Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Masashi Komori
PPTX, PDF
7,827 views
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
Osaka.Stan#6『StanとRでベイズ統計モデリング』(通称アヒル本)読書会@関西学院大学 2017年11月18日(土) https://atnd.org/events/91527
Science
◦
Read more
9
Save
Share
Embed
Embed presentation
Download
Downloaded 93 times
1
/ 34
2
/ 34
Most read
3
/ 34
4
/ 34
5
/ 34
6
/ 34
7
/ 34
8
/ 34
9
/ 34
10
/ 34
11
/ 34
12
/ 34
13
/ 34
14
/ 34
15
/ 34
16
/ 34
17
/ 34
18
/ 34
19
/ 34
20
/ 34
21
/ 34
22
/ 34
23
/ 34
24
/ 34
25
/ 34
26
/ 34
27
/ 34
28
/ 34
29
/ 34
30
/ 34
31
/ 34
32
/ 34
33
/ 34
34
/ 34
More Related Content
PDF
階層ベイズによるワンToワンマーケティング入門
by
shima o
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PPTX
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
PPTX
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
PDF
Rの高速化
by
弘毅 露崎
PDF
ベイズ統計入門
by
Miyoshi Yuya
PDF
これからの仮説検証・モデル評価
by
daiki hojo
PDF
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
階層ベイズによるワンToワンマーケティング入門
by
shima o
階層モデルの分散パラメータの事前分布について
by
hoxo_m
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
StanとRでベイズ統計モデリング読書会(Osaka.stan) 第6章
by
Shushi Namba
Rの高速化
by
弘毅 露崎
ベイズ統計入門
by
Miyoshi Yuya
これからの仮説検証・モデル評価
by
daiki hojo
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
What's hot
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
Chapter9 一歩進んだ文法(前半)
by
itoyan110
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
Rで階層ベイズモデル
by
Yohei Sato
PDF
状態空間モデルの考え方・使い方 - TokyoR #38
by
horihorio
PDF
一般化線形混合モデル入門の入門
by
Yu Tamura
PDF
ベイズ推定の概要@広島ベイズ塾
by
Yoshitake Takebayashi
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PDF
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PDF
媒介分析について
by
Hiroshi Shimizu
PDF
質的変数の相関・因子分析
by
Mitsuo Shimohata
PDF
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PDF
Stan勉強会資料(前編)
by
daiki hojo
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PDF
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
PDF
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
Stanコードの書き方 中級編
by
Hiroshi Shimizu
Chapter9 一歩進んだ文法(前半)
by
itoyan110
Stan超初心者入門
by
Hiroshi Shimizu
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
Rで階層ベイズモデル
by
Yohei Sato
状態空間モデルの考え方・使い方 - TokyoR #38
by
horihorio
一般化線形混合モデル入門の入門
by
Yu Tamura
ベイズ推定の概要@広島ベイズ塾
by
Yoshitake Takebayashi
階層ベイズとWAIC
by
Hiroshi Shimizu
比例ハザードモデルはとってもtricky!
by
takehikoihayashi
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
媒介分析について
by
Hiroshi Shimizu
質的変数の相関・因子分析
by
Mitsuo Shimohata
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
Stan勉強会資料(前編)
by
daiki hojo
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
第8章 ガウス過程回帰による異常検知
by
Chika Inoshita
「内積が見えると統計学も見える」第5回 プログラマのための数学勉強会 発表資料
by
Ken'ichi Matsui
Viewers also liked
PPTX
シンポジウム「データの時代の心理学」指定討論
by
Masashi Komori
PDF
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
PPTX
NagoyaStat #5 データ解析のための 統計モデリング入門 第10章
by
nishioka1
PDF
Osaka.Stan #3 Chapter 5-2
by
Takayuki Goto
PDF
Stanでpsychophysics──階層ベイズモデルで恒常法データを分析する──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PDF
StanとRで折れ線回帰──空間的視点取得課題の反応時間データを説明する階層ベイズモデルを例に──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PDF
データ解析のための統計モデリング入門 1~2章
by
itoyan110
PPTX
Osaka.stan#2 chap5-1
by
Makoto Hirakawa
PPTX
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
シンポジウム「データの時代の心理学」指定討論
by
Masashi Komori
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
NagoyaStat #5 データ解析のための 統計モデリング入門 第10章
by
nishioka1
Osaka.Stan #3 Chapter 5-2
by
Takayuki Goto
Stanでpsychophysics──階層ベイズモデルで恒常法データを分析する──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
StanとRで折れ線回帰──空間的視点取得課題の反応時間データを説明する階層ベイズモデルを例に──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
データ解析のための統計モデリング入門 1~2章
by
itoyan110
Osaka.stan#2 chap5-1
by
Makoto Hirakawa
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
Similar to 【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
PDF
Data assim r
by
Xiangze
PDF
『予測にいかす統計モデリングの基本』の売上データの分析をトレースしてみた
by
. .
PPTX
マルコフ転換モデル:導入編
by
Masa Kato
PDF
Kdd2015reading-tabei
by
Yasuo Tabei
PDF
Rによるデータサイエンス:12章「時系列」
by
Nagi Teramo
PDF
はじめてのベイズ推定
by
Kenta Matsui
PDF
状態空間モデルの実行方法と実行環境の比較
by
Hiroki Itô
PDF
論文輪読会 - A Multi-level Trend-Renewal Process for Modeling Systems with Recurre...
by
atsushi_hayakawa
PDF
PRML復々習レーン#11
by
Takuya Fukagai
PDF
Stanとdlmによる状態空間モデル
by
Hiroki Itô
PPTX
Osaka.stan#4 chap8
by
Takashi Yamane
PDF
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
PPTX
Time series analysis with python chapter2-1
by
ShoKumada
PDF
時系列解析の使い方 - TokyoWebMining #17
by
horihorio
PDF
Pythonでカスタム状態空間モデル
by
Hamage9
PDF
Rパッケージ“KFAS”を使った時系列データの解析方法
by
Hiroki Itô
PDF
異常行動検出入門 – 行動データ時系列のデータマイニング –
by
Yohei Sato
PDF
幾何を使った統計のはなし
by
Toru Imai
PPTX
Tori lab 輪読会 WWW 2014 - Modeling and predicting the growth and death
by
Kimitaka
PDF
PRML 8.2 条件付き独立性
by
sleepy_yoshi
Data assim r
by
Xiangze
『予測にいかす統計モデリングの基本』の売上データの分析をトレースしてみた
by
. .
マルコフ転換モデル:導入編
by
Masa Kato
Kdd2015reading-tabei
by
Yasuo Tabei
Rによるデータサイエンス:12章「時系列」
by
Nagi Teramo
はじめてのベイズ推定
by
Kenta Matsui
状態空間モデルの実行方法と実行環境の比較
by
Hiroki Itô
論文輪読会 - A Multi-level Trend-Renewal Process for Modeling Systems with Recurre...
by
atsushi_hayakawa
PRML復々習レーン#11
by
Takuya Fukagai
Stanとdlmによる状態空間モデル
by
Hiroki Itô
Osaka.stan#4 chap8
by
Takashi Yamane
異常検知と変化検知 9章 部分空間法による変化点検知
by
hagino 3000
Time series analysis with python chapter2-1
by
ShoKumada
時系列解析の使い方 - TokyoWebMining #17
by
horihorio
Pythonでカスタム状態空間モデル
by
Hamage9
Rパッケージ“KFAS”を使った時系列データの解析方法
by
Hiroki Itô
異常行動検出入門 – 行動データ時系列のデータマイニング –
by
Yohei Sato
幾何を使った統計のはなし
by
Toru Imai
Tori lab 輪読会 WWW 2014 - Modeling and predicting the growth and death
by
Kimitaka
PRML 8.2 条件付き独立性
by
sleepy_yoshi
More from Masashi Komori
PPTX
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
PPTX
感性情報心理学(1/4)
by
Masashi Komori
PPTX
感性情報心理学(4/4)
by
Masashi Komori
PPTX
感性情報心理学(3/4)
by
Masashi Komori
PPTX
感性情報心理学(2/4)
by
Masashi Komori
PPTX
工学系研究者のための 心理学的研究手法ガイド: 研究計画から実施,成果公表まで
by
Masashi Komori
社会心理学者のための時系列分析入門_小森
by
Masashi Komori
感性情報心理学(1/4)
by
Masashi Komori
感性情報心理学(4/4)
by
Masashi Komori
感性情報心理学(3/4)
by
Masashi Komori
感性情報心理学(2/4)
by
Masashi Komori
工学系研究者のための 心理学的研究手法ガイド: 研究計画から実施,成果公表まで
by
Masashi Komori
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル
1.
Chapter12:時間や空間を扱うモデル 大阪電気通信大学 情報通信工学部 小森 政嗣 『StanとRでベイズ統計モデリング』読書会(Osaka.Stan#6)
2.
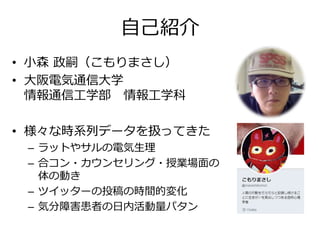
自己紹介 • 小森 政嗣(こもりまさし) •
大阪電気通信大学 情報通信工学部 情報工学科 • 様々な時系列データを扱ってきた – ラットやサルの電気生理 – 合コン・カウンセリング・授業場面の 体の動き – ツイッターの投稿の時間的変化 – 気分障害患者の日内活動量パタン
3.
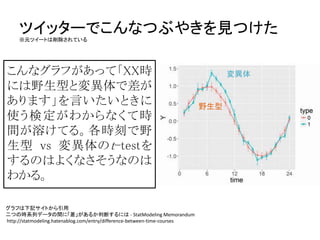
ツイッターでこんなつぶやきを見つけた ※元ツイートは削除されている こんなグラフがあって「XX時 には野生型と変異体で差が あります」を言いたいときに 使う検定がわからなくて時 間が溶けてる。各時刻で野 生型 vs 変異体のt-testを するのはよくなさそうなのは わかる。 グラフは下記サイトから引用 二つの時系列データの間に「差」があるか判断するには
- StatModeling Memorandum http://statmodeling.hatenablog.com/entry/difference-between-time-courses 野生型 変異体
4.
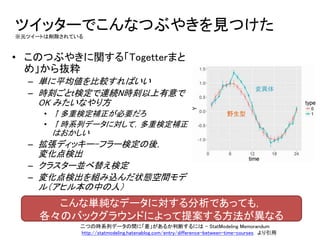
ツイッターでこんなつぶやきを見つけた ※元ツイートは削除されている 二つの時系列データの間に「差」があるか判断するには - StatModeling
Memorandum http://statmodeling.hatenablog.com/entry/difference-between-time-courses より引用 野生型 変異体 • このつぶやきに関する「Togetterまと め」から抜粋 – 単に平均値を比較すればいい – 時刻ごとt検定で連続N時刻以上有意で OK みたいなやり方 • ↑多重検定補正が必要だろ • ↑時系列データに対して,多重検定補正 はおかしい – 拡張ディッキー–フラー検定の後, 変化点検出 – クラスター並べ替え検定 – 変化点検出を組み込んだ状態空間モデ ル(アヒル本の中の人) こんな単純なデータに対する分析であっても, 各々のバックグラウンドによって提案する方法が異なる
5.
時系列解析のモデルを考えるときに必要なこと • 様々な時系列分析手法がある • 手法の違いは,基本的には「自己相関」と どのように向き合うのかの違い –
自己相関と正面から向き合う方法 • 「トレンド」「季節性」などの様々な自己相関を考慮する • 状態空間モデルはここに含まれる – 自己相関を消す方法 • 周波数解析など 12章では時空間的な自己相関を考慮に 入れた「状態空間モデル」を扱っている
6.
12章のアウトライン 12.1 状態空間モデルことはじめ ローカルレベルモデル・ローカル線形トレンドモデル 12.2 季節調整項 ダミー変数を使った季節成分の調整 12.3
変化点検出 12.4 その他の拡張方法 トレンド項の工夫,時間間隔不等の対処,複数のパラメータ 12.5 時間構造と空間構造の等価性 12.6 1次元の空間構造 みんな大好き久保緑本11章のデータでマルコフ場モデル 12.7 2次元の空間構造 12.8 地図を使った空間構造
7.
状態空間モデルことはじめ(概要) • 状態空間モデルでは真の状態𝜇と観測値𝑌を区別する – 真の状態は直接は観測できない –
観測値は時々刻々得られる 真の状態𝜇 観測値𝑌 𝜇[1] 𝜇[2] 𝜇[𝑇] 𝑌[2]𝑌[1] 𝑌[𝑇] ⋯ ⋯ システムモデル(状態方程式) 「真の状態」の前後の関係式 観測モデル(観測方程式) 「真の値」は観測値に その都度反映される
8.
状態空間モデルことはじめ(概要) • 一番簡単なローカルレベルモデル(酔歩+ノイズ)の例 – 12.1.3節■モデル式12−2■(1階差分のトレンド項モデル) 𝜇
𝑡 ~ Normal 𝜇 𝑡 − 1 , 𝜎𝜇 システムモデル(状態方程式) 𝑌 𝑡 ~ Normal 𝜇 𝑡 , 𝜎 𝑌 観測モデル(観測方程式) 真の状態𝜇 観測値𝑌 𝜇[1] 𝜇[2] 𝜇[𝑇] 𝑌[2] 𝑌[1] 𝑌[𝑇] ⋯ システムモデル 観測モデル ⋯ +𝜀 𝜇1 +𝜀 𝜇2 +𝜀 𝜇𝑇−1 +𝜀 𝑌1 +𝜀 𝑌2 +𝜀 𝑌𝑇 (状態撹乱項) (状態撹乱項) (観測撹乱項) (観測撹乱項)
9.
状態空間モデルことはじめ(書き方) ローカルレベルモデルを例に • 本書でのモデルの書き方 𝜇 𝑡
~ Normal 𝜇 𝑡 − 1 , 𝜎𝜇 𝑌 𝑡 ~ Normal 𝜇 𝑡 , 𝜎 𝑌 • こんな風に書かれることも 𝜇 𝑡 = 𝜇 𝑡−1 + 𝜀 𝜇 𝜀 𝜇~NID(0, 𝜎𝜇) 𝑦𝑡 = 𝜇 𝑡 + 𝜀 𝑌 𝜀 𝑌~NID(0, 𝜎 𝑌) • 一般的には 𝛍t = 𝐓𝐭 𝛍𝐭−𝟏 + 𝐑 𝐭 𝛆 𝛍 𝐲𝐭 = 𝐙𝐭 𝛍𝐭 + 𝛆 𝐘 • Stanでの(スマートな)書き方 model { mu[2:T] ~ normal(mu[1:(T-1)], s_mu); Y ~ normal(mu, s_Y); } • Stanでの(わかりやすい)書き方 model { for( t in 2 : T){ mu[t] ~ normal(mu[t-1], s_mu); } Y ~ normal(mu, s_Y); } システムモデル(状態方程式) 観測モデル(観測方程式)
10.
ローカルレベルモデル (「1階差分のトレンド項」を考慮したモデル) • ローカルレベルモデルは 「ランダムウォークプラスノイズモデル」 とも呼ばれる • 𝜇に正規ノイズ(状態撹乱項)𝜀
𝜇が累積加算されていく過程 𝜇 𝑡 = 𝜇 𝑡 − 1 + 𝜀 𝜇 𝑡 𝜀 𝜇 𝑡 ~Normal 0, 𝜎𝜇 12.1.1 – 12.1.5 pp. 231 - 233 初期値=0, σμ=1 に設定した for (t in 2:N) y[t] <- rnorm(1, y[t-1], sigma) • ランダムウォーク(酔歩)とは? 描いてみた
11.
ローカルレベルモデル (「 1階差分のトレンド項」を考慮したモデル) • ローカルレベルモデルはランダムウォークに観測撹乱項が加 わった観測値𝑌
から, 以下のパラメータを推定する • 𝜇[𝑡],𝜎𝜇,𝜎 𝑌 12.1.1 – 12.1.5 pp. 231 - 233 真の状態𝜇 観測値𝑌 𝜇[1] 𝜇[2] 𝜇[𝑇] 𝑌[2] 𝑌[1] 𝑌[𝑇] ⋯ システムモデル 観測モデル ⋯ +𝜀 𝜇1 +𝜀 𝜇2 +𝜀 𝜇𝑇−1 +𝜀 𝑌1 +𝜀 𝑌2 +𝜀 𝑌𝑇 (状態撹乱項) (状態撹乱項) (観測撹乱項) (観測撹乱項) 𝜇 𝑡 ~ Normal 𝜇 𝑡 − 1 , 𝜎𝜇 𝑡 = 2, … , 𝑇 (12.1) 𝑌 𝑡 ~ Normal 𝜇 𝑡 , 𝜎 𝑌 𝑡 = 1, … , 𝑇 (12.2)
12.
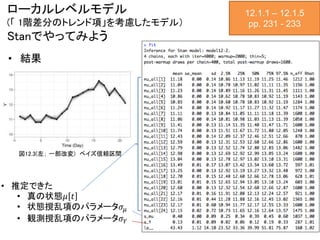
ローカルレベルモデル (「 1階差分のトレンド項」を考慮したモデル) Stanでやってみよう • イベントの21日分の来場者数データからパラメータを推定 12.1.1
– 12.1.5 pp. 231 - 233 図12.1(右) イベント来場者 data { int T; int T_pred; vector[T] Y; } parameters { vector[T] mu; real<lower=0> s_mu; real<lower=0> s_Y; } model { mu[2:T] ~ normal(mu[1:(T-1)], s_mu); Y ~ normal(mu, s_Y); } model12-2.stan(抜粋) システムモデル(状態方程式) 観測モデル(観測方程式)
13.
ローカルレベルモデル (「 1階差分のトレンド項」を考慮したモデル) Stanでやってみよう • 結果 12.1.1
– 12.1.5 pp. 231 - 233 • 推定できた • 真の状態𝜇 𝑡 • 状態撹乱項のパラメータ𝜎𝜇 • 観測撹乱項のパラメータ𝜎 𝑌 図12.3(左; 一部改変) ベイズ信頼区間
14.
ローカルレベルモデル (「 1階差分のトレンド項」を考慮したモデル) ついでに今後の予測もStanでやってみよう • generated
quantitiesで将来の来場者の予測もできる 12.1.1 – 12.1.5 pp. 231 - 233 generated quantities { vector[T+T_pred] mu_all; vector[T_pred] y_pred; mu_all[1:T] = mu; for (t in 1:T_pred) { mu_all[T+t] = normal_rng(mu_all[T+t-1], s_mu); y_pred[t] = normal_rng(mu_all[T+t], s_Y); } } ※もちろんgenerated quantities を使わずにRで乱数を発生させて予 測することもできるし,また,将来の 値を「欠損値」とみなしてmodel{}内で 予測することも可能(「Stanで体重の 推移をみつめてみた(状態空間モデ ル) @kosugittiさん参照) 「ガキの使いとちゃうねんぞ」という レベルの予測. もっと減っていきそうなのに… 所詮はランダムウォークモデル. できるのはこの程度 ローカルレベルモデルでは 流石にモデルが単純すぎるのでは?
15.
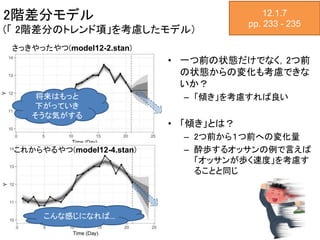
2階差分モデル (「 2階差分のトレンド項」を考慮したモデル) • 一つ前の状態だけでなく,2つ前 の状態からの変化も考慮できな いか? –
「傾き」を考慮すれば良い • 「傾き」とは? – 2つ前から1つ前への変化量 – 酔歩するオッサンの例で言えば 「オッサンが歩く速度」を考慮す ることと同じ 12.1.7 pp. 233 - 235 将来はもっと 下がっていき そうな気がする さっきやったやつ(model12-2.stan) こんな感じになれば… これからやるやつ(model12-4.stan)
16.
2階差分モデル (「 2階差分のトレンド項」を考慮したモデル) 12.1.7 pp. 233
- 235 • 1階差分のトレンド項モデル(model12-2.stan) 𝜇 𝑡 = 𝜇 𝑡 − 1 + 𝜀 𝜇 𝑡 − 1 • 2階差分のトレンド項モデル(model12-4.stan) 𝜇 𝑡 = 𝜇 𝑡 − 1 + 𝜇 𝑡 − 1 − 𝜇 𝑡 − 2 + 𝜀 𝜇 𝑡 − 2 = 2𝜇 𝑡 − 1 − 𝜇 𝑡 − 2 + 𝜀 𝜇 𝑡 − 2 (12.3) 一つ前 状態撹乱項 一つ前 状態撹乱項 傾き(単位時間あたりの変化量) 2階差分を考えるとなにがうれしいのか? • 推定された𝜇の変化が滑らかになる(平滑化される) • トレンドを考慮した予測ができる
17.
2階差分モデル (「 2階差分のトレンド項」を考慮したモデル) Stanでやってみよう 12.1.7 pp. 233
- 235 • 確かになめらか • 予測値も自然 図12.3(右) ベイズ信頼区間 model12-4.stan(抜粋) ※小森注:この「 2階差分のトレンド項」モデルは実際にはあまり使われな いように思います.そのかわり「トレンド方程式」を状態方程式に加えた 「ローカル線形トレンドモデル」のほうが用いられるかな. 𝜇 𝑡 ~ Normal 𝜇 𝑡 − 1 + 𝑣[𝑡], 𝜎𝜇 状態方程式(レベル) 𝑣 𝑡 ~ Normal 𝑣 𝑡 − 1 , 𝜎𝑣 状態方程式(トレンド) 𝑌 𝑡 ~ Normal 𝜇 𝑡 , 𝜎 𝑌 観測方程式
18.
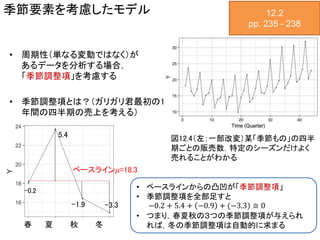
季節要素を考慮したモデル 12.2 pp. 235
- 238 • 周期性(単なる変動ではなく)が あるデータを分析する場合, 「季節調整項」を考慮する • 季節調整項とは?(ガリガリ君最初の1 年間の四半期の売上を考える) 図12.4(左;一部改変)某「季節もの」の四半 期ごとの販売数.特定のシーズンだけよく 売れることがわかる ベースライン𝜇=18.3 春 夏 秋 冬 -0.2 5.4 -1.9 -3.3 • ベースラインからの凸凹が「季節調整項」 • 季節調整項を全部足すと −0.2 + 5.4 + −0.9 + (−3.3) ≅ 0 • つまり,春夏秋の3つの季節調整項が与えられ れば,冬の季節調整項は自動的に求まる
19.
季節要素を考慮したモデル 12.2 pp. 235 -
238 • 周期𝐿の周期データであれば𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 は小さい値になる 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 + 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 1 + ⋯ + 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 𝐿 − 1 = 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛[𝑡] • ガリガリ君の場合であれば(ただし春= 𝑡とすると) 𝑠𝑒𝑎𝑠𝑜𝑛 春 + 𝑠𝑒𝑎𝑠𝑜𝑛 夏 + 𝑠𝑒𝑎𝑠𝑜𝑛 秋 + 𝑠𝑒𝑎𝑠𝑜𝑛 冬 = 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛[𝑡] • ここで𝜀 𝑠𝑒𝑎𝑠𝑜𝑛[𝑡]が正規分布𝒩(0, 𝜎𝑠𝑒𝑎𝑠𝑜𝑛 2 ) に従うとすると 𝑙=0 𝐿−1 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 𝑙 = 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 ~Normal(0, 𝜎𝑠𝑒𝑎𝑠𝑜𝑛) 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 = − 𝑙=1 𝐿−1 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 𝑙 + 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 ~Normal(0, 𝜎𝑠𝑒𝑎𝑠𝑜𝑛) ※春夏秋冬を全部足した値は平均0の正規分布に従う ※ある季節(春)の季節調整項は残りの季節(夏秋冬)の合計+𝜀 𝑠𝑒𝑎𝑠𝑜𝑛になる この関係式をStanのモデルに入れてやればいいだけ
20.
季節要素を考慮したモデル Stanでやってみよう 12.2 pp. 235 -
238 model12-6.stan 𝑙=1 𝐿−1 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 𝑙 modelに「Y ~ normal(mu + season, s_Y);」 と書いてtransformed parametersを消しても 特に問題ないけど,y_meanを出力するためにこの ように書いているのかな? 推定されたトレンド項𝜇 𝑡 季節調整項𝑠𝑒𝑎𝑠𝑜𝑛 𝑡
21.
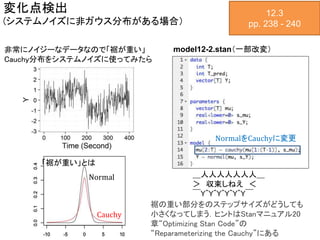
変化点検出 (システムノイズに非ガウス分布がある場合) 12.3 pp. 238 -
240 model12-2.stan(一部改変) NormalをCauchyに変更 非常にノイジーなデータなので「裾が重い」 Cauchy分布をシステムノイズに使ってみたら _人人人人人人人_ > 収束しねえ <  ̄Y^Y^Y^Y^Y^Y ̄ 裾の重い部分をのステップサイズがどうしても 小さくなってしまう.ヒントはStanマニュアル20 章“Optimizing Stan Code”の “Reparameterizing the Cauchy”にある Normal Cauchy 「裾が重い」とは
22.
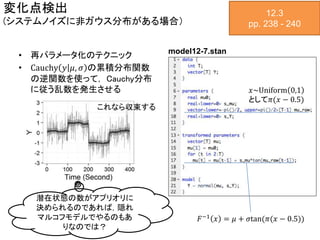
変化点検出 (システムノイズに非ガウス分布がある場合) • 再パラメータ化のテクニック • Cauchy
𝑦 𝜇, 𝜎 の累積分布関数 の逆関数を使って, Cauchy分布 に従う乱数を発生させる 12.3 pp. 238 - 240 model12-7.stan 𝑥~Uniform 0,1 として𝜋(𝑥 − 0.5) 𝐹−1 𝑥 = 𝜇 + 𝜎tan(𝜋(𝑥 − 0.5)) これなら収束する 潜在状態の数がアプリオリに 決められるのであれば,隠れ マルコフモデルでやるのもあ りなのでは?
23.
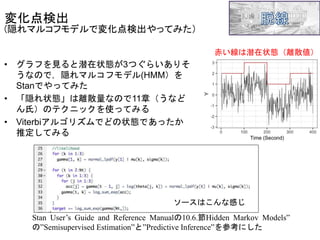
• グラフを見ると潜在状態が3つぐらいありそ うなので,隠れマルコフモデル(HMM)を Stanでやってみた • 「隠れ状態」は離散量なので11章(うなど ん氏)のテクニックを使ってみる •
Viterbiアルゴリズムでどの状態であったか 推定してみる 変化点検出 (隠れマルコフモデルで変化点検出やってみた) ソースはこんな感じ 赤い線は潜在状態(離散値) Stan User’s Guide and Reference Manualの10.6.節Hidden Markov Models” の”Semisupervised Estimation”と”Predictive Inference”を参考にした
24.
その他の拡張方法 • 独自のトレンド項を入れる • データの対数をとる •
時刻が不等間隔のとき – 等間隔の目盛りを取って,丸める. データが無いところは欠損値にする • 複数の要因を入れる • 複数の𝜇 𝑡 – 複数回の試行を行う場合や,複数人の被験 者を対象にする時など.観測撹乱項,状態 撹乱項を工夫すると良いかも 12.4 pp. 240 - 241 𝜇 𝑛, 𝑡 = 𝜇 𝑛, 𝑡 − 1 + 𝜀 𝜇[𝑛, 𝑡 − 1] 𝑌 𝑛, 𝑡 = 𝜇 𝑛, 𝑡 + 𝜀 𝑌[𝑛, 𝑡] 𝜀 𝜇 𝑛, 𝑡 ~𝑁𝑜𝑟𝑚𝑎𝑙 0, 𝜎𝜇 𝑛 𝜀 𝑌 𝑛, 𝑡 ~𝑁𝑜𝑟𝑚𝑎𝑙 0, 𝜎 𝑌 ■モデル式12−9■ 状態撹乱項は個人差あり 「3階差分を使うのも良いし…」と 本にあるが,時系列の場合は2階 差分,空間構造の場合は1階差 分でいいのでは? スプラインとか カルマンフィルタと かで補完をしたデー タを使っちゃダメョ 観測撹乱項は被験者間で共通
25.
時間構造と空間構造の等価性 1階差分モデルを例に • DAG(非巡回有向グラフ)で表現される • システムモデル 𝜇
𝑡 = 𝜇 𝑡 − 1 +𝜀 𝜇 [𝑡] 𝜀 𝜇[𝑡]~𝑁𝑜𝑟𝑚𝑎𝑙 0, 𝜎𝜇 • 条件付き確率 𝑝 𝜇 𝑡 𝜇 𝑡−1 = 1 2𝜋𝑟2 exp(− 1 2𝜎𝜇 2 𝜇 𝑡 − 𝜇 𝑡−1 2 ) • 観測モデルは有向グラフだが,シ ステムモデルは無向グラフ • (1次元空間の場合は)結果は変 わらないが,無向グラフであること を明示的に示すため同時確率で 表す 12.5 pp. 242 - 244 今まで扱ってきた状態空間モデル 1次元の空間構造(マルコフ場)モデル 𝑝(𝜇1, 𝜇2, … 𝜇 𝑇) ∝ exp − 1 2𝜎𝜇 2 𝑡=2 𝑇 (𝜇 𝑡 − 𝜇 𝑡−1)2 対数事後確率を見れば状態空間モデルとマルコフ場モデルは等価. だけど(多分)2次元モデルになった時に説明が超めんどいのもあって このような記法にしている(それにそもそもStanでは右の書き方が本質的)
26.
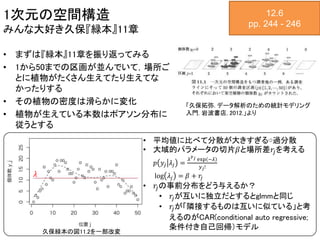
1次元の空間構造 みんな大好き久保『緑本』11章 12.6 pp. 244 -
246 • まずは『緑本』11章を振り返ってみる • 1から50までの区画が並んでいて,場所ご とに植物がたくさん生えてたり生えてな かったりする • その植物の密度は滑らかに変化 • 植物が生えている本数はポアソン分布に 従うとする 「久保拓弥. データ解析のための統計モデリング 入門. 岩波書店, 2012.」より 𝜆 • 平均値に比べて分散が大きすぎる⇨過分散 • 大域的パラメータの切片𝛽と場所差𝑟𝑗を考える 𝑝 𝑦𝑗 𝜆𝑗 = 𝜆 𝑦 𝑗 exp −𝜆 𝑦 𝑗! log 𝜆𝑗 = 𝛽 + 𝑟𝑗 • 𝑟𝑗の事前分布をどう与えるか? • 𝑟𝑗が互いに独立だとするとglmmと同じ • 𝑟𝑗が「隣接するものは互いに似ている」と考 えるのがCAR(conditional auto regressive; 条件付き自己回帰)モデル 久保緑本の図11.2を一部改変
27.
12.6 pp. 244 -
246 1次元の空間構造 久保『緑本』11章とアヒル本12.6節の関係 • 緑本で紹介されているIntrinsic Gaussian CAR model(条件付き自己 回帰モデル) 𝑝 𝑟𝑗 𝜇 𝑗, 𝑠 = 𝑛𝑗 2𝜋𝑠2 𝑒𝑥𝑝 − 𝑟𝑗 − 𝜇 𝑗 2 2𝑠2/𝑛𝑗 ただし𝜇 𝑗 = 𝑟 𝑗−1+𝑟 𝑗+1 2 • この式は2階差分になっている 𝑟𝑗 − 𝜇 𝑗 2 = 2𝑟 𝑗−𝑟 𝑗−1−𝑟 𝑗+1 2 2 = 𝑟 𝑗+1−𝑟 𝑗 − 𝑟 𝑗−𝑟 𝑗−1 2 2 • 注意:緑本のこのモデル式は「𝑟𝑗−1や 𝑟𝑗+1が固定されている場合の𝑟𝑗の確 率分布」を表す式(full conditionalと呼 ばれるらしい)であって条件付き分布 とは異なる • 一方アヒル本のモデル式12−11では 一階差分(式12.9) 𝑝 𝑟 1 , 𝑟 2 , … , 𝑟 𝐼 ∝ 1 𝜎𝑟 𝐴 exp − 1 2𝜎𝑟 2 𝑖,𝑗 𝑟[𝑖] − 𝑟[𝑖 − 1] 2 • 注意:事後(同時)確率で書かれてて, この式を展開して𝑟[𝑖] について平方 完成すれば2階差分になるよね • アヒル本の式から緑本の式は導ける けど,逆はわからん この2つのモデル(CARモデルと1階差分モデル)は同じもの このあたりの議論は下記に詳しく解説あり 伊庭幸人 時間・空間を含むベイズモデルのいろいろな 表現形式, 岩波データサイエンス vol.1, 96-106.
28.
1次元の空間構造 • 観測モデルについて – こちらは有向グラフで表現でき るので通常の書き方 •
結果 12.6 pp. 244 - 246 model12-11.stan(1階差分モデル) model12-12.stan(2階差分モデル;抜粋) r[2,I] ~ normal(r[1:(T-1)],s_r); と同じ結果になる 1階差分モデル 2階差分モデル 緑本と同じ結果 対数リンク関数とセットになった poisson_log()がいろいろ便利らしい
29.
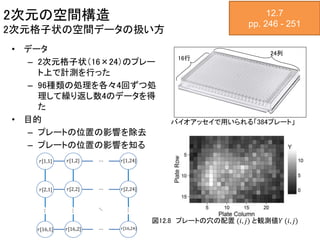
2次元の空間構造 2次元格子状の空間データの扱い方 • データ – 2次元格子状(16×24)のプレー ト上で計測を行った –
96種類の処理を各々4回ずつ処 理して繰り返し数4のデータを得 た • 目的 – プレートの位置の影響を除去 – プレートの位置の影響を知る 12.7 pp. 246 - 251 バイオアッセイで用いられる「384プレート」 24列 16行 図12.8 プレートの穴の配置 (𝑖, 𝑗) と観測値𝑌 (𝑖, 𝑗)
30.
• 縦横ともに2階差分モデルで考える • 𝑌
𝑖, 𝑗 = 𝑟 𝑖, 𝑗 + 𝛽[𝑇𝐼𝐷 𝑖, 𝑗 ] • 𝑝 𝑟 1,1 , 𝑟 1,2 , … , 𝑟 16,24 ∝ 1 𝜎𝑟 𝐴 exp − 1 2𝜎𝑟 2 𝑖,𝑗 𝑟[𝑖, 𝑗] − 2𝑟[𝑖, 𝑗 − 1] + 𝑟[𝑖, 𝑗 − 2] 2 2次元の空間構造 2次元格子状の空間データの扱い方 12.7 pp. 246 - 251 model12-13.stan
31.
2次元の空間構造 2次元格子状の空間データの扱い方 12.7 pp. 246 -
251 • 初期値を与えるテクニック – 局所解に陥らないようだいたいの あたりをつけた初期値を使う まずLOESS(局所回帰) をやってる LOESSの結果を初期値として投入 run-model12-13.R(抜粋) 図12.9(左)𝑟[𝑖, 𝑗]の中央値 図12.9(右)単純な平均値と 推定結果の関係(95%信頼区間)
32.
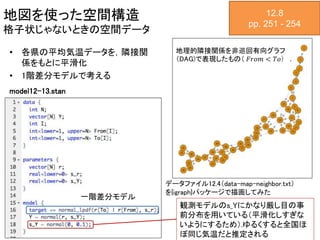
地図を使った空間構造 格子状じゃないときの空間データ 12.8 pp. 251 -
254 • 各県の平均気温データを,隣接関 係をもとに平滑化 • 1階差分モデルで考える 地理的隣接関係を非巡回有向グラフ (DAG)で表現したもの( 𝐹𝑟𝑜𝑚 < 𝑇𝑜) . データファイル12.4(data-map-neighbor.txt) を{igraph}パッケージで描画してみた model12-13.stan 一階差分モデル 観測モデルのs_Yにかなり厳し目の事 前分布を用いている(平滑化しすぎな いようにするため).ゆるくすると全国ほ ぼ同じ気温だと推定される
33.
地図を使った空間構造 格子状じゃないときの空間データ 12.8 pp. 251 -
254 図12.10(左)観測値,(右)推定された𝑟[𝑛] の中央値 平均気温 マルコフ場モデルに より平滑化した気温 図12.11 実測値と予測値 図12.11 𝑌 𝑛 − 𝑟 𝑛 のMAP推定値 のヒストグラムと密度関数 ※ 本書のソースにある事前分布 s_Y ~ normal(0, 0.1); だと本の図の通りの結果にはならない 𝜎 = 0.08ぐらいにすればいいかも?
Download




![状態空間モデルことはじめ(概要)
• 状態空間モデルでは真の状態𝜇と観測値𝑌を区別する
– 真の状態は直接は観測できない
– 観測値は時々刻々得られる
真の状態𝜇
観測値𝑌
𝜇[1] 𝜇[2] 𝜇[𝑇]
𝑌[2]𝑌[1] 𝑌[𝑇]
⋯
⋯
システムモデル(状態方程式)
「真の状態」の前後の関係式
観測モデル(観測方程式)
「真の値」は観測値に
その都度反映される](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-7-320.jpg)
![状態空間モデルことはじめ(概要)
• 一番簡単なローカルレベルモデル(酔歩+ノイズ)の例
– 12.1.3節■モデル式12−2■(1階差分のトレンド項モデル)
𝜇 𝑡 ~ Normal 𝜇 𝑡 − 1 , 𝜎𝜇 システムモデル(状態方程式)
𝑌 𝑡 ~ Normal 𝜇 𝑡 , 𝜎 𝑌 観測モデル(観測方程式)
真の状態𝜇
観測値𝑌
𝜇[1] 𝜇[2] 𝜇[𝑇]
𝑌[2]
𝑌[1] 𝑌[𝑇]
⋯
システムモデル
観測モデル
⋯
+𝜀 𝜇1 +𝜀 𝜇2 +𝜀 𝜇𝑇−1
+𝜀 𝑌1
+𝜀 𝑌2
+𝜀 𝑌𝑇
(状態撹乱項) (状態撹乱項)
(観測撹乱項)
(観測撹乱項)](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-8-320.jpg)
![状態空間モデルことはじめ(書き方)
ローカルレベルモデルを例に
• 本書でのモデルの書き方
𝜇 𝑡 ~ Normal 𝜇 𝑡 − 1 , 𝜎𝜇
𝑌 𝑡 ~ Normal 𝜇 𝑡 , 𝜎 𝑌
• こんな風に書かれることも
𝜇 𝑡 = 𝜇 𝑡−1 + 𝜀 𝜇 𝜀 𝜇~NID(0, 𝜎𝜇)
𝑦𝑡 = 𝜇 𝑡 + 𝜀 𝑌 𝜀 𝑌~NID(0, 𝜎 𝑌)
• 一般的には
𝛍t = 𝐓𝐭 𝛍𝐭−𝟏 + 𝐑 𝐭 𝛆 𝛍
𝐲𝐭 = 𝐙𝐭 𝛍𝐭 + 𝛆 𝐘
• Stanでの(スマートな)書き方
model {
mu[2:T] ~ normal(mu[1:(T-1)], s_mu);
Y ~ normal(mu, s_Y);
}
• Stanでの(わかりやすい)書き方
model {
for( t in 2 : T){
mu[t] ~ normal(mu[t-1], s_mu);
}
Y ~ normal(mu, s_Y);
}
システムモデル(状態方程式)
観測モデル(観測方程式)](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-9-320.jpg)
![ローカルレベルモデル
(「1階差分のトレンド項」を考慮したモデル)
• ローカルレベルモデルは
「ランダムウォークプラスノイズモデル」
とも呼ばれる
• 𝜇に正規ノイズ(状態撹乱項)𝜀 𝜇が累積加算されていく過程
𝜇 𝑡 = 𝜇 𝑡 − 1 + 𝜀 𝜇 𝑡 𝜀 𝜇 𝑡 ~Normal 0, 𝜎𝜇
12.1.1 – 12.1.5
pp. 231 - 233
初期値=0, σμ=1 に設定した
for (t in 2:N)
y[t] <- rnorm(1, y[t-1], sigma)
• ランダムウォーク(酔歩)とは?
描いてみた](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-10-320.jpg)
![ローカルレベルモデル
(「 1階差分のトレンド項」を考慮したモデル)
• ローカルレベルモデルはランダムウォークに観測撹乱項が加
わった観測値𝑌 から, 以下のパラメータを推定する
• 𝜇[𝑡],𝜎𝜇,𝜎 𝑌
12.1.1 – 12.1.5
pp. 231 - 233
真の状態𝜇
観測値𝑌
𝜇[1] 𝜇[2] 𝜇[𝑇]
𝑌[2]
𝑌[1] 𝑌[𝑇]
⋯
システムモデル
観測モデル
⋯
+𝜀 𝜇1 +𝜀 𝜇2 +𝜀 𝜇𝑇−1
+𝜀 𝑌1
+𝜀 𝑌2
+𝜀 𝑌𝑇
(状態撹乱項) (状態撹乱項)
(観測撹乱項)
(観測撹乱項)
𝜇 𝑡 ~ Normal 𝜇 𝑡 − 1 , 𝜎𝜇 𝑡 = 2, … , 𝑇 (12.1)
𝑌 𝑡 ~ Normal 𝜇 𝑡 , 𝜎 𝑌 𝑡 = 1, … , 𝑇 (12.2)](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-11-320.jpg)
![ローカルレベルモデル
(「 1階差分のトレンド項」を考慮したモデル)
Stanでやってみよう
• イベントの21日分の来場者数データからパラメータを推定
12.1.1 – 12.1.5
pp. 231 - 233
図12.1(右) イベント来場者
data {
int T;
int T_pred;
vector[T] Y;
}
parameters {
vector[T] mu;
real<lower=0> s_mu;
real<lower=0> s_Y;
}
model {
mu[2:T] ~ normal(mu[1:(T-1)], s_mu);
Y ~ normal(mu, s_Y);
}
model12-2.stan(抜粋)
システムモデル(状態方程式)
観測モデル(観測方程式)](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-12-320.jpg)
![ローカルレベルモデル
(「 1階差分のトレンド項」を考慮したモデル)
ついでに今後の予測もStanでやってみよう
• generated quantitiesで将来の来場者の予測もできる
12.1.1 – 12.1.5
pp. 231 - 233
generated quantities {
vector[T+T_pred] mu_all;
vector[T_pred] y_pred;
mu_all[1:T] = mu;
for (t in 1:T_pred) {
mu_all[T+t] = normal_rng(mu_all[T+t-1],
s_mu);
y_pred[t] = normal_rng(mu_all[T+t], s_Y);
}
}
※もちろんgenerated quantities
を使わずにRで乱数を発生させて予
測することもできるし,また,将来の
値を「欠損値」とみなしてmodel{}内で
予測することも可能(「Stanで体重の
推移をみつめてみた(状態空間モデ
ル) @kosugittiさん参照)
「ガキの使いとちゃうねんぞ」という
レベルの予測.
もっと減っていきそうなのに…
所詮はランダムウォークモデル.
できるのはこの程度
ローカルレベルモデルでは
流石にモデルが単純すぎるのでは?](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-14-320.jpg)

![2階差分モデル
(「 2階差分のトレンド項」を考慮したモデル)
Stanでやってみよう
12.1.7
pp. 233 - 235
• 確かになめらか
• 予測値も自然
図12.3(右) ベイズ信頼区間
model12-4.stan(抜粋)
※小森注:この「 2階差分のトレンド項」モデルは実際にはあまり使われな
いように思います.そのかわり「トレンド方程式」を状態方程式に加えた
「ローカル線形トレンドモデル」のほうが用いられるかな.
𝜇 𝑡 ~ Normal 𝜇 𝑡 − 1 + 𝑣[𝑡], 𝜎𝜇 状態方程式(レベル)
𝑣 𝑡 ~ Normal 𝑣 𝑡 − 1 , 𝜎𝑣 状態方程式(トレンド)
𝑌 𝑡 ~ Normal 𝜇 𝑡 , 𝜎 𝑌 観測方程式](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-17-320.jpg)
![季節要素を考慮したモデル
12.2
pp. 235 - 238
• 周期𝐿の周期データであれば𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 は小さい値になる
𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 + 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 1 + ⋯ + 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 𝐿 − 1 = 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛[𝑡]
• ガリガリ君の場合であれば(ただし春= 𝑡とすると)
𝑠𝑒𝑎𝑠𝑜𝑛 春 + 𝑠𝑒𝑎𝑠𝑜𝑛 夏 + 𝑠𝑒𝑎𝑠𝑜𝑛 秋 + 𝑠𝑒𝑎𝑠𝑜𝑛 冬 = 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛[𝑡]
• ここで𝜀 𝑠𝑒𝑎𝑠𝑜𝑛[𝑡]が正規分布𝒩(0, 𝜎𝑠𝑒𝑎𝑠𝑜𝑛
2 ) に従うとすると
𝑙=0
𝐿−1
𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 𝑙 = 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 ~Normal(0, 𝜎𝑠𝑒𝑎𝑠𝑜𝑛)
𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 = −
𝑙=1
𝐿−1
𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 − 𝑙 + 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 𝜀 𝑠𝑒𝑎𝑠𝑜𝑛 𝑡 ~Normal(0, 𝜎𝑠𝑒𝑎𝑠𝑜𝑛)
※春夏秋冬を全部足した値は平均0の正規分布に従う
※ある季節(春)の季節調整項は残りの季節(夏秋冬)の合計+𝜀 𝑠𝑒𝑎𝑠𝑜𝑛になる
この関係式をStanのモデルに入れてやればいいだけ](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-19-320.jpg)

![その他の拡張方法
• 独自のトレンド項を入れる
• データの対数をとる
• 時刻が不等間隔のとき
– 等間隔の目盛りを取って,丸める.
データが無いところは欠損値にする
• 複数の要因を入れる
• 複数の𝜇 𝑡
– 複数回の試行を行う場合や,複数人の被験
者を対象にする時など.観測撹乱項,状態
撹乱項を工夫すると良いかも
12.4
pp. 240 - 241
𝜇 𝑛, 𝑡 = 𝜇 𝑛, 𝑡 − 1 + 𝜀 𝜇[𝑛, 𝑡 − 1]
𝑌 𝑛, 𝑡 = 𝜇 𝑛, 𝑡 + 𝜀 𝑌[𝑛, 𝑡]
𝜀 𝜇 𝑛, 𝑡 ~𝑁𝑜𝑟𝑚𝑎𝑙 0, 𝜎𝜇 𝑛
𝜀 𝑌 𝑛, 𝑡 ~𝑁𝑜𝑟𝑚𝑎𝑙 0, 𝜎 𝑌
■モデル式12−9■
状態撹乱項は個人差あり
「3階差分を使うのも良いし…」と
本にあるが,時系列の場合は2階
差分,空間構造の場合は1階差
分でいいのでは?
スプラインとか
カルマンフィルタと
かで補完をしたデー
タを使っちゃダメョ
観測撹乱項は被験者間で共通](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-24-320.jpg)
![時間構造と空間構造の等価性
1階差分モデルを例に
• DAG(非巡回有向グラフ)で表現される
• システムモデル
𝜇 𝑡 = 𝜇 𝑡 − 1 +𝜀 𝜇 [𝑡] 𝜀 𝜇[𝑡]~𝑁𝑜𝑟𝑚𝑎𝑙 0, 𝜎𝜇
• 条件付き確率
𝑝 𝜇 𝑡 𝜇 𝑡−1 =
1
2𝜋𝑟2
exp(−
1
2𝜎𝜇
2
𝜇 𝑡 − 𝜇 𝑡−1
2
)
• 観測モデルは有向グラフだが,シ
ステムモデルは無向グラフ
• (1次元空間の場合は)結果は変
わらないが,無向グラフであること
を明示的に示すため同時確率で
表す
12.5
pp. 242 - 244
今まで扱ってきた状態空間モデル 1次元の空間構造(マルコフ場)モデル
𝑝(𝜇1, 𝜇2, … 𝜇 𝑇) ∝ exp −
1
2𝜎𝜇
2
𝑡=2
𝑇
(𝜇 𝑡 − 𝜇 𝑡−1)2
対数事後確率を見れば状態空間モデルとマルコフ場モデルは等価.
だけど(多分)2次元モデルになった時に説明が超めんどいのもあって
このような記法にしている(それにそもそもStanでは右の書き方が本質的)](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-25-320.jpg)
![12.6
pp. 244 - 246
1次元の空間構造
久保『緑本』11章とアヒル本12.6節の関係
• 緑本で紹介されているIntrinsic
Gaussian CAR model(条件付き自己
回帰モデル)
𝑝 𝑟𝑗 𝜇 𝑗, 𝑠 =
𝑛𝑗
2𝜋𝑠2 𝑒𝑥𝑝 −
𝑟𝑗 − 𝜇 𝑗
2
2𝑠2/𝑛𝑗
ただし𝜇 𝑗 =
𝑟 𝑗−1+𝑟 𝑗+1
2
• この式は2階差分になっている
𝑟𝑗 − 𝜇 𝑗
2
=
2𝑟 𝑗−𝑟 𝑗−1−𝑟 𝑗+1
2
2
=
𝑟 𝑗+1−𝑟 𝑗 − 𝑟 𝑗−𝑟 𝑗−1
2
2
• 注意:緑本のこのモデル式は「𝑟𝑗−1や
𝑟𝑗+1が固定されている場合の𝑟𝑗の確
率分布」を表す式(full conditionalと呼
ばれるらしい)であって条件付き分布
とは異なる
• 一方アヒル本のモデル式12−11では
一階差分(式12.9)
𝑝 𝑟 1 , 𝑟 2 , … , 𝑟 𝐼 ∝
1
𝜎𝑟
𝐴 exp −
1
2𝜎𝑟
2
𝑖,𝑗
𝑟[𝑖] − 𝑟[𝑖 − 1] 2
• 注意:事後(同時)確率で書かれてて,
この式を展開して𝑟[𝑖] について平方
完成すれば2階差分になるよね
• アヒル本の式から緑本の式は導ける
けど,逆はわからん
この2つのモデル(CARモデルと1階差分モデル)は同じもの
このあたりの議論は下記に詳しく解説あり
伊庭幸人 時間・空間を含むベイズモデルのいろいろな
表現形式, 岩波データサイエンス vol.1, 96-106.](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-27-320.jpg)
![1次元の空間構造
• 観測モデルについて
– こちらは有向グラフで表現でき
るので通常の書き方
• 結果
12.6
pp. 244 - 246
model12-11.stan(1階差分モデル)
model12-12.stan(2階差分モデル;抜粋)
r[2,I] ~ normal(r[1:(T-1)],s_r);
と同じ結果になる
1階差分モデル
2階差分モデル
緑本と同じ結果
対数リンク関数とセットになった
poisson_log()がいろいろ便利らしい](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-28-320.jpg)
![• 縦横ともに2階差分モデルで考える
• 𝑌 𝑖, 𝑗 = 𝑟 𝑖, 𝑗 + 𝛽[𝑇𝐼𝐷 𝑖, 𝑗 ]
• 𝑝 𝑟 1,1 , 𝑟 1,2 , … , 𝑟 16,24 ∝
1
𝜎𝑟
𝐴 exp −
1
2𝜎𝑟
2
𝑖,𝑗
𝑟[𝑖, 𝑗] − 2𝑟[𝑖, 𝑗 − 1] + 𝑟[𝑖, 𝑗 − 2] 2
2次元の空間構造
2次元格子状の空間データの扱い方
12.7
pp. 246 - 251
model12-13.stan](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-30-320.jpg)
![2次元の空間構造
2次元格子状の空間データの扱い方
12.7
pp. 246 - 251
• 初期値を与えるテクニック
– 局所解に陥らないようだいたいの
あたりをつけた初期値を使う
まずLOESS(局所回帰)
をやってる
LOESSの結果を初期値として投入
run-model12-13.R(抜粋)
図12.9(左)𝑟[𝑖, 𝑗]の中央値
図12.9(右)単純な平均値と
推定結果の関係(95%信頼区間)](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-31-320.jpg)
![地図を使った空間構造
格子状じゃないときの空間データ
12.8
pp. 251 - 254
図12.10(左)観測値,(右)推定された𝑟[𝑛] の中央値
平均気温 マルコフ場モデルに
より平滑化した気温
図12.11 実測値と予測値
図12.11 𝑌 𝑛 − 𝑟 𝑛 のMAP推定値
のヒストグラムと密度関数
※ 本書のソースにある事前分布
s_Y ~ normal(0, 0.1);
だと本の図の通りの結果にはならない
𝜎 = 0.08ぐらいにすればいいかも?](https://image.slidesharecdn.com/osakastan6chapter12komoriupload-171117003108/85/Stan-R-Chapter12-33-320.jpg)
































































