개인적 의견
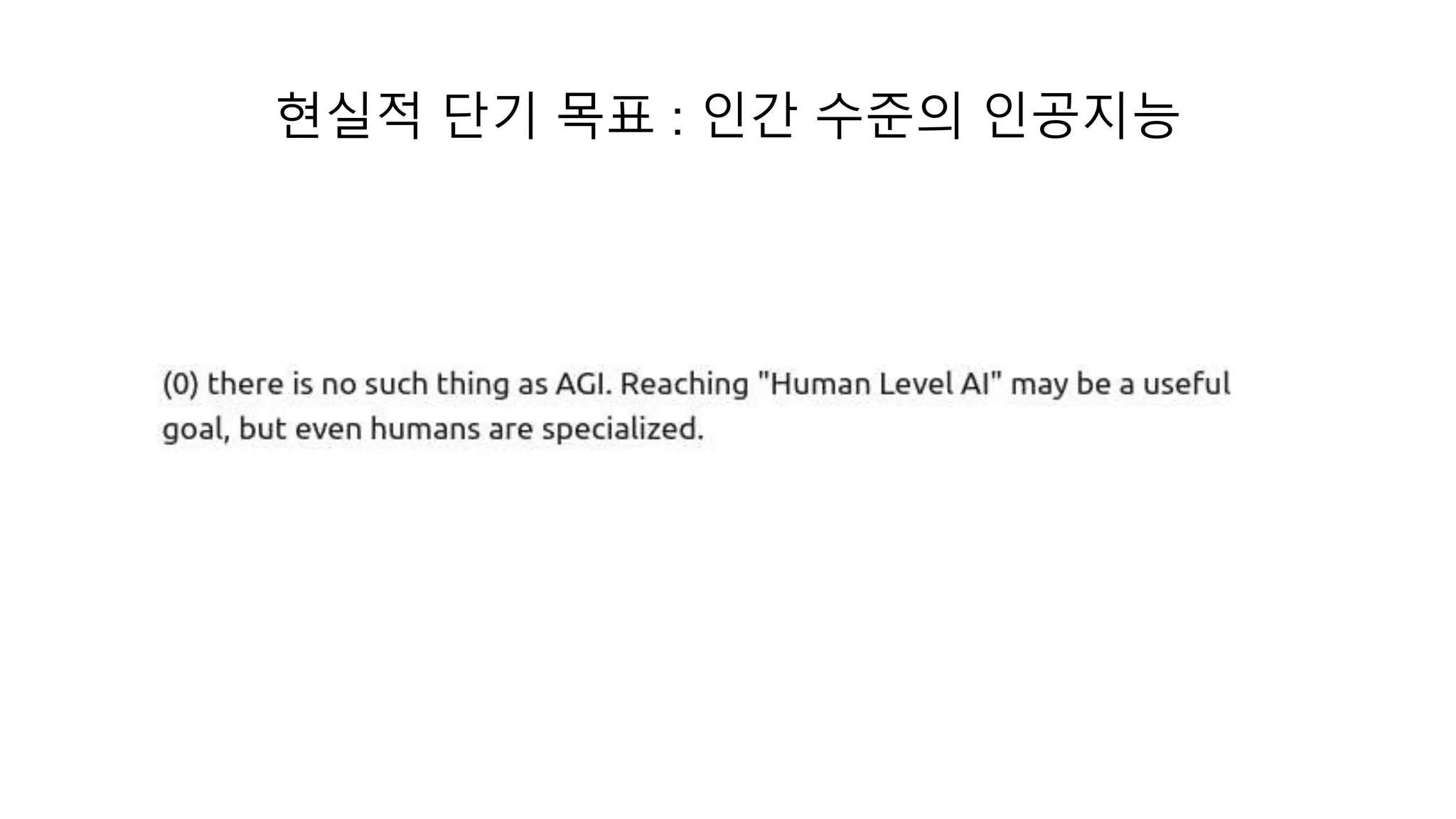
- 약인공지능은거의 정복된 것 같다
- 현재 딥러닝으로 풀기 힘든 문제들?
- 데이터가 너무 적은 경우
- 문제 자체가 매우 복잡한 경우 (long term dependency, very multimodal)
- 단순한 scaling/architecture 변환으로 해결 할 수 있을까?
어떻게 할까?
- 아기처럼세상을 관찰
- 환경과 상호작용하며 계획을
짤 줄 알아야 함
- Gradient based learning과
호환 가능해야함
7.
아기처럼 세상을 관찰
-아기가 보는 세상은 label이 없다 → self-supervised learning
- 아기는 여러가지 감각을 활용해 세상을 본다 → multimodal deep learning
- 환경과 상호작용하며 계획을 짤 줄 알아야 함 → RL/Decision Transformer
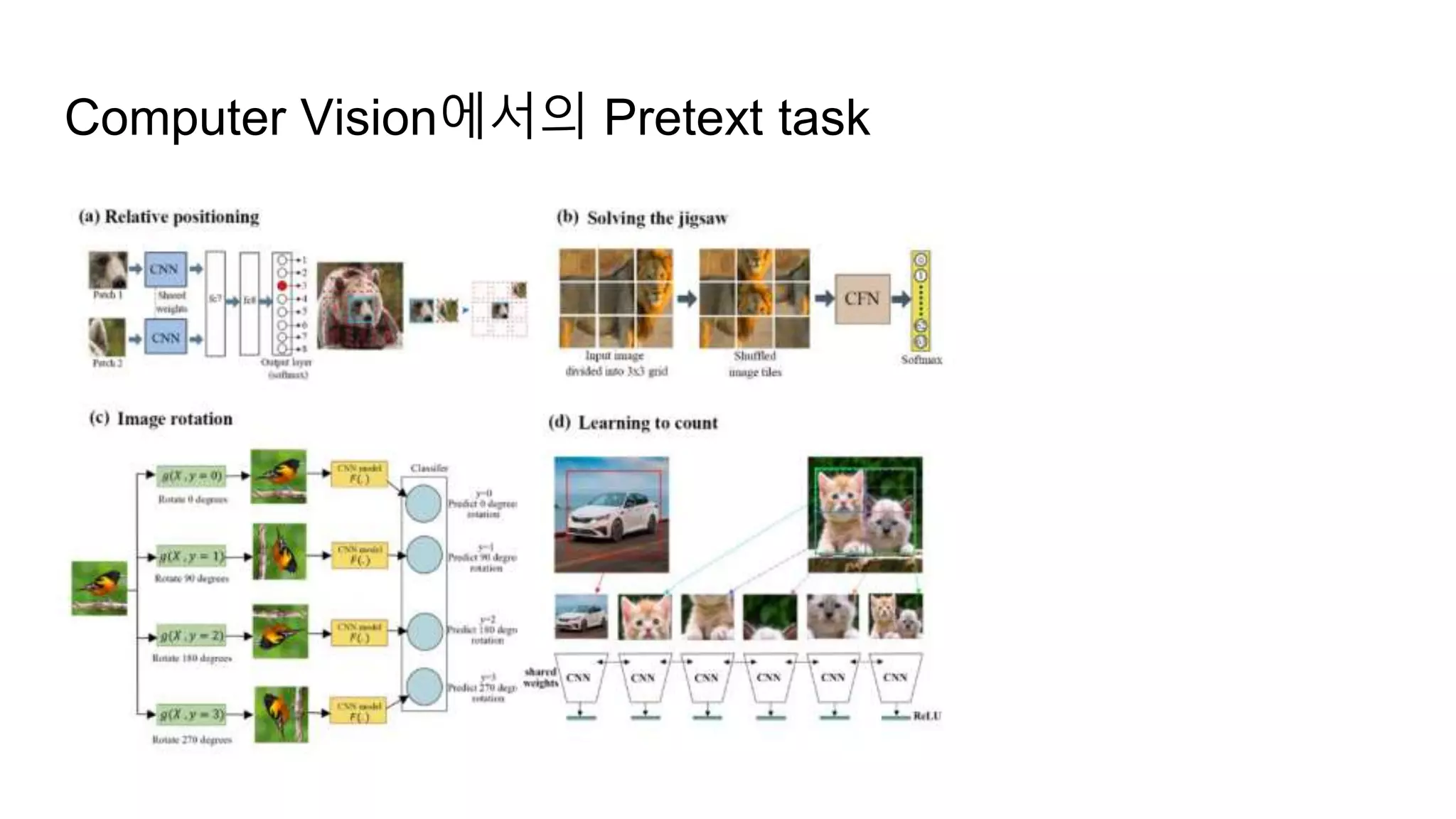
Self supervised learning이란?
-Unsupervised Learning의 한 종류
- Pretext task를 정해, unlabeled 데이터셋을 사용하여 학습
- 데이터 자체의 정보를 적당히 변형/사용하여 supervision으로 쓴다
- Pretext task의 선정이 가장 중요!
NLP에서 성공적이었던 두가지pretext task를 쓰면 안될까?
- 일단 Autoregressive learning의 경우, image의 nature 자체가 time series data
가 아니기에 적용 불가
- Video쪽 foundational model이 나온다면 AR 방식을 쓸지도?
- Masked Autoencoder는 어떨까?
19.
Image에서 mask prediction이어려운 이유
- Uncertainty의 어려움이 가장 큰 문제
- NLP에서는 mask에 들어갈 수 있는 단어가 discrete하고 한정되어있음
- 그렇기에 classification task로 접근 가능
- CV에서 mask는 high dimensional하고 continuous함 → uncertainty가 너무 심
함
20.
Mask Prediction (DenoisingAutoencoder) 뜯어보기
- Mask Prediction은 Energy based model의 일종으로 볼 수 있음
- 부가 설명: http://helper.ipam.ucla.edu/publications/mlpws4/mlpws4_15927.pdf
- Energy Based Model 이라하면, data pair가 있을 때, 둘이 compatible한 쌍인
지 아닌지를 구별할 수 있다는 소리
- 무슨 소린지는 칠판에서…
Data2Vec에서 가장 중요한2가지
- Byol과 비슷한 momentum encoder로 trivial solution 해결
- Reconstruction이 아닌, latent network representation prediction으로 접근
- CV/Audio에서 겪는 high dimension에서 오는 uncertainty 문제 해결
- 그러면서도 성능도 좋음 (NLP task에서 RoberTa를 이긴건 놀라웠음)
그래도 해보자!
- VITArchitecture을 이용해 encoding
- 75%를 random masking
- 16x16 path로 쪼개고 75% random
- masking ratio가 놀랍게도 큰데, 작을 경우
interpolation등으로 추론해 semantic한 정보
학습이 어려움
29.
한계
A school busis parked on a grey road
A school bus is parked on a [mask] road
위 둘은 완전히 다름 (Semantic segment vs
Pixel)
30.
얘기할거리
- Self SupervisedLearning이 미래다
- 특히 Mask prediction/Autoregressive한 학습은 인간과 매우 유사한듯
- NLP와 달리, CV/Audio은 이거다 싶은 pretext task가 아직 없다
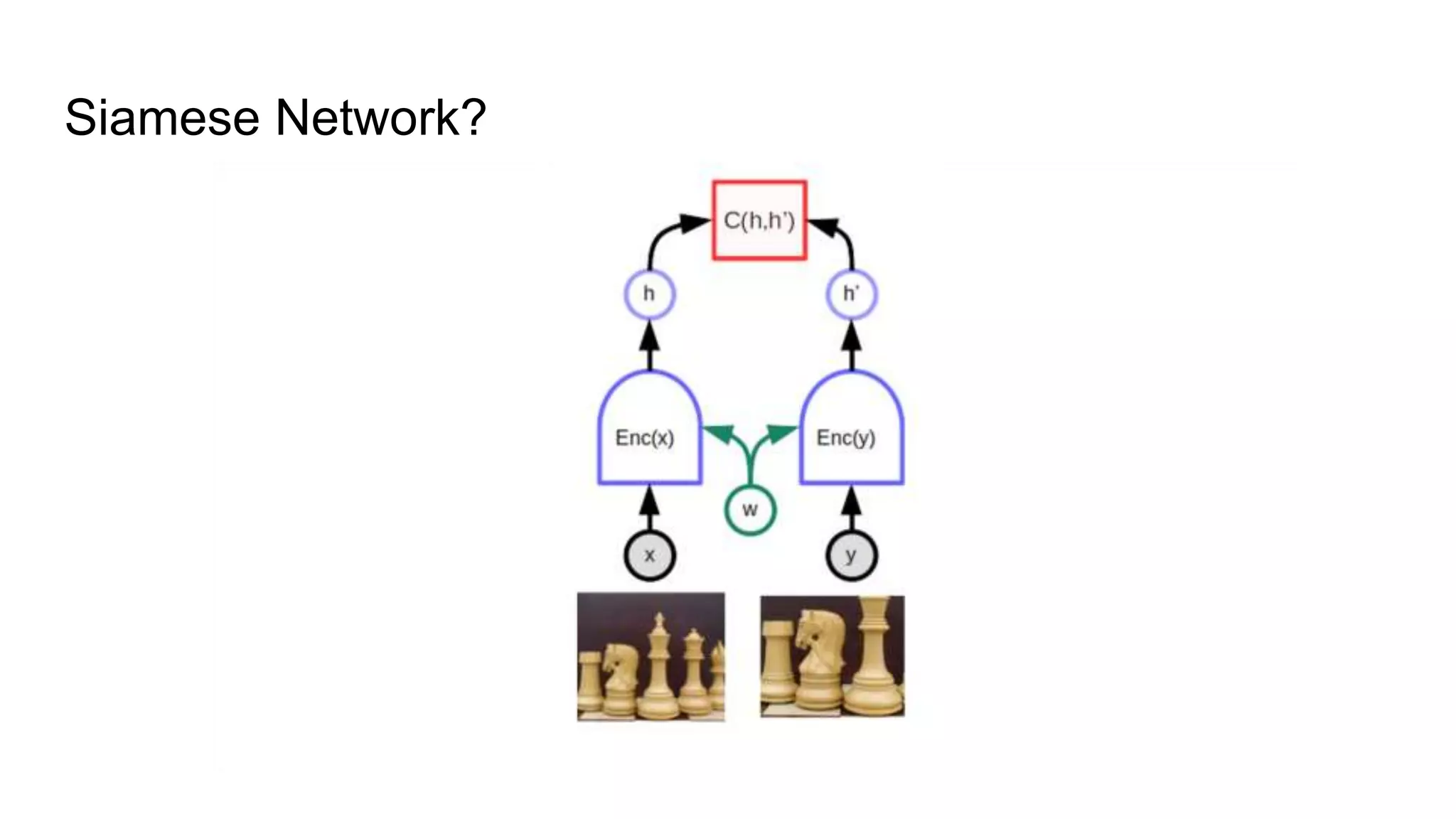
- Siamese Network를 쓰는 방식은 뭔가 찝찝하다 → 간단하지 못하달까?
- 한계를 인지하면서도 Masked Autoencoder 논문이 나온 이유가 이것 아닐까?
- Multimodal한 Self Supervised learning이 답일지도?
- 다음 시간에 얘기할 CLIP, COCA























![한계
A school bus is parked on a grey road
A school bus is parked on a [mask] road
위 둘은 완전히 다름 (Semantic segment vs
Pixel)](https://image.slidesharecdn.com/selfsupervisedlearning-220613075315-fb4cae93/75/Self-Supervised-Learning-pptx-29-2048.jpg)
















![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)
































