More Related Content

PPTX
多次元信号処理の基礎と画像処理のための二次元変換技術 
PDF

PDF

PDF
PyMCがあれば,ベイズ推定でもう泣いたりなんかしない 
PDF

PDF

PDF

PDF
What's hot

PDF

PDF

PDF

PDF
![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
![[DL輪読会]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Understanding Black-box Predictions via Influence Functions 
PPTX

PPTX

PPTX

PDF

PPTX
Sliced Wasserstein距離と生成モデル 
PPTX

PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012) ![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]GQNと関連研究,世界モデルとの関係について 
PPTX

PDF

PPTX

PPTX

PDF
はじめてのパターン認識 第8章 サポートベクトルマシン 
PDF
Similar to データ解析13 線形判別分析

PDF

PDF

PDF

PDF
東京都市大学 データ解析入門 7 回帰分析とモデル選択 2 
PDF
東京都市大学 データ解析入門 6 回帰分析とモデル選択 1 
PDF

PDF

PPTX

PDF

PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4 
PDF

PDF

PDF

PPTX

PDF

PDF

PPTX

PDF

PDF

PDF
Regression and decision-tree More from Hirotaka Hachiya

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF
データ解析13 線形判別分析
- 1.
- 2.
- 3.
- 4.
回帰分析の復習
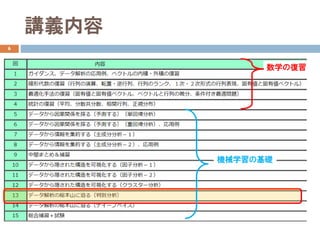
8
回帰分析の目的:入力(説明変数)と出力(目的変数)の
関係を学習し、未知の入力に対する出力を予測する
目的変数:量的なデータ(連続値)
例:靴サイズ、ゴミの排出量、身長、株価、家賃など
�𝑦𝑦 = 𝑤𝑤1 𝑥𝑥1 + 𝑤𝑤2 𝑥𝑥2 + 𝑏𝑏モデル式:
身長(x1) 体重(x2) 靴サイズ(y)
162 44 24.0
165 48 24.5
168 53 25.5
160 45 22.5
158 45 23.0
153 43 22.0
158 45 23.0
168 50 24.0
157 52 23.0
154 42 23.0
170 48 25.0
157 45 23.5
(cm) (kg) (cm)
説明変数𝑥𝑥1 説明変数𝑥𝑥2 目的変数𝑦𝑦
目的変数𝑦𝑦
靴サイズ=傾き X 身長 + 傾き X 体重 + 切片 + 残差
𝑤𝑤1 説明変数𝑥𝑥1 説明変数𝑥𝑥2𝑤𝑤2 𝑏𝑏 𝜀𝜀
モデルパラメータ: 𝑤𝑤1、𝑤𝑤2(傾き)、𝑏𝑏(𝑦𝑦の切片)
- 5.
- 6.
- 7.
- 8.
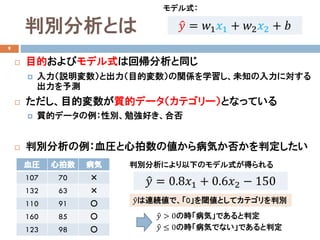
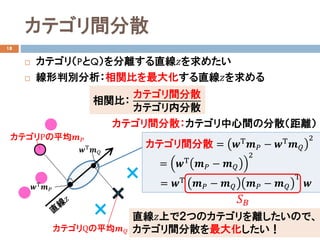
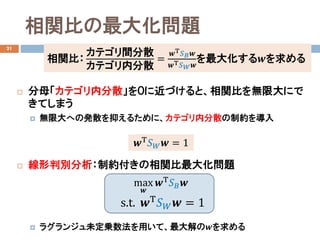
線形判別分析の定式化
13
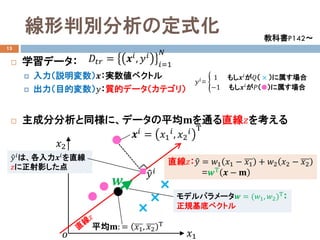
学習データ:
入力(説明変数)𝒙𝒙:実数値ベクトル
出力(目的変数)𝑦𝑦:質的データ(カテゴリ)
主成分分析と同様に、データの平均𝐦𝐦を通る直線𝑧𝑧を考える
𝐷𝐷𝑡𝑡𝑡𝑡 = 𝒙𝒙𝑖𝑖, 𝑦𝑦𝑖𝑖
𝑖𝑖=1
𝑁𝑁
𝑜𝑜 𝑥𝑥1
𝑥𝑥2
教科書P142~
直線𝑧𝑧:�𝑦𝑦 = 𝑤𝑤1 𝑥𝑥1 − 𝑥𝑥1 + 𝑤𝑤2 𝑥𝑥2 − 𝑥𝑥2
=𝒘𝒘Τ
𝒙𝒙 − 𝐦𝐦
𝒙𝒙𝑖𝑖 = 𝑥𝑥1
𝑖𝑖
, 𝑥𝑥2
𝑖𝑖 Τ
�𝑦𝑦𝑖𝑖
モデルパラメータ𝒘𝒘 = (𝑤𝑤1, 𝑤𝑤2)Τ:
正規基底ベクトル
�𝑦𝑦𝑖𝑖は、各入力𝒙𝒙𝑖𝑖を直線
𝑧𝑧に正射影した点
平均𝐦𝐦: = 𝑥𝑥1, 𝑥𝑥2
Τ
𝒘𝒘
𝑦𝑦𝑖𝑖
= �
1 もし𝒙𝒙𝑖𝑖
が𝑄𝑄( × )に属す場合
−1 もし𝒙𝒙𝑖𝑖
が𝑃𝑃(●)に属す場合
- 9.
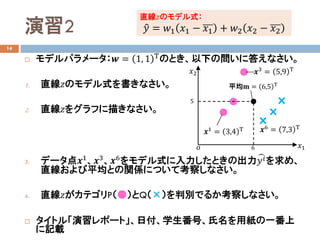
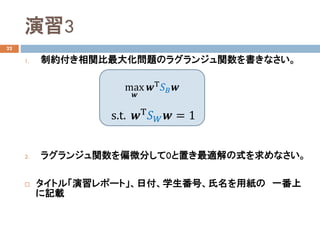
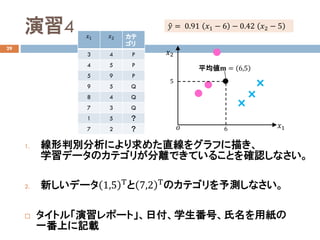
演習2
14
モデルパラメータ:𝒘𝒘 =1, 1 Τ
のとき、以下の問いに答えなさい。
1. 直線𝑧𝑧のモデル式を書きなさい。
2. 直線𝑧𝑧をグラフに描きなさい。
3. データ点𝒙𝒙1
、𝒙𝒙3
、𝒙𝒙6
をモデル式に入力したときの出力 �𝑦𝑦𝑖𝑖を求め、
直線および平均との関係について考察しなさい。
4. 直線𝑧𝑧がカテゴリP(●)とQ(×)を判別でるか考察しなさい。
タイトル「演習レポート」、日付、学生番号、氏名を用紙の一番上
に記載
6𝑜𝑜 𝑥𝑥1
𝑥𝑥2
5
平均𝐦𝐦 = 6,5 Τ
𝒙𝒙3
= 5,9 Τ
𝒙𝒙6 = 7,3 Τ
𝒙𝒙1
= 3,4 Τ
直線𝑧𝑧のモデル式:
�𝑦𝑦 = 𝑤𝑤1 𝑥𝑥1 − 𝑥𝑥1 + 𝑤𝑤2 𝑥𝑥2 − 𝑥𝑥2
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
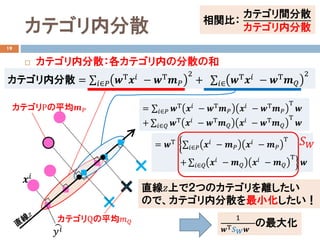
線形判別分析手順2
26
ステップ2: 行列𝑆𝑆𝐵𝐵、𝑆𝑆𝑊𝑊および𝑆𝑆𝑊𝑊
−1
を求める
𝑆𝑆𝐵𝐵= 𝒎𝒎𝑃𝑃 − 𝒎𝒎𝑄𝑄 𝒎𝒎𝑃𝑃 − 𝒎𝒎𝑄𝑄
Τ
= 4
6
− 8
4
4
6
− 8
4
Τ
=
−4
2
−4 2 Τ =
16 −8
−8 4
𝒎𝒎𝑃𝑃 =
4
6
𝒎𝒎𝑄𝑄 =
8
4
𝑆𝑆𝑊𝑊 = �
𝑖𝑖∈𝑃𝑃
𝒙𝒙𝑖𝑖 − 𝒎𝒎𝑃𝑃 𝒙𝒙𝑖𝑖 − 𝒎𝒎𝑃𝑃
Τ
+ �
𝑖𝑖∈𝑄𝑄
𝒙𝒙𝑖𝑖 − 𝒎𝒎𝑄𝑄 𝒙𝒙𝑖𝑖 − 𝒎𝒎𝑄𝑄
Τ
𝑥𝑥1 𝑥𝑥2 カテ
ゴリ
3 4 P
4 5 P
5 9 P
9 5 Q
8 4 Q
7 3 Q
= 3
4
− 4
6
3
4
− 4
6
Τ
+ 4
5
− 4
6
4
5
− 4
6
Τ
+ 5
9
− 4
6
5
9
− 4
6
Τ
+ 9
5
− 8
4
9
5
− 8
4
Τ
+ 8
4
− 8
4
8
4
− 8
4
Τ
+ 7
3
− 7
3
8
4
− 8
4
Τ
=
1 2
2 4
+
0 0
0 1
+
1 3
3 9
+
1 1
1 1
+
0 0
0 0
+
1 1
1 1
=
4 7
7 16
𝑆𝑆𝑊𝑊
−1
=
1
15
16 −7
−7 4
- 19.
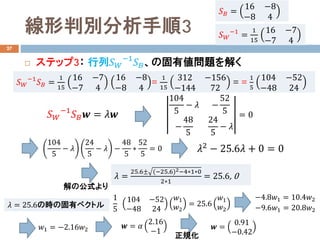
線形判別分析手順3
27
ステップ3: 行列𝑆𝑆𝑊𝑊
−1
𝑆𝑆𝐵𝐵、の固有値問題を解く
𝑆𝑆𝐵𝐵=
16 −8
−8 4
𝑆𝑆𝑊𝑊
−1
=
1
15
16 −7
−7 4
𝑆𝑆𝑊𝑊
−1
𝑆𝑆𝐵𝐵 =
1
15
16 −7
−7 4
16 −8
−8 4
=
1
15
312 −156
−144 72
= =
1
5
104 −52
−48 24
𝑆𝑆𝑊𝑊
−1
𝑆𝑆𝐵𝐵 𝒘𝒘 = 𝜆𝜆𝒘𝒘
104
5
− 𝜆𝜆 −
52
5
−
48
5
24
5
− 𝜆𝜆
= 0
104
5
− 𝜆𝜆
24
5
− 𝜆𝜆 −
48
5
∗
52
5
= 0
𝜆𝜆 =
25.6± (−25.6)2−4∗1∗0
2∗1
= 25.6, 0
解の公式より
𝜆𝜆2
− 25.6𝜆𝜆 + 0 = 0
𝜆𝜆 = 25.6の時の固有ベクトル
1
5
104 −52
−48 24
𝑤𝑤1
𝑤𝑤2
= 25.6
𝑤𝑤1
𝑤𝑤2
−4.8𝑤𝑤1 = 10.4𝑤𝑤2
−9.6𝑤𝑤1 = 20.8𝑤𝑤2
𝑤𝑤1 = −2.16𝑤𝑤2 𝒘𝒘 = 𝛼𝛼
2.16
−1
𝒘𝒘 =
0.91
−0.42正規化
- 20.
- 21.
- 22.
- 23.
- 24.
課題
33
数学と英語の点数データに関する行列𝑆𝑆𝑊𝑊
−1
𝑆𝑆𝐵𝐵 =
0.830.4
0.68 0.32
、
平均𝐦𝐦 = 4.2,3.8 Τのとき、線形判別分析を行いなさい。
1. 固有値問題を解き、直線𝑧𝑧の正規基底ベクトル𝒘𝒘を求めなさい。
2. 直線𝑧𝑧のモデル式を書きなさい。
3. グラフに点数データと、求めた直線𝑧𝑧および分類境界を描きなさい。
4. 直線𝑧𝑧により、点数データのカテゴリが判別できるか否か考察しなさい。
5. 新しい学生の点数 0,8 Τ
と 1,8 Τ
を判別しなさい。
A B C D E F G H I J
数学𝑥𝑥1 2 1 2 3 5 4 8 6 7 4
英語𝑥𝑥2 3 4 2 2 4 4 5 3 6 5
カテゴリ P P P P Q Q Q Q Q Q
数学と英語の点数データ
- 25.