More Related Content

PPTX
マルコフ連鎖モンテカルロ法 (2/3はベイズ推定の話) 
PDF
自由エネルギー原理と視覚的意識 2019-06-08 
PDF

PDF

PDF

PDF
駒場学部講義2018 「意識の神経科学と自由エネルギー原理」講義スライド 
PDF
明日から読める無作為化比較試験: �行動療法研究に求められる統計学 
PDF
Rによるやさしい統計学第20章「検定力分析によるサンプルサイズの決定」 What's hot

PDF

PDF

PDF

PPTX

PDF

PPTX
Imputation of Missing Values using Random Forest 
PDF

PPTX

PPTX

PDF
クラシックな機械学習入門:付録:よく使う線形代数の公式 
PDF
PRML復々習レーン#2 2.3.6 - 2.3.7 
PDF

PDF
Rパッケージ“KFAS”を使った時系列データの解析方法 
PDF

PDF

PPTX
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル 
ZIP

PPTX

PDF
FEPチュートリアル2021 講義3 「潜在変数が連続値、生成モデルが正規分布の場合」の改良版 
PDF
Viewers also liked

PDF

PPTX

PDF

PPTX
Fluentd,mongo db,rでお手軽ログ解析環境 
PDF
Collaborativefilteringwith r 
PDF

PDF

PPTX
Similar to 「plyrパッケージで君も前処理スタ☆」改め「plyrパッケージ徹底入門」

PDF

PDF
R入門(dplyrでデータ加工)-TokyoR42 
PDF
20170923 excelユーザーのためのr入門 
PDF

PDF

PDF

PDF
Tokyor60 r data_science_part1 
PPTX

PDF

PDF

PDF

PPTX

PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章 
PDF

DOCX

PDF

PDF

PPT

PDF

PDF
More from Nagi Teramo

PDF

PDF

PPTX
Reproducebility 100倍 Dockerマン 
PDF
healthplanetパッケージで�体組成データを手に入れて�健康な体も手に入れる 
PDF

PDF

PDF
続わかりやすいパターン認識11章(11.1 - 11.4) 
PDF

PDF

PDF

PDF

PDF
東京R非公式おじさんが教える本当に気持ちいいパッケージ作成法 
PDF

PDF
Trading volume mapping R in recent environment 
PDF
~knitr+pandocではじめる~『R MarkdownでReproducible Research』 
PDF

PDF
可視化周辺の進化がヤヴァイ~rChartsを中心として~ 
PDF
Tokyo.R 白熱教室「これからのRcppの話をしよう」 
PDF

PDF
「plyrパッケージで君も前処理スタ☆」改め「plyrパッケージ徹底入門」
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
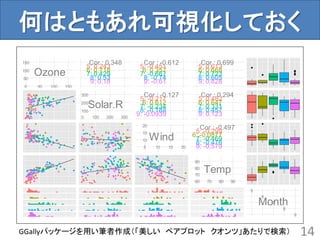
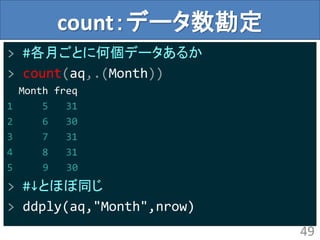
何はともあれ可視化しておく
14
Ozone50
100
150
0 50 100150
Cor : 0.348
5: 0.243
6: 0.718
7: 0.429
8: 0.53
9: 0.18
Cor : -0.612
5: -0.451
6: 0.357
7: -0.667
8: -0.74
9: -0.61
Cor : 0.699
5: 0.613
6: 0.668
7: 0.723
8: 0.605
9: 0.828
Solar.R100
200
300
0 100 200 300
Cor : -0.127
5: -0.217
6: 0.612
7: -0.234
8: -0.188
9: -0.0939
Cor : 0.294
5: 0.482
6: 0.647
7: 0.331
8: 0.457
9: 0.123
Wind10
15
20
5 10 15 20
Cor : -0.497
5: -0.299
6: -0.0877
7: -0.469
8: -0.476
9: -0.579
Temp70
80
90
60 70 80 90
Month
5
6
7
8
9
GGallyパッケージを用い筆者作成(「美しい ペアプロット クオンツ」あたりで検索)
- 15.
- 16.
- 17.
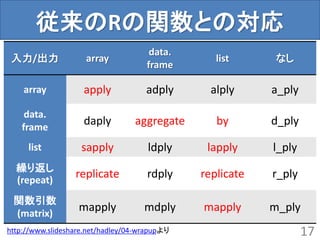
従来のRの関数との対応
入力/出力 array
data.
frame
list なし
arrayapply adply alply a_ply
data.
frame
daply aggregate by d_ply
list sapply ldply lapply l_ply
繰り返し
(repeat)
replicate rdply replicate r_ply
関数引数
(matrix)
mapply mdply mapply m_ply
17http://www.slideshare.net/hadley/04-wrapupより
- 18.
- 19.
- 20.
- 21.
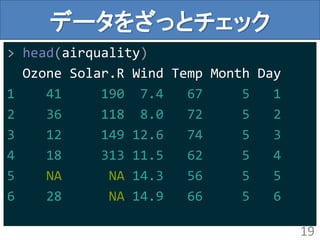
ddply関数でやってみる
> #名前を短くしておく
> aq<- airquality
> #月ごとの平均気温を出す
> ddply(aq,"Month“,summarize,
AveTemp=mean(Temp))
Month AveTemp
1 5 65.54839
2 6 79.10000
………………………
21
- 22.
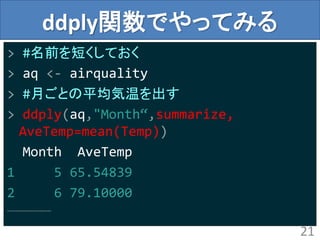
忘れちゃいけないplyrの思想
> #名前を短くしておく
> aq<- airquality
> #月ごとの平均気温を出す
> ddply(aq,"Month“,summarize,
AveTemp=mean(Temp))
Month AveTemp
1 5 65.54839
2 6 79.10000
………………………
22
•Split(分割)
•月(Month)毎に
•Apply(適用)
•気温(Temp)の平均を算出し
•Combine(結合)
•data.frameとして戻す
- 23.
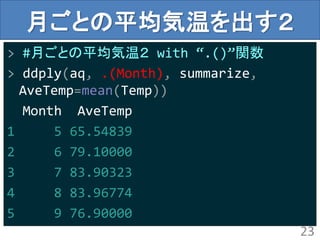
月ごとの平均気温を出す2
> #月ごとの平均気温2 with“.()”関数
> ddply(aq, .(Month), summarize,
AveTemp=mean(Temp))
Month AveTemp
1 5 65.54839
2 6 79.10000
3 7 83.90323
4 8 83.96774
5 9 76.90000
23
- 24.
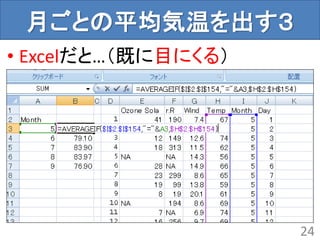
- 25.
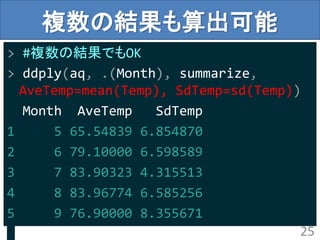
複数の結果も算出可能
> #複数の結果でもOK
> ddply(aq,.(Month), summarize,
AveTemp=mean(Temp), SdTemp=sd(Temp))
Month AveTemp SdTemp
1 5 65.54839 6.854870
2 6 79.10000 6.598589
3 7 83.90323 4.315513
4 8 83.96774 6.585256
5 9 76.90000 8.355671
25
- 26.
- 27.
- 28.
- 29.
プログレスバーも導入可能
> ddply(aq, .(Month),summarize,
AveTemp=mean(Temp), .progress="text")
|===============================| 100%
Month AveTemp
1 5 65.54839
2 6 79.10000
3 7 83.90323
4 8 83.96774
5 9 76.90000
29
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
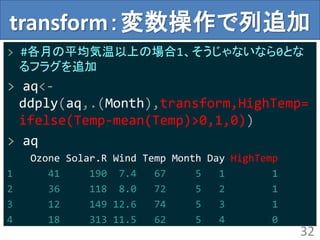
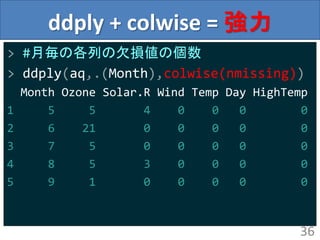
ddply + colwise= 強力
> #月毎の各列の欠損値の個数
> ddply(aq,.(Month),colwise(nmissing))
Month Ozone Solar.R Wind Temp Day HighTemp
1 5 5 4 0 0 0 0
2 6 21 0 0 0 0 0
3 7 5 0 0 0 0 0
4 8 5 3 0 0 0 0
5 9 1 0 0 0 0 0
36
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
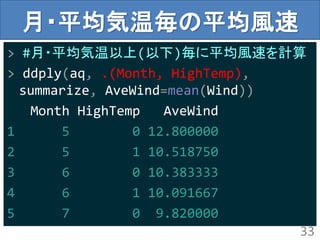
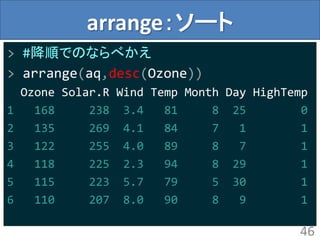
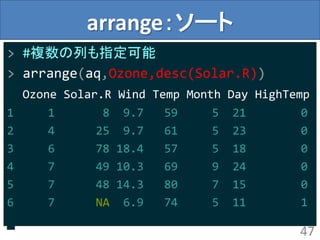
arrange:ソート
> arrange(aq,Ozone)
Ozone Solar.RWind Temp Month Day HighTemp
1 1 8 9.7 59 5 21 0
2 4 25 9.7 61 5 23 0
3 6 78 18.4 57 5 18 0
4 7 NA 6.9 74 5 11 1
5 7 48 14.3 80 7 15 0
> #普通にRで書くならこんなかんじ
> aq[with(aq,order(Ozone)),]
45
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
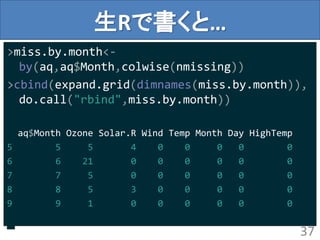
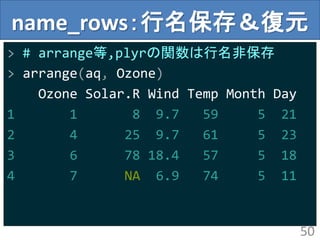
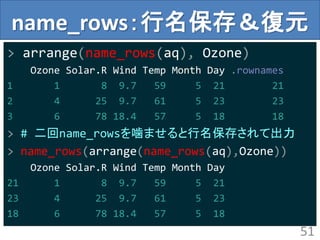
name_rows:行名保存&復元
> arrange(name_rows(aq), Ozone)
OzoneSolar.R Wind Temp Month Day .rownames
1 1 8 9.7 59 5 21 21
2 4 25 9.7 61 5 23 23
3 6 78 18.4 57 5 18 18
> # 二回name_rowsを噛ませると行名保存されて出力
> name_rows(arrange(name_rows(aq),Ozone))
Ozone Solar.R Wind Temp Month Day
21 1 8 9.7 59 5 21
23 4 25 9.7 61 5 23
18 6 78 18.4 57 5 18
51
- 52.
- 53.
- 54.
- 55.
mapvalues,revalue:値の置換
> x <-c("a", "b", "c")
> #a⇒AAA,c⇒CCCと変換。数値もいける
>mapvalues(x,c("a“,"c"),c("AAA","CCC"))
[1] "AAA" "b" "CCC"
> #a⇒AAA,c⇒CCCと変換。文字・ファクター向き
> revalue(x, c("a"="AAA","c"="CCC"))
[1] "AAA" "b" "CCC"
55
- 56.
Happy debugging
> #デバッグする時に便利な書き方
>ddply(aq,.(Month),function(x)browser())
Called from: .fun(piece, ...)
Browse[1]> x
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
56
- 57.
- 58.

























![d_ply:出力なしのddply
> #月毎に分割したデータをファイルに保存
> d_ply(aq, .(Month), function(x){
+ month <- x$Month[1]
+ write.csv(x,paste0("airquality_",month,".csv"))
+ })
39](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-39-320.jpg)


![rlply:指定回数繰り返し処理
42
> #オゾン量と気温の回帰分析を100ランダムサンプ
リングして実施する関数
> f <-
function(){lm(Ozone~Temp,aq[sample(nrow(aq),1
00,replace=TRUE),])}
> #俗にいうブートストラップ
> lms <- rlply(100, f)
> #生Rで書くなら…lms <-
lapply(1:100,function(i){f()})](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-42-320.jpg)
![rlply:指定回数繰り返し処理
43
> library(ggplot2)
> qplot(laply(lms,
function(x)coef(x)[2]
), geom = "blank") +
+
geom_histogram(bin
width=0.2,aes(y
= ..density..),fill="do
dgerblue",colour="b
lack")
0.0
0.5
1.0
1.5
1.5 2.0 2.5 3.0 3.5
laply(lms, function(x) coef(x)[2])
density](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-43-320.jpg)

![arrange:ソート
> arrange(aq,Ozone)
Ozone Solar.R Wind Temp Month Day HighTemp
1 1 8 9.7 59 5 21 0
2 4 25 9.7 61 5 23 0
3 6 78 18.4 57 5 18 0
4 7 NA 6.9 74 5 11 1
5 7 48 14.3 80 7 15 0
> #普通にRで書くならこんなかんじ
> aq[with(aq,order(Ozone)),]
45](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-45-320.jpg)

![splat:同名の列処理
> ozone.per.solar<-
function(Ozone,Solar.R,...){Ozone/Solar.R}
> head(aq,1)
Ozone Solar.R Wind Temp Month Day HighTemp
1 41 190 7.4 67 5 1 1
> splat(ozone.per.solar)(aq[1,])
[1] 0.2157895
> splat(ozone.per.solar)(aq)
[1] 0.21578947 0.30508475 0.08053 ……………
52](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-52-320.jpg)
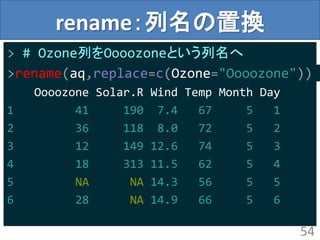
![round_any:値の丸め込み
> # 10の位に丸め込み(1の位で四捨五入)
> round_any(135,10)
[1] 140
> # 10の位に丸め込み(1の位で切り捨て)
> round_any(135,10,floor)
[1] 130
> # 100の位に丸め込み(10の位で切り上げ)
> round_any(135,100,ceiling)
>[1] 200
53](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-53-320.jpg)
![mapvalues,revalue:値の置換
> x <- c("a", "b", "c")
> #a⇒AAA,c⇒CCCと変換。数値もいける
>mapvalues(x,c("a“,"c"),c("AAA","CCC"))
[1] "AAA" "b" "CCC"
> #a⇒AAA,c⇒CCCと変換。文字・ファクター向き
> revalue(x, c("a"="AAA","c"="CCC"))
[1] "AAA" "b" "CCC"
55](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-55-320.jpg)
![Happy debugging
> #デバッグする時に便利な書き方
> ddply(aq,.(Month),function(x)browser())
Called from: .fun(piece, ...)
Browse[1]> x
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
56](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-56-320.jpg)

![参考
• H.Wickham氏の各種slide
– http://www.slideshare.net/hadley/presentations
• Stackoverflowの[plyr]tag
– http://stackoverflow.com/questions/tagged/plyr
• The Split-Apply-Combine Strategy for Data Analysis, H.Wickham
– http://www.jstatsoft.org/v40/i01/paper
58](https://image.slidesharecdn.com/tokyor3020130420-130420005747-phpapp02/85/plyr-plyr-58-320.jpg)