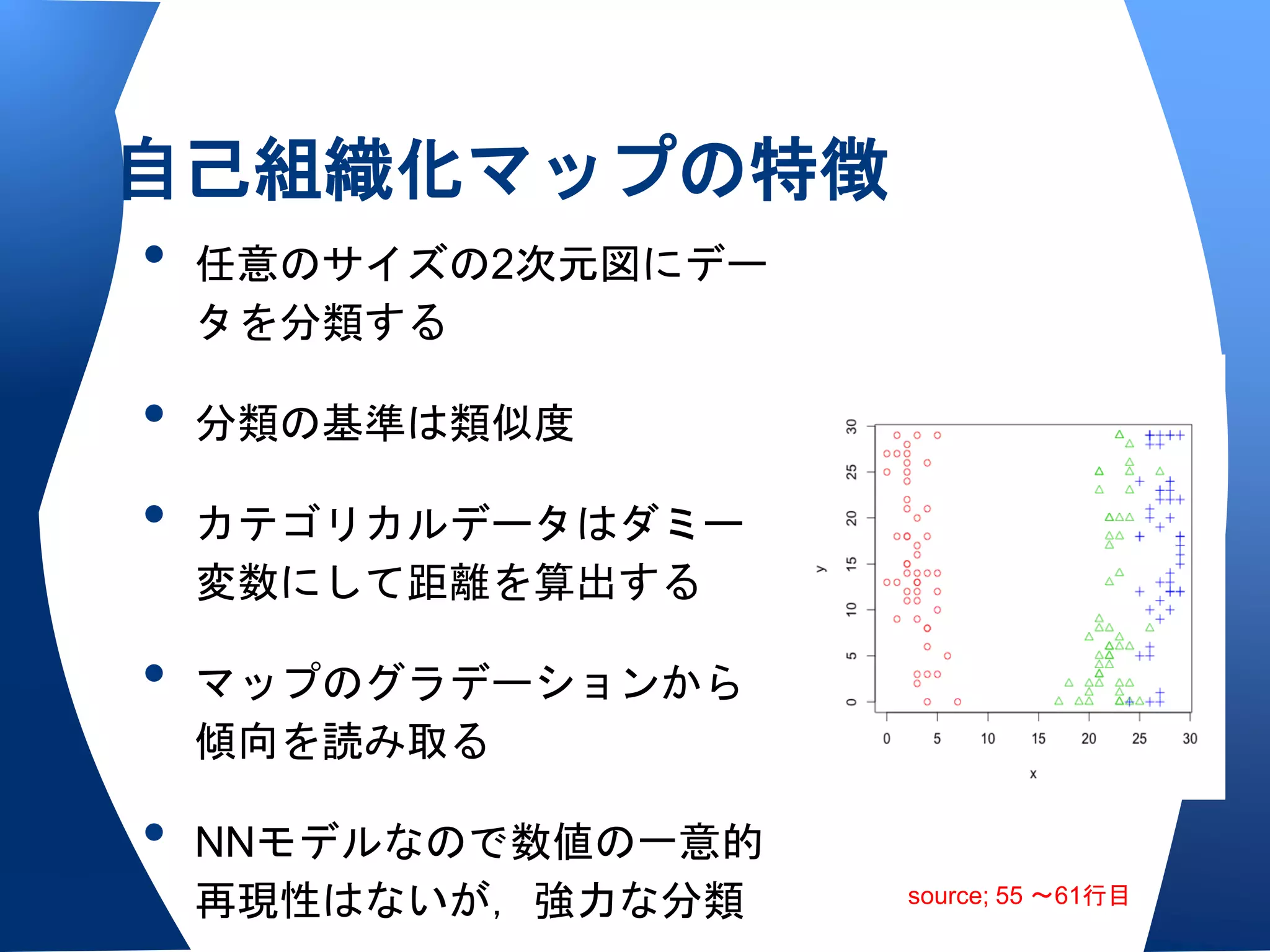
クラスター数の決め方について
• pvclustパッケージ(階層的)
o シミュレーションによって出現確率からクラスター数を検定する
• NbClustパッケージ(階層的)
o 様々な統計指標を算出してくれる
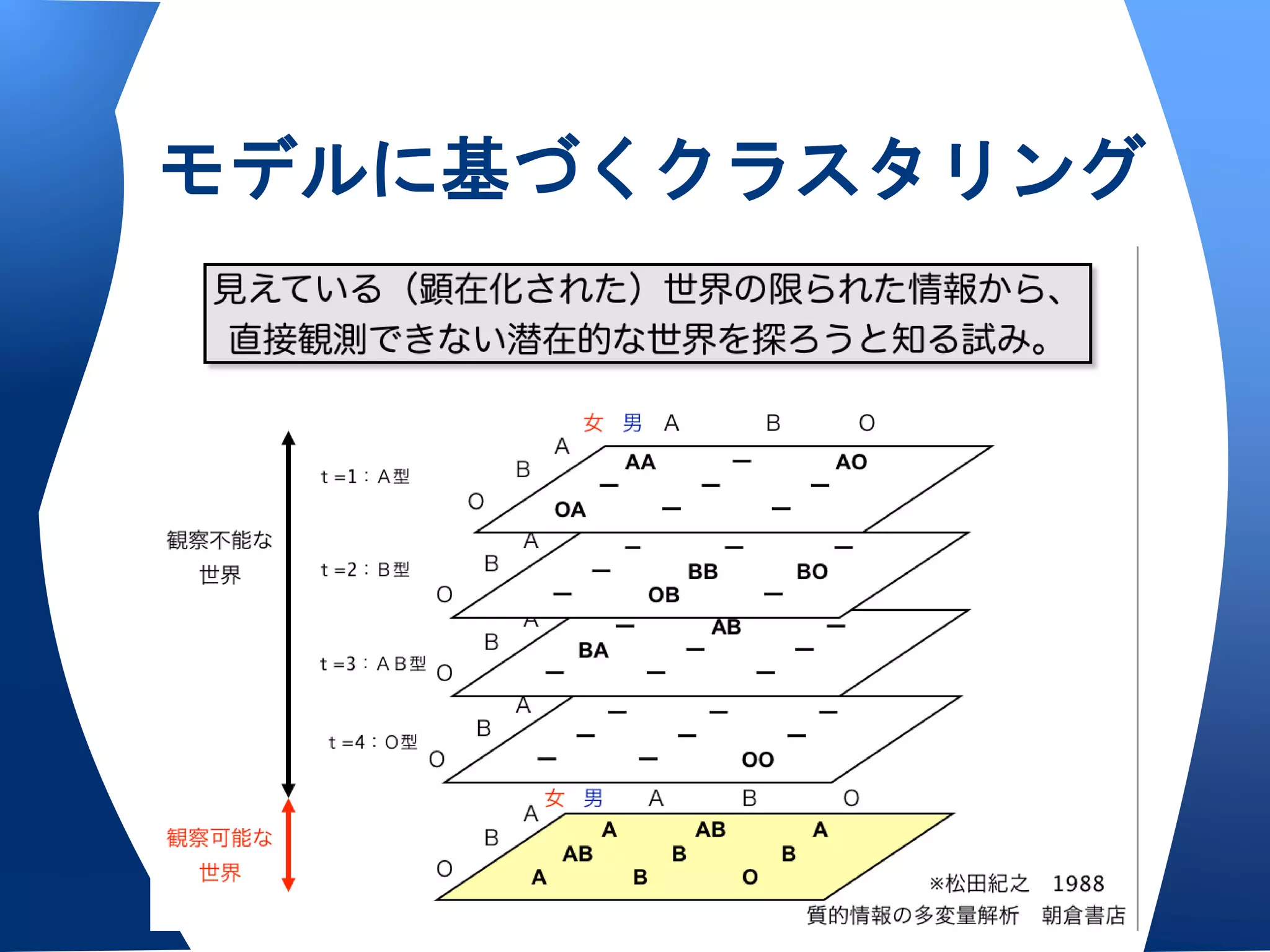
• MClust/Model-based HC
o モデルに基づいた階層的クラスター分析
• Xmeans法
source; 29 〜52行目a
o BIC基準でk-means法を反復的に
SEMが便利になった理由
• 自由なモデリング
oいちいち「○○分析」「××分析」の入門をし
直さなくてよい
• モデルの評価次元の統一
o 適合度指標によって,モデル全体を一括評価
• グラフィカルなソフトウェアの登場
o Amosの存在は高く評価しなければならない
o EQSとかLISRELもがんばってたんだぜ
o OpenMXという手もあるぜ
43.
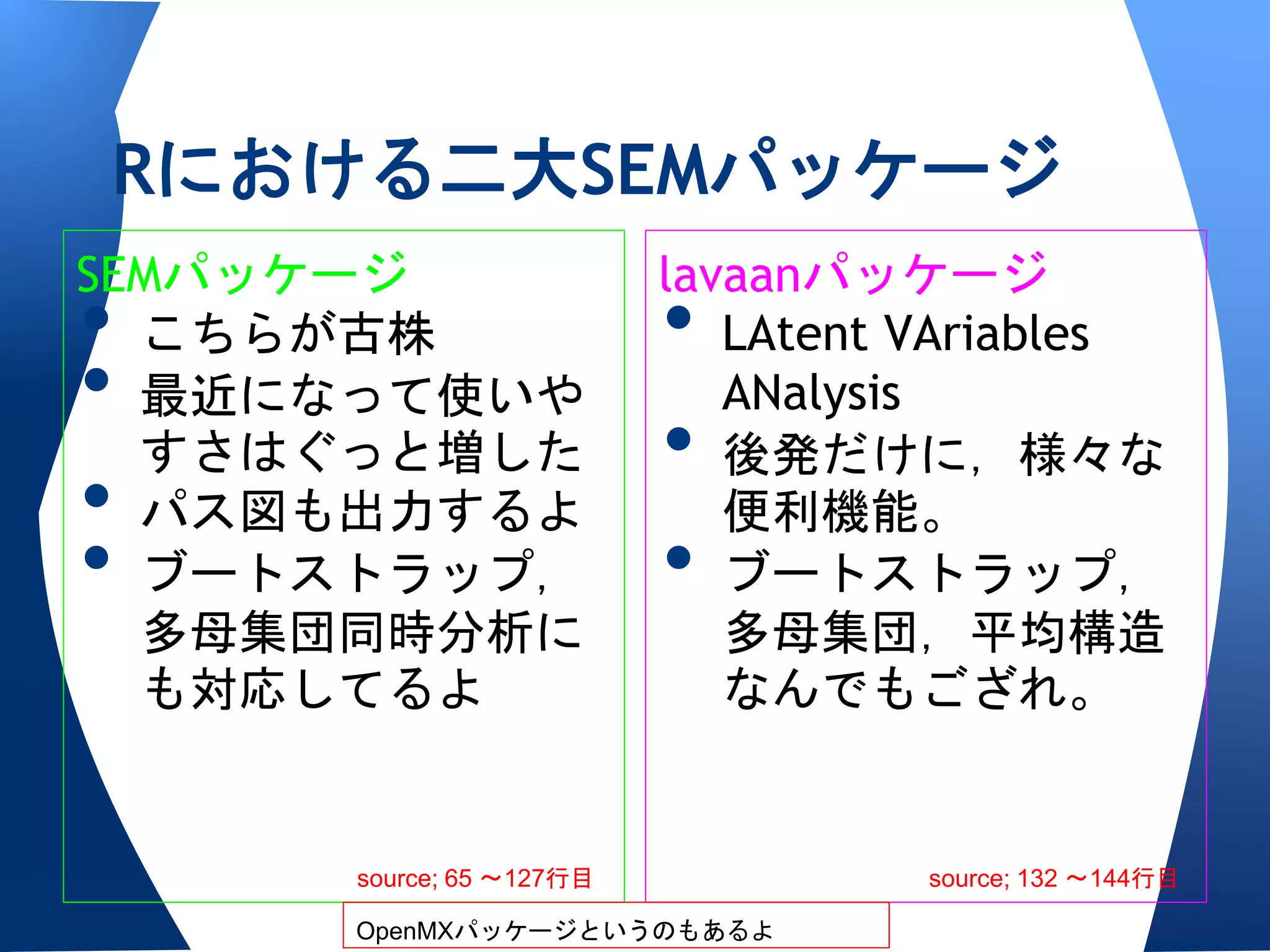
Rでだって負けてはいない
• CUIなので見栄えの良さは負けるけど
oやや慣れも必要だけど
o 一部GUI出力するようになってきているし
o そもそもたくさんの測定方程式をGUIで書く
のはかえってややこしいし
o 機能はどんどん増えていってるし
o 分析環境がRの中で統一できるし
o 無償だし
o 無償だし
o 無償だし
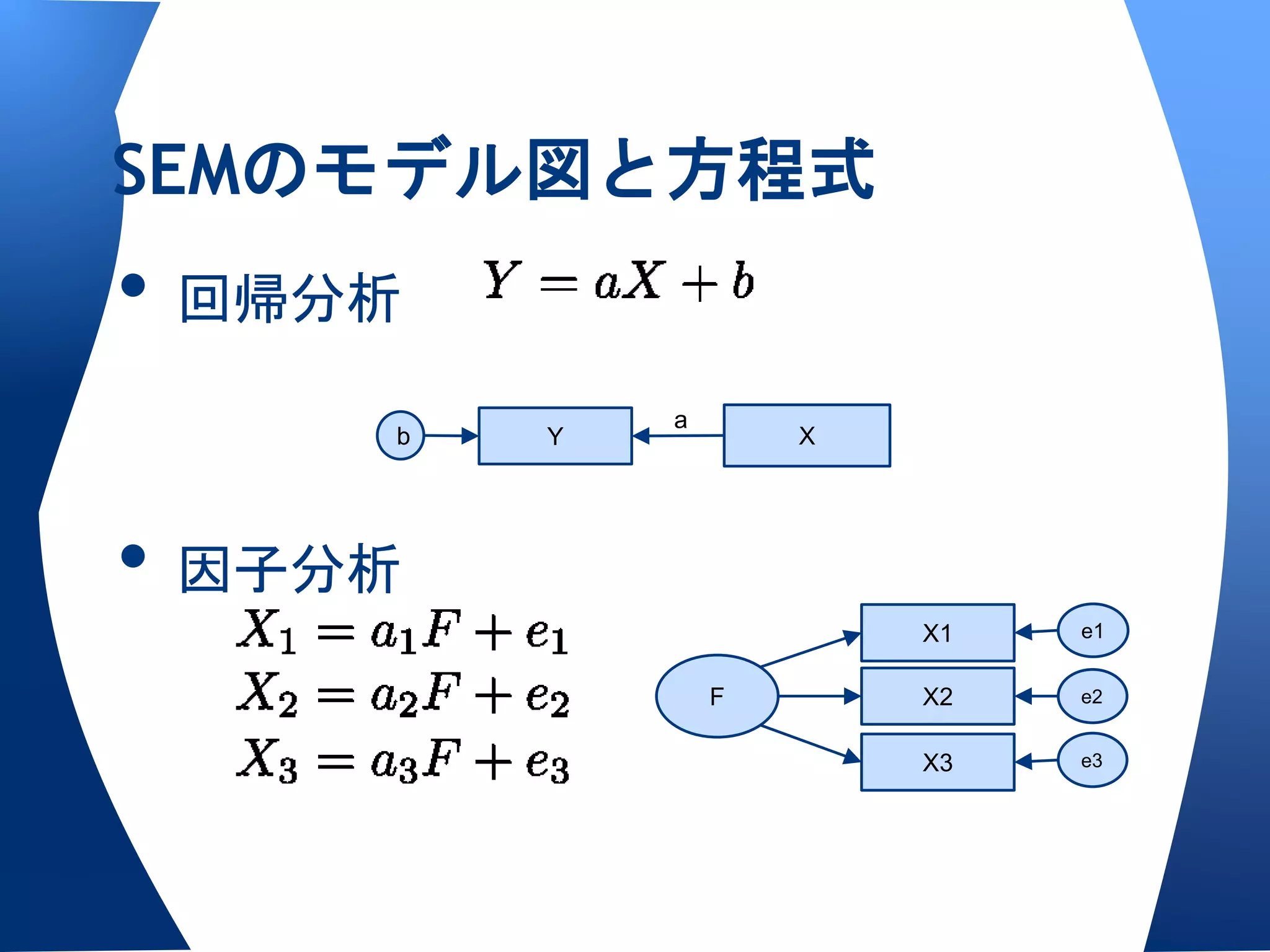
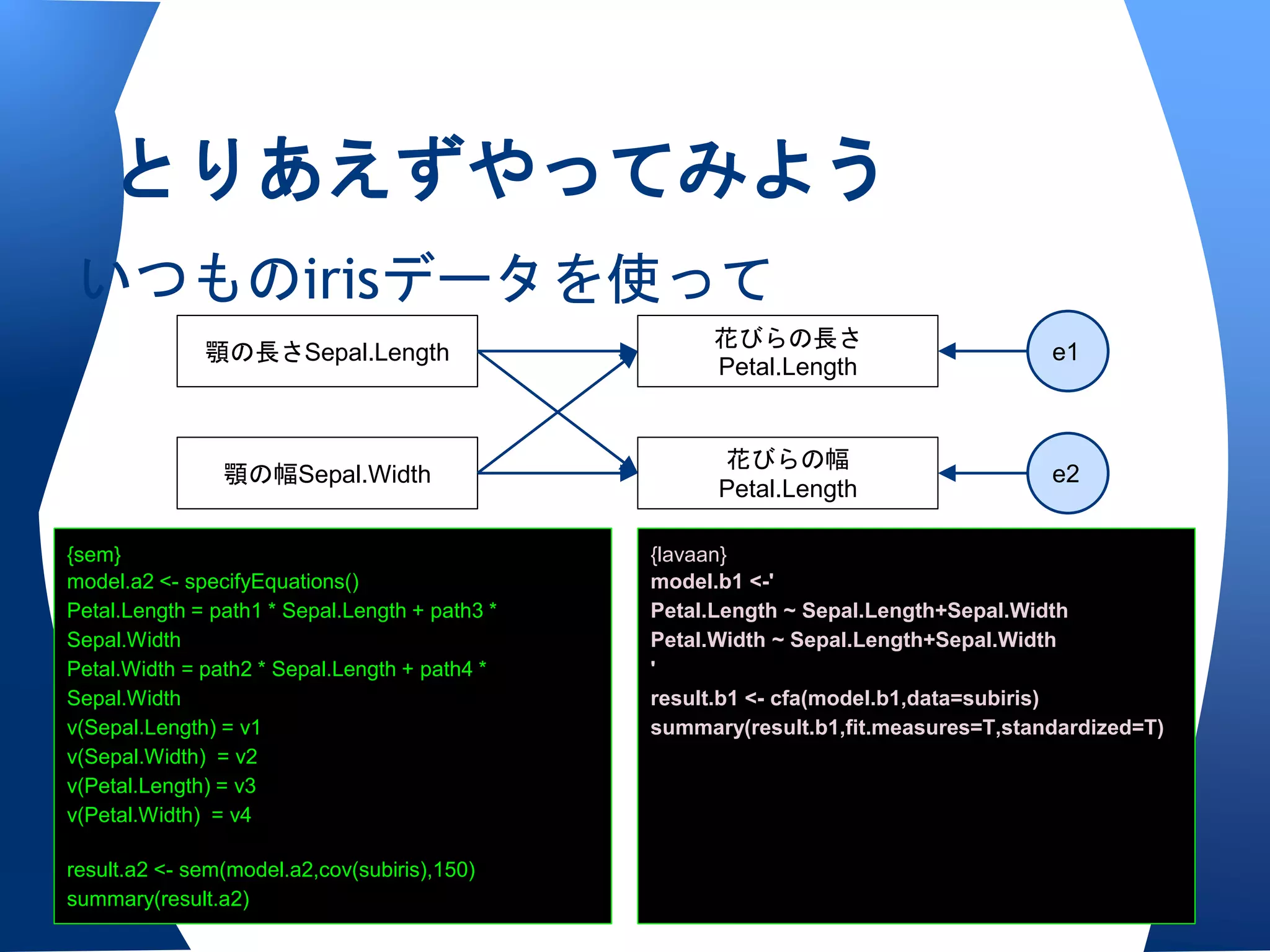
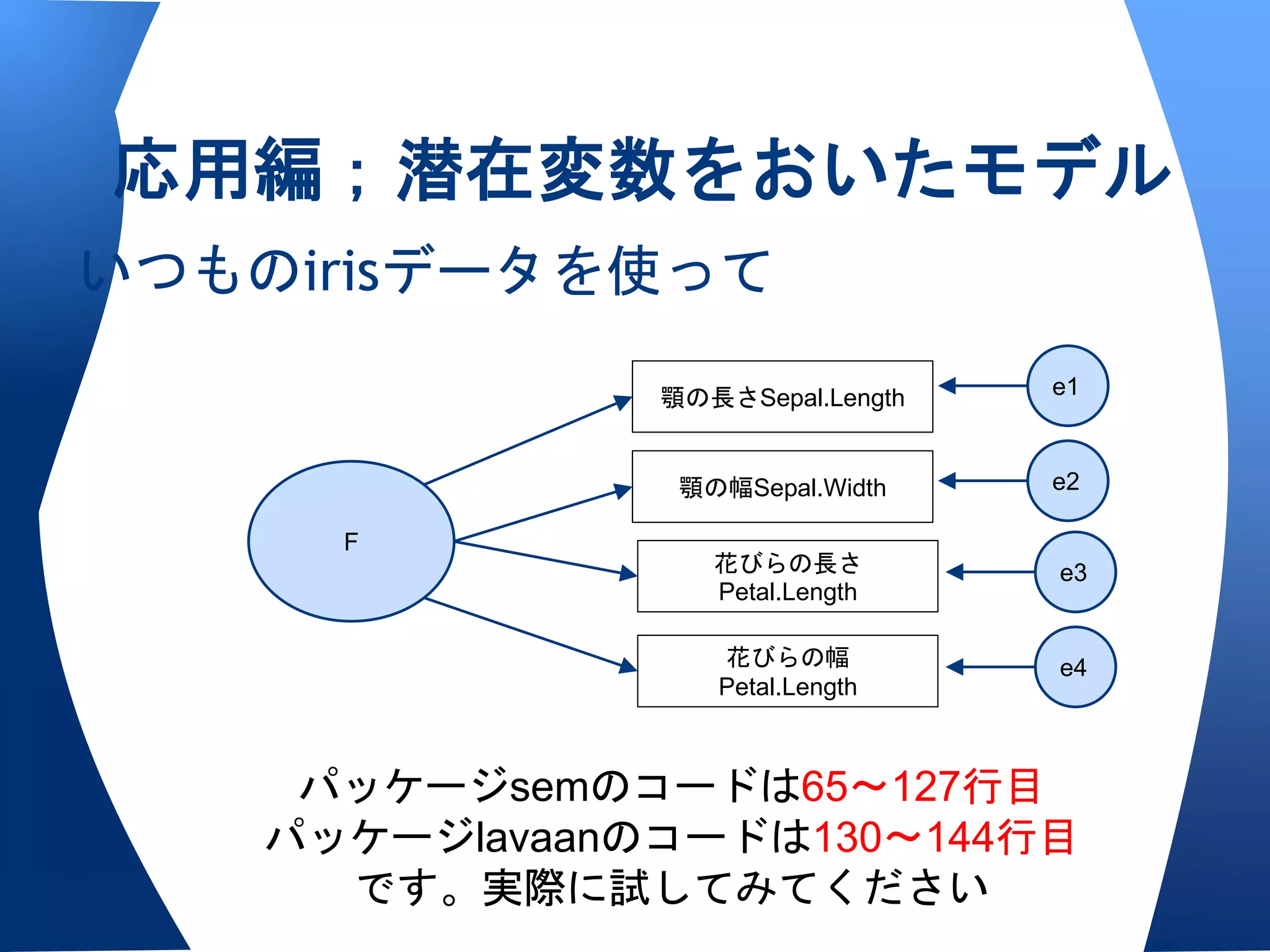
両者の書式〜{sem}の場合
semパッケージの書式
• specifyModel()を使うとき
o <-で因果,<>で相関(分散)
o 変数X <- 変数Y,パス名,初期値/固定母数
• specifyEquations()を使うとき
o 変数X = 係数z1 * 変数Y
o v(変数)=分散
• 出力はsummary
o 適合度指標はfit.indecesオプションで
o 標準化係数を出すstandardizedCoefficients()
o 修正指数を出すmod.indices()
47.
両者の書式〜{lavaan}の場合
• モデルは変数間をつなぐだけ
o潜在変数=~観測変数1+2+3+...で測定方程式
o 変数X~変数Y で構造方程式
o 変数X~~変数Yで相関関係(共分散)
o 他にも~1で切片,f1 ~ 0*f2で直交,など。
• 結果はsummary関数で
o オプションとして
適合度指標 fit.measure=TRUE
標準化係数 standardrized=TRUE
• lavaanの方がやや親切かな,と。
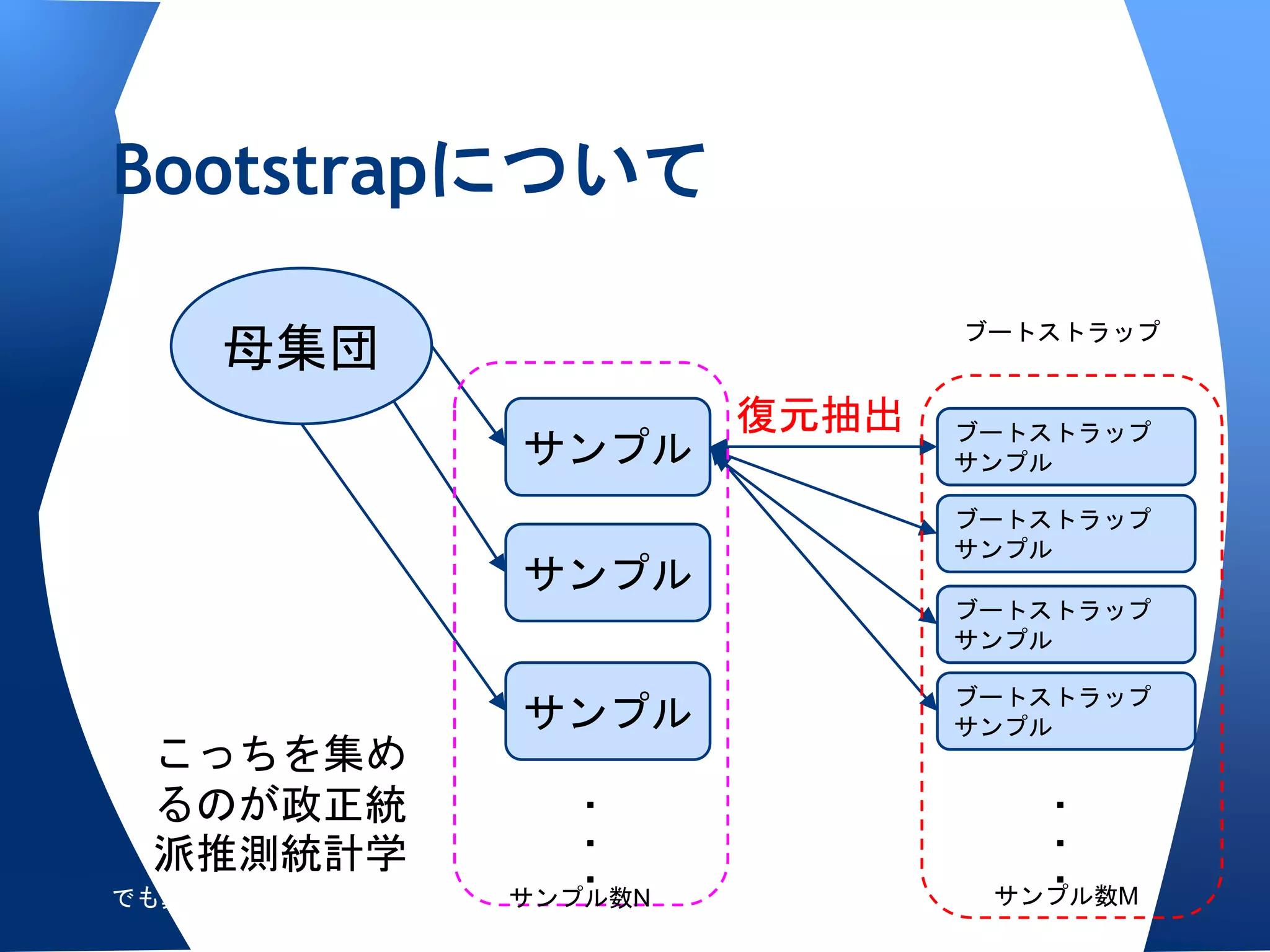
ベイズ統計が使われ始めたのは
• やはりコンピュータの演算能力が爆発的
に発達したから。
o ブートストラップのように,リサンプリング
を数千回行っても数秒で終わる
o ベイズ的推定値を求めるには,分布の形や面
積が分からなければならないが,そのための
積分計算が実用的時間の範囲内で行われるよ
うになった
o 積分の計算には乱数の発生を必要とするが,
乱数発生法も進化!(MC法)
MCMCpackの中身
• 現在ver1.2-4,一部抜粋すると
o MCMCregress ...回帰分析
o MCMCfactanal ...探索的因子分析
o MCMCirt1d ...項目反応理論
o MCMCirtKd ...多次元項目反応理論
o MCMChregress ...階層線形モデル
o MCMClogit ...ロジスティック回帰
o MCMCordfactanal ...順序尺度因子分析
o MCMCpoisson ...ポワソン回帰
o MCMCtobit ...打ち切りデータの解析
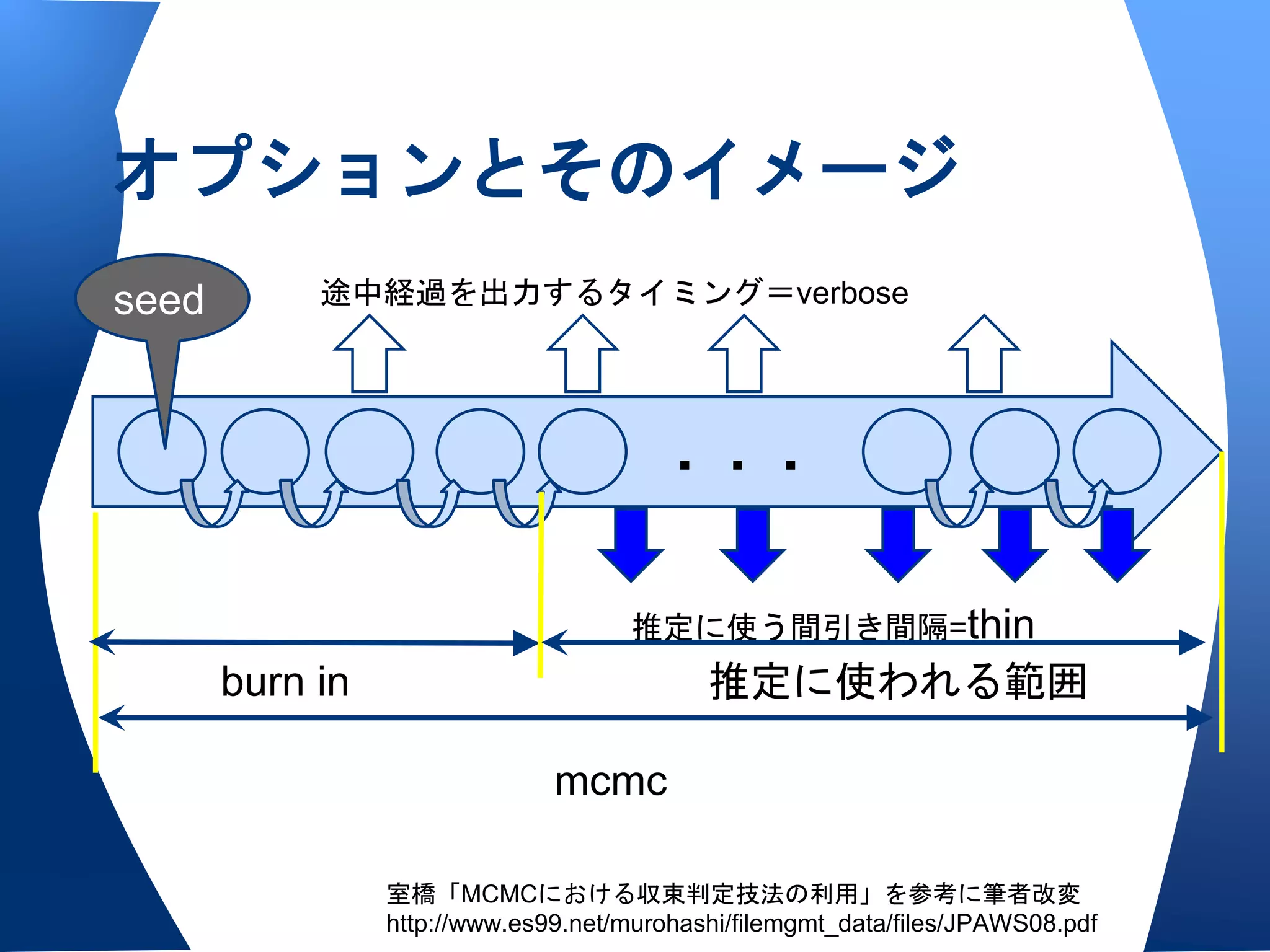
mcmcはどれぐらい?
いつまでburn inしたらいいの?
• デフォルトでは
mcmc=100000,burnin=1000になっている
• 収束したかどうか,を判定する指標
o Gewekeの指標
o Gelman&Rubinの指標
o Heidelberger and Welchの指標
o Rafty and Lewisの指標
• いずれもcodaパッケージ(MCMCpackが自動的
に召還)に含まれています
収束判定の実装
• codaパッケージのcodamenu()関数から,対
話的に
• gewek.diag関数やraftery.diag関数で直接判断
指標を呼び出すことも。
o Gewekeの指標はZ値で出るので,±1.96以内
に入っていれば収束してないとはいえない
o Gelman and Rubin,Rafty and Lewisの指標は
自己相関をもとにしていて1.0に近ければOK
o Heidelberg and Welchはテスト結果も出ます
69.
ぶっちゃけRだとまだまだ
• MCMCpackは結構頻繁にバージョンアッ
プしている
o どんどん機能が追加されています
• それでもやっぱり不便を感じる
o MCMCfactanalでうまくいったためしがない
o SEMをまるごとベイズ推定したいよね
• そんなときは,素直にM-plus
• これはRをdisってるのではなくて,Rには
もっと広い統計の世界があるからいいの