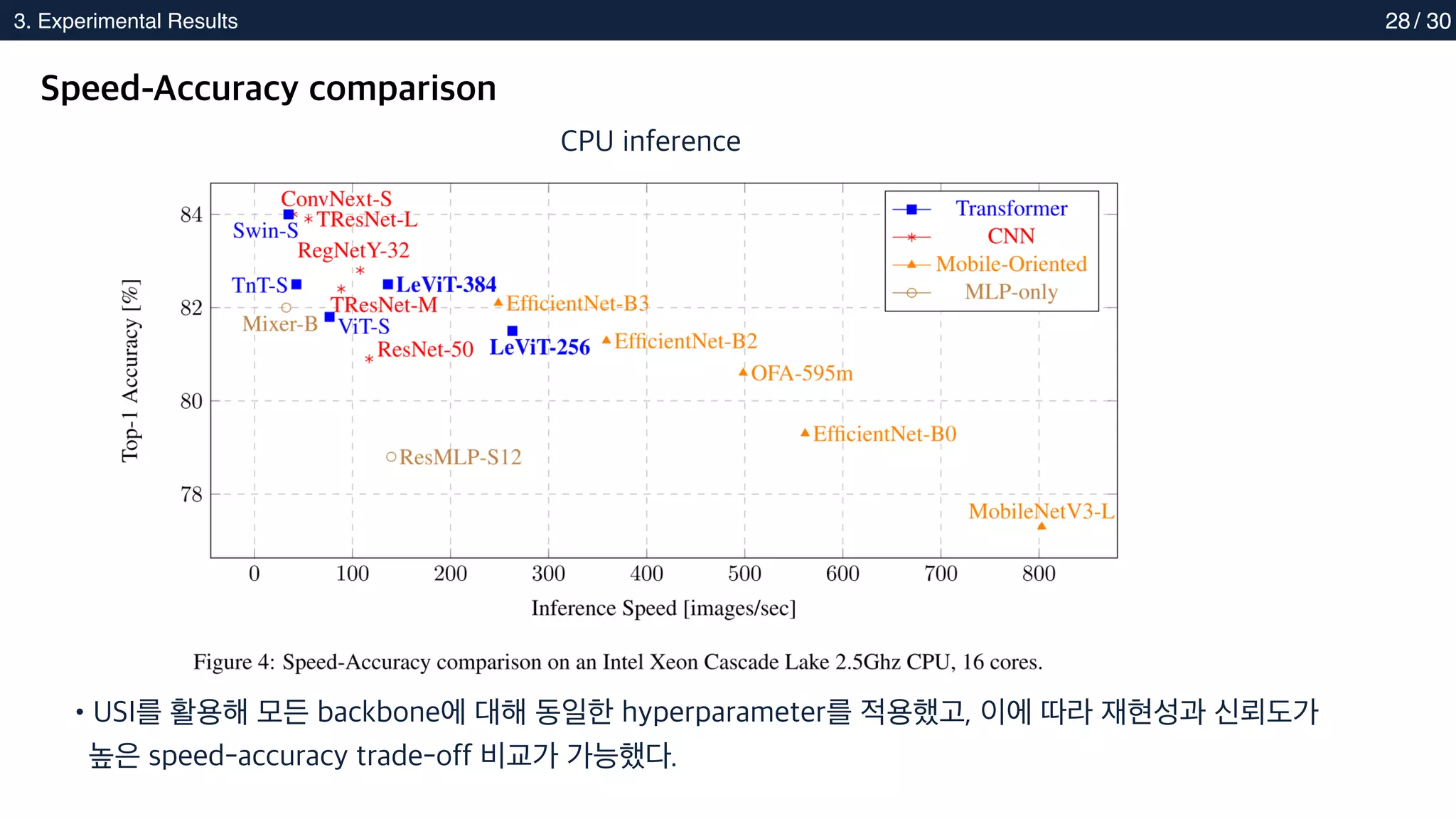
Speed-Accuracy comparison
•USI를 활용해 모든 backbone에 대해 동일한 hyperparameter를 적용했고, 이에 따라 재현성과 신뢰도가
높은 speed-accuracy trade-off 비교가 가능했다.
CPU inference
/ 30
2. Methods
4. Conclusions30
• Main contribution
• (1) We introduce a unified, efficient training scheme for ImageNet dataset, USI, that
does not require hyperparameter tuning.
• (2) We show it consistently and reliably achieves state-of-the-art results, compared
to tailor-made schemes per model (ResNet-like, Mobile-oriented, Transformer-
based and MLP-only models).
• (3) We use USI to perform a methodological speed-accuracy comparison of modern
deep learning models, and identify efficient backbones along the Pareto curve.
• 다른 classification dataset로의 확장성에 대한 논의: 이 논문의 parameter (high learning rate,
training epoch, strong augmentation)를 바로 활용하기는 어렵겠지만, KD의 적용 자체는 이점이
있을 것으로 예상
/ 30
Thank you.


![2. Methods
1. Research Background 5
ResNeXt
Automated architecture search를 활용한 구조
[67 (NASNET), 41 (AmoebaNet: 83.9), 55 (EfficientNet-B7, 84.4%, 2019)].
Adapting self-attention to the visual domain
AA-ResNet-152, 79.1%, 2019
ViT-L/16 87.76±0.03%, 2020
LambdaResNet200 84.3%, 2021
Previous works
•Architecture
VGG
ResNet
Inception
ViT-L/16 87.76±0.03%, 2020
/ 30](https://image.slidesharecdn.com/pr383usijoo-220425011547/75/PR-383-Solving-ImageNet-a-Unified-Scheme-for-Training-any-Backbone-to-Top-Results-5-2048.jpg)