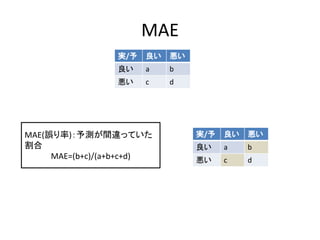
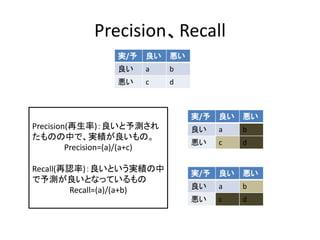
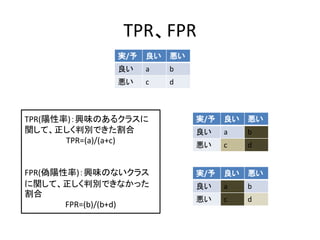
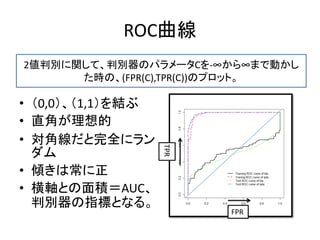
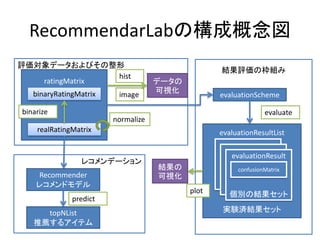
参考
• 協調フィルタリングのサーベイ論文
– ASurvey of Collaborative Filtering Techniques
(Xiaoyuan Su and Taghi M. Khoshgoftaar,Advances in Artificial Intelligence
Volume 2009 (2009), Article ID 421425,)
• Recommenderlabの作者によるチュートリアル
http://cran.r-
project.org/web/packages/recommenderlab/vignettes/recommenderlab.pdf
















![Jester5k
• ジョークのレコメンデーションシステム
• 5000人分のジョークに対する評価が含まれている。
• http://eigentaste.berkeley.edu/user/index.php
#サンプルデータの読み込み
data(Jester5k)
Jester5k
as(Jester5k[1:10], "matrix")[1:2, 1:2]
# j1 j2
# u2841 7.91 9.17
# u15547 -3.20 -3.50
Recommendelabに含まれるユーザ×ジョークのサンプルデータセット](https://image.slidesharecdn.com/collaborativefilteringwithr-130416090214-phpapp02/85/Collaborativefilteringwith-r-33-320.jpg)
![データの整形
as(Jester5k[1:10], "matrix")[1:2, 1:2]
# j1 j2
# u2841 7.91 9.17
# u15547 -3.20 -3.50
#二値データ化
as(binarize(Jester5k[1:10], minRating=-3.2), "matrix")[1:2, 1:2]
# j1 j2
# [1,] 1 1
# [2,] 1 0
as(binarize(Jester5k[1:10], minRating=-3.5), "matrix")[1:2, 1:2]
# j1 j2
# [1,] 1 1
# [2,] 1 1
#正規化を行う
as(normalize(Jester5k[1:10], method="center", row=TRUE), "matrix")[1:2, 1:2]
#j1 j2
#u2841 4.0548148 5.3148148
#u15547 -0.4180282 -0.7180282
ユーザ2841と15547のジョー
ク1,2に対する評価を確認
binarize
二値行列化
normalize
正規化](https://image.slidesharecdn.com/collaborativefilteringwithr-130416090214-phpapp02/85/Collaborativefilteringwith-r-34-320.jpg)
![基本計算
##############基本計算##############
#データより、サンプル1000件を取得
ratings<-sample(Jester5k, 1000)
#ユーザ1の評価の平均
rowMeans(ratings[1,])
# u18940
# -2.439
#ジョーク1の評価の集計
colCounts(ratings[,1])
#j1
#655
#類似性の計算 method="cosine", "pearson", "jaccard"
similarity(x=Jester5k[1:10], method="Jaccard")
# u2841 u15547 u15221 u15573 u21505 u15994 u238 u5809 u16636
# u15547 0.8536585
# u15221 0.8100000 0.7100000
# u15573 0.8100000 0.7100000 1.0000000
# u21505 0.8433735 0.9324324 0.7200000 0.7200000
…
sample
サンプルを取得
rowMeans, colCounts
行、列に対する集計
similarity
類似性の計算](https://image.slidesharecdn.com/collaborativefilteringwithr-130416090214-phpapp02/85/Collaborativefilteringwith-r-35-320.jpg)
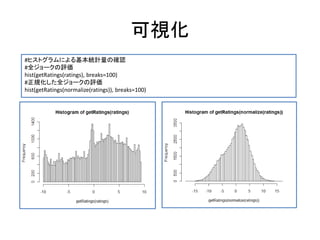
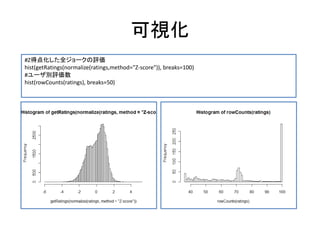
![データの可視化
#ジョーク別評価平均
hist(colMeans(ratings), breaks=50)
#ヒートマップによる可視化
image(ratings[1:100,])](https://image.slidesharecdn.com/collaborativefilteringwithr-130416090214-phpapp02/85/Collaborativefilteringwith-r-38-320.jpg)
![基本の計算
############レコメンデーション################
#実数タイプのユーザ評価マトリックスのレジストリを取得する。
recommenderRegistry$get_entries(dataType="realRatingMatrix")
# ......
# $UBCF_realRatingMatrix
# Recommender method: UBCF
# Description: Recommender based on user-based collaborative filtering (real data).
#Recommenderクラスの生成
recom<-Recommender(Jester5k[1:1000], method="POPULAR")
names(getModel(recom))
#[1] "topN" "ratings" "normalize" "aggregation"
#モデルrecomにより、Top-10レコメンデーションを作成
pred.recom<-predict(recom, Jester5k[1001:1003])
#レコメンデーションを表示する。
as(bestN(pred.recom, n=11), "list")
# [[1]]
# [1] "j89" "j72" "j47" "j93" "j76" "j10" "j96" "j83" "j81" "j87"
#
# [[2]]
# [1] "j89" "j93" "j76" "j88" "j96" "j83" "j81" "j87" "j91" "j78"
recommenderRegistry
レコメンデーション
アルゴリズムのセット
Recommender
レコメンドクラスの作成
predict
与えたデータに対して
予測を行う](https://image.slidesharecdn.com/collaborativefilteringwithr-130416090214-phpapp02/85/Collaborativefilteringwith-r-39-320.jpg)
![レコメンデーションの評価
#評価スキーマを作成する(K交差検証法を行う)
es<-evaluationScheme(Jester5k[1:1000], method="cross", k=4, goodRating=5)
results<-evaluate(es, method="POPULAR", n=c(1,3,5,10,15,20))
# POPULAR run
# 1 [0.03sec/0.59sec]
# 2 [0.04sec/0.61sec]
# 3 [0.03sec/0.59sec]
# 4 [0.03sec/0.56sec]
#混同行列の取得
getConfusionMatrix(results)[[1]]
# n TP FP FN TN PP recall precision FPR TPR
# 1 0.452 0.548 17.712 78.288 1 0.02488439 0.4520 0.006951139 0.02488439
# 3 1.200 1.800 16.964 77.036 3 0.06606474 0.4000 0.022832209 0.06606474
# 5 2.024 2.976 16.140 75.860 5 0.11142920 0.4048 0.037749252 0.11142920
# 10 3.868 6.132 14.296 72.704 10 0.21294869 0.3868 0.077781724 0.21294869
# 15 5.652 9.348 12.512 69.488 15 0.31116494 0.3768 0.118575270 0.31116494
# 20 7.204 12.796 10.960 66.040 20 0.39660868 0.3602 0.162311634 0.39660868
evaluationScheme
評価スキーマを作成
method
split データを分割
cross k交差検証法
bootstrap ブートストラップ
evaluate
評価の実行
getConfusion
Matrix
混同行列の
作成](https://image.slidesharecdn.com/collaborativefilteringwithr-130416090214-phpapp02/85/Collaborativefilteringwith-r-40-320.jpg)
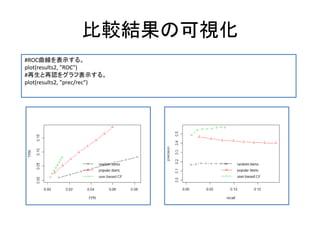
![レコメンデーションの評価
#評価スキーマを作成する(3つのアルゴリズムを比較する。)
es2<-evaluationScheme(Jester5k[1:1000], method="split", k=4, train=0.85, goodRating=5)
algorithms <- list(
"random items" = list(name="RANDOM", param=NULL),
"popular items" = list(name="POPULAR", param=NULL),
"user-based CF" = list(name="UBCF", param=list(method="Cosine",nn=50, minRating=5))
)
#結果を評価する。
results2<-evaluate(es2, algorithms, n=c(1:8))
# RANDOM run
# 1 [0sec/0.39sec]
# 2 [0sec/0.36sec]
# 3 [0sec/0.39sec]
# 4 [0.01sec/0.39sec] POPULAR run
# 1 [0.04sec/0.34sec]
# 2 [0.03sec/0.33sec]
# 3 [0.04sec/0.32sec]
# 4 [0.04sec/0.33sec] UBCF run
# 1 [0.01sec/5.59sec]
# 2 [0.01sec/5.43sec]
# 3 [0.02sec/5.42sec]
# 4 [0.03sec/5.43sec]](https://image.slidesharecdn.com/collaborativefilteringwithr-130416090214-phpapp02/85/Collaborativefilteringwith-r-41-320.jpg)












![[부스트캠프 Tech Talk] 진명훈_datasets로 협업하기](https://cdn.slidesharecdn.com/ss_thumbnails/boostcampaitechtechtalkjinmyunghoon-211210113319-thumbnail.jpg?width=640&height=640&fit=bounds)












![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [Catch, Traffic!] : 지하철 혼잡도 및 키워드 분석 데이터 파이프라인 구축](https://cdn.slidesharecdn.com/ss_thumbnails/catchtrafficppt-230220154703-8361d63a-thumbnail.jpg?width=640&height=640&fit=bounds)








































