Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
TK
Uploaded by
Takuya Kubo
57 views
テーマ別勉強会(R言語)#2.pdf
RA協議会テーマ別勉強会(R言語)の#2です
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 51
2
/ 51
3
/ 51
4
/ 51
5
/ 51
6
/ 51
7
/ 51
8
/ 51
9
/ 51
10
/ 51
11
/ 51
12
/ 51
13
/ 51
14
/ 51
15
/ 51
16
/ 51
17
/ 51
18
/ 51
19
/ 51
20
/ 51
21
/ 51
22
/ 51
23
/ 51
24
/ 51
25
/ 51
26
/ 51
27
/ 51
28
/ 51
29
/ 51
30
/ 51
31
/ 51
32
/ 51
33
/ 51
34
/ 51
35
/ 51
36
/ 51
37
/ 51
38
/ 51
39
/ 51
40
/ 51
41
/ 51
42
/ 51
43
/ 51
44
/ 51
45
/ 51
46
/ 51
47
/ 51
48
/ 51
49
/ 51
50
/ 51
51
/ 51
More Related Content
PPTX
Rプログラミング02 データ入出力編
by
wada, kazumi
PDF
第8回 大規模データを用いたデータフレーム操作実習(2)
by
Wataru Shito
PDF
R言語勉強会#4.pdf
by
Takuya Kubo
PDF
R言語勉強会#5.pdf
by
Takuya Kubo
PDF
R言語勉強会#3.pdf
by
Takuya Kubo
PDF
第9回 大規模データを用いたデータフレーム操作実習(3)
by
Wataru Shito
PDF
R言語勉強会#8.pdf
by
Takuya Kubo
PDF
初心者講習会資料(Osaka.r#6)
by
Masahiro Hayashi
Rプログラミング02 データ入出力編
by
wada, kazumi
第8回 大規模データを用いたデータフレーム操作実習(2)
by
Wataru Shito
R言語勉強会#4.pdf
by
Takuya Kubo
R言語勉強会#5.pdf
by
Takuya Kubo
R言語勉強会#3.pdf
by
Takuya Kubo
第9回 大規模データを用いたデータフレーム操作実習(3)
by
Wataru Shito
R言語勉強会#8.pdf
by
Takuya Kubo
初心者講習会資料(Osaka.r#6)
by
Masahiro Hayashi
Similar to テーマ別勉強会(R言語)#2.pdf
PDF
Rあんなときこんなとき(tokyo r#12)
by
Shintaro Fukushima
PPT
R intro
by
yayamamo @ DBCLS Kashiwanoha
PDF
20170923 excelユーザーのためのr入門
by
Takashi Kitano
PDF
第1回R勉強会@東京
by
Yohei Sato
PDF
統計解析環境Rによる統計処理の基本―検定と視覚化―
by
SAKAUE, Tatsuya
PDF
R入門(dplyrでデータ加工)-TokyoR42
by
Atsushi Hayakawa
PDF
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
PDF
第3回Rを使って統計分析を勉強する会
by
Nobuto Inoguchi
PDF
Tokyor60 r data_science_part1
by
Yohei Sato
PDF
R言語勉強会#6.pdf
by
Takuya Kubo
PPT
K010 appstat201201
by
t2tarumi
PDF
R language definition3.1_3.2
by
Yoshiteru Kamiyama
PDF
Tokyor23 doradora09
by
Nobuaki Oshiro
PPTX
統計環境R_データ入出力編2016
by
wada, kazumi
PPT
12-11-30 Kashiwa.R #5 初めてのR Rを始める前に知っておきたい10のこと
by
Haruka Ozaki
PDF
R言語勉強会#2.pdf
by
Takuya Kubo
PDF
初心者講習会資料(Osaka.R#5)
by
Masahiro Hayashi
PDF
初心者講習会資料(Osaka.R#7)
by
Masahiro Hayashi
PDF
外国語教育メディア学会第54回全国研究大会ワークショップ「Rによる外国語教育データの分析と可視化の基本」
by
SAKAUE, Tatsuya
PDF
テーマ別勉強会(R言語)#1.pdf
by
Takuya Kubo
Rあんなときこんなとき(tokyo r#12)
by
Shintaro Fukushima
R intro
by
yayamamo @ DBCLS Kashiwanoha
20170923 excelユーザーのためのr入門
by
Takashi Kitano
第1回R勉強会@東京
by
Yohei Sato
統計解析環境Rによる統計処理の基本―検定と視覚化―
by
SAKAUE, Tatsuya
R入門(dplyrでデータ加工)-TokyoR42
by
Atsushi Hayakawa
LET2011: Rによる教育データ分析入門
by
Yuichiro Kobayashi
第3回Rを使って統計分析を勉強する会
by
Nobuto Inoguchi
Tokyor60 r data_science_part1
by
Yohei Sato
R言語勉強会#6.pdf
by
Takuya Kubo
K010 appstat201201
by
t2tarumi
R language definition3.1_3.2
by
Yoshiteru Kamiyama
Tokyor23 doradora09
by
Nobuaki Oshiro
統計環境R_データ入出力編2016
by
wada, kazumi
12-11-30 Kashiwa.R #5 初めてのR Rを始める前に知っておきたい10のこと
by
Haruka Ozaki
R言語勉強会#2.pdf
by
Takuya Kubo
初心者講習会資料(Osaka.R#5)
by
Masahiro Hayashi
初心者講習会資料(Osaka.R#7)
by
Masahiro Hayashi
外国語教育メディア学会第54回全国研究大会ワークショップ「Rによる外国語教育データの分析と可視化の基本」
by
SAKAUE, Tatsuya
テーマ別勉強会(R言語)#1.pdf
by
Takuya Kubo
More from Takuya Kubo
PDF
R言語勉強会#0.pdf
by
Takuya Kubo
PDF
R言語勉強会#1.pdf
by
Takuya Kubo
PDF
テーマ別勉強会(R言語)#3.pdf
by
Takuya Kubo
PDF
R言語勉強会#10.pdf
by
Takuya Kubo
PDF
R言語勉強会#9.pdf
by
Takuya Kubo
PDF
テーマ別勉強会(R言語)#4.pdf
by
Takuya Kubo
PDF
R言語勉強会#7.pdf
by
Takuya Kubo
R言語勉強会#0.pdf
by
Takuya Kubo
R言語勉強会#1.pdf
by
Takuya Kubo
テーマ別勉強会(R言語)#3.pdf
by
Takuya Kubo
R言語勉強会#10.pdf
by
Takuya Kubo
R言語勉強会#9.pdf
by
Takuya Kubo
テーマ別勉強会(R言語)#4.pdf
by
Takuya Kubo
R言語勉強会#7.pdf
by
Takuya Kubo
テーマ別勉強会(R言語)#2.pdf
1.
第2回 R言語勉強会 横浜国立大学 研究推進機構 URA
久保琢也 2021年12月14日
2.
今日やること CSVファイル ❖ KAKENのデータを用いて簡単な集計を行う 機関 件数
金額 東京大学 70 13289640000 京都大学 39 7343310000 東北大学 32 6086600000 大阪大学 28 5210660000 理化学研究所 20 3658330000 1
3.
事前準備:データの取得 ❖ KAKEN より採択課題情報ダウンロード −
抽出条件 • 期間:2018年∼2021年 • 種目:基盤研究(S) • 形式:CSVファイル ⇨ 321件(2021年12月9日現在) − 保存方法 • 名前:kibanS.csv • 場所:デスクトップ https://kaken.nii.ac.jp 2
4.
事前準備:パッケージのインストール ❖ データの読み書き ❖ データフレームの操作 #
readrパッケージのインストール(※要インターネット環境) install.packages( readr ) # readrパッケージの呼び出し library( readr ) # dplyrパッケージのインストール(※要インターネット環境) install.packages( dplyr ) # dplyrパッケージの呼び出し library( dplyr ) 3
5.
データフレームの操作 -dplyr編- 4
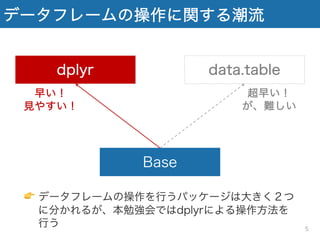
6.
データフレームの操作に関する潮流 Base dplyr data.table 超早い! が、難しい 早い! 見やすい! 👉 データフレームの操作を行うパッケージは大きく2つ に分かれるが、本勉強会ではdplyrによる操作方法を 行う
5
7.
dplyrとは ❖ A grammar
of data manipulation − Tidyverseパッケージ群の中のコアパッケージの1つ − データの操作や集計のための数々の便利な関数を備える ❖ Cheat sheet − https://github.com/rstudio/cheatsheets/blob/mast er/data-transformation.pdf − https://rstudio.com/wp-content/uploads/2015/02/ data-wrangling-cheatsheet.pdf 6
8.
Tidyverseとは ⃝背景にある理念 https://cran.r-project.org/web/packages/tidyverse/vignettes/manifesto.html https://cran.r-project.org/web/packages/tidyverse/vignettes/paper.html 7
9.
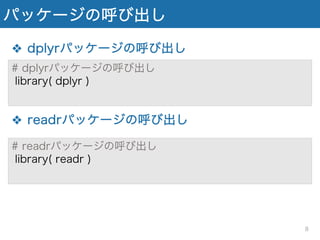
パッケージの呼び出し ❖ dplyrパッケージの呼び出し ❖ readrパッケージの呼び出し #
dplyrパッケージの呼び出し library( dplyr ) # readrパッケージの呼び出し library( readr ) 8
10.
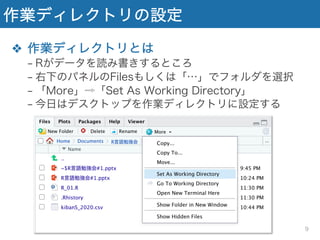
作業ディレクトリの設定 ❖ 作業ディレクトリとは − Rがデータを読み書きするところ −
右下のパネルのFilesもしくは「…」でフォルダを選択 − 「More」⇨「Set As Working Directory」 − 今日はデスクトップを作業ディレクトリに設定する 9
11.
作業ディレクトリの設定 ❖ 作業ディレクトリ/ファイルの確認 # 作業ディレクトリの確認 getwd(
) # 作業ディレクトリ内のファイルの確認 list.files( ) 10
12.
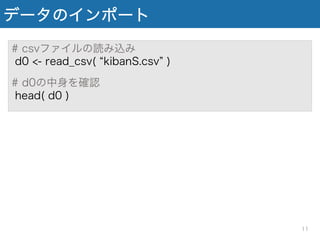
データのインポート # csvファイルの読み込み d0 <-
read_csv( kibanS.csv ) # d0の中身を確認 head( d0 ) 11
13.
データの要約 # 行数と列数の取得 dim( d0
) # 列名の取得 names( d0 ) # データの構造の取得 str( d0 ) # 各列のサマリーの取得 summary( d0 ) 12
14.
今日の勉強会で扱う内容 l select( )
列の選択/列名変更 l rename( ) 列名変更 l mutate( ) 列の操作 l filter( ) 特定行の抽出 l group_by( ) l summarize( ) l %>% コードの連結 グループ集計 13
15.
select関数 列の選択 14
16.
select( )の使い方 select( df,
列名, 列名, … ) # d0から研究機関, 審査区分, 研究種目, 総配分額だけ選択 d1 <- select( d0, 研究機関, 審査区分, 研究種目, 総配分額 ) # 確認 head( d1 ) − 「 df 」はデータフレーム(以下、同) − 列名は任意の数を指定可能 − 列名に「 」は不要 15
17.
select( )で列名を変える select( df,
新列名 = 列名, … ) # d0から研究機関, 審査区分, 研究種目, 総配分額を選択し、 研究機関と審査区分と研究種目の列名を変える d2 <- select( d0, 機関 = 研究機関, 分野 = 審査区分, 種目 = 研究種目, 総配分額 ) # 確認 head( d2 ) 改行してもコンマは忘れない 16
18.
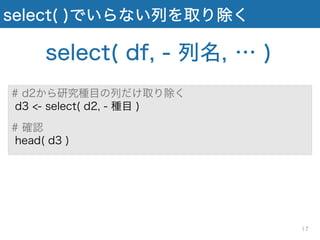
select( )でいらない列を取り除く select( df,
- 列名, … ) # d2から研究種目の列だけ取り除く d3 <- select( d2, - 種目 ) # 確認 head( d3 ) 17
19.
rename関数 列名の変更 18
20.
rename( )の使い方 # d3から総配分額の列名を変える d4
<- rename( d3, 金額 = 総配分額 ) # 確認 head( d4 ) rename( df, 新列名 = 列名, … ) 19
21.
mutate関数 列の操作 20
22.
mutate( )の使い方 # d4の金額の値を100万円単位に変える d5
<- mutate( d4, 金額_百万 = 金額/1000000 ) # 確認 head( d5 ) mutate( df, 新列名 = 値, … ) # d5の金額から間接経費を計算する mutate( d5, 間接 = 金額 * ( 3 / 13 ) ) 21
23.
filter関数 特定の行の抽出 22
24.
filter( )の使い方 # d5から金額が1億円未満の研究課題を抽出する filter(
d5, 金額_百万 < 100 ) # d5から金額が2億円以上の研究課題を抽出する filter( d5, 金額_百万 >= 200 ) filter( df, 条件式, … ) # d5から大区分Aの研究課題だけ抽出 filter( d5, 分野 == 大区分A ) # d5から大区分A以外の研究課題だけ抽出 filter( d5, 分野 != 大区分A ) 23
25.
比較演算子のおさらい # 「等しい」かどうかを判定 1 ==
1 # 「等しくない」かどうか判定 5 != 2 # 「左辺が右辺よりも大きい」かどうか判定 3 > 6 # 「右辺が左辺よりも大きい」かどうか判定 1 < 4 # 「左辺が右辺以上」かどうか判定 5 >= 8 # 「右辺が左辺以上」かどうか判定 1 <= 4 24
26.
❖ AND ❖ OR 複数条件の場合 #
d5から金額が1億円未満かつ、審査区分が大区分A filter( d5, 金額_百万 < 100 & 分野 == 大区分A ) # 同上 filter( d5, 金額_百万 < 150, 分野 == 大区分A ) # d5から金額が1億円未満、もしくは審査区分が大区分A filter( d5, 金額_百万 < 100 ¦ 分野 == 大区分A ) 25
27.
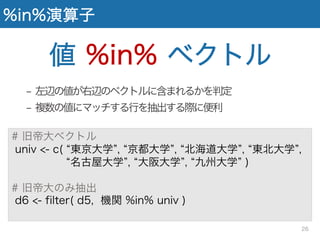
%in%演算子 値 %in% ベクトル −
左辺の値が右辺のベクトルに含まれるかを判定 − 複数の値にマッチする行を抽出する際に便利 # 旧帝大ベクトル univ <- c( 東京大学 , 京都大学 , 北海道大学 , 東北大学 , 名古屋大学 , 大阪大学 , 九州大学 ) # 旧帝大のみ抽出 d6 <- filter( d5, 機関 %in% univ ) 26
28.
group_by関数 summarize関数 グループ集計 27
29.
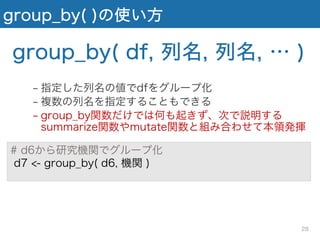
group_by( )の使い方 # d6から研究機関でグループ化 d7
<- group_by( d6, 機関 ) group_by( df, 列名, 列名, … ) − 指定した列名の値でdfをグループ化 − 複数の列名を指定することもできる − group_by関数だけでは何も起きず、次で説明する summarize関数やmutate関数と組み合わせて本領発揮 28
30.
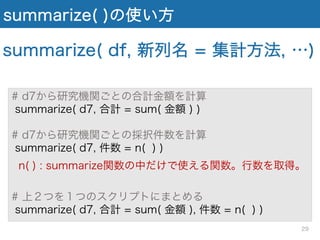
summarize( )の使い方 # d7から研究機関ごとの合計金額を計算 summarize(
d7, 合計 = sum( 金額 ) ) # d7から研究機関ごとの採択件数を計算 summarize( d7, 件数 = n( ) ) n( ) : summarize関数の中だけで使える関数。行数を取得。 # 上2つを1つのスクリプトにまとめる summarize( d7, 合計 = sum( 金額 ), 件数 = n( ) ) summarize( df, 新列名 = 集計方法, …) 29
31.
%>% コードを繋げる 30
32.
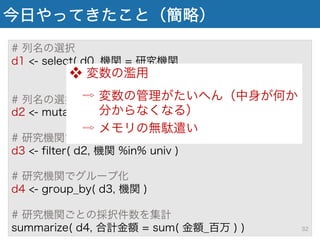
今日やってきたこと(簡略) # 列名の選択 d1 <-
select( d0, 機関 = 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) # 列名の選択 d2 <- mutate( d1, 金額_百万 = 金額/100000 ) # 研究機関でフィルタリング d3 <- filter( d2, 機関 %in% univ ) # 研究機関でグループ化 d4 <- group_by( d3, 機関 ) # 研究機関ごとの採択件数を集計 summarize( d4, 合計金額 = sum( 金額_百万 ) ) ※ナンバリングは先ほどと 異なりリセットしてます 31
33.
今日やってきたこと(簡略) # 列名の選択 d1 <-
select( d0, 機関 = 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) # 列名の選択 d2 <- mutate( d1, 金額_百万円 = 金額/100000 ) # 研究機関でフィルタリング d3 <- filter( d2, 機関 %in% univ ) # 研究機関でグループ化 d4 <- group_by( d3, 機関 ) # 研究機関ごとの採択件数を集計 summarize( d4, 合計金額 = sum( 金額_百万 ) ) ❖ 変数の濫用 ⇨ 変数の管理がたいへん(中身が何か 分からなくなる) ⇨ メモリの無駄遣い 32
34.
そんな時には %>% パイプ演算子 33
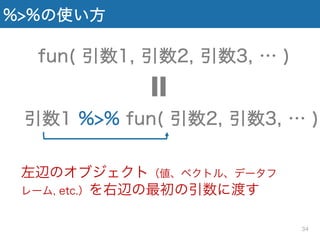
35.
%>%の使い方 fun( 引数1, 引数2,
引数3, … ) 引数1 %>% fun( 引数2, 引数3, … ) 左辺のオブジェクト(値、ベクトル、データフ レーム, etc.)を右辺の最初の引数に渡す 34
36.
%>%の使い方 # 列名の選択 select( d0,
研究機関, 審査区分, 総配分額 ) # 列名の選択(パイプ演算子) d0 %>% select( 研究機関, 審査区分, 総配分額 ) # 大学名フィルター filter( d0, 研究機関 %in% univ ) # 大学名フィルター(パイプ演算子) d0 %>% filter( 研究機関 %in% univ ) 35
37.
%>%の使い方 # 列名の選択(パイプ演算子) d0 %>% select(
研究機関, 審査区分, 総配分額 ) # 大学名フィルター(パイプ演算子) d0 %>% filter( 研究機関 %in% univ ) # 列名の選択(パイプ演算子) d0 %>% select( 研究機関, 審査区分, 総配分額 ) %>% filter( 研究機関 %in% univ ) パイプ演算子によって、複数の処理をわかりやすく、 まとめて記述することができる 36
38.
今日やってきたこと(再掲) # 列名の選択 d1 <-
select( d0, 機関 = 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) # 列名の選択 d2 <- mutate( d1, 金額_百万 = 金額/100000 ) # 研究機関でフィルタリング d3 <- filter( d2, 機関 %in% univ ) # 研究機関でグループ化 d4 <- group_by( d3, 機関 ) # 研究機関ごとの採択件数を集計 summarize( d4, 合計金額 = sum( 金額_百万 ) ) 37
39.
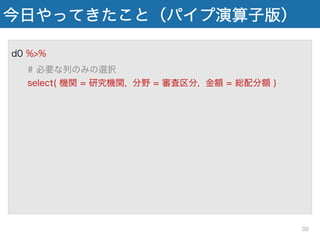
今日やってきたこと(パイプ演算子版) d0 # 必要な列のみの選択 select( 機関
= 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) %>% # 金額を100万円単位に変えた列を作成 mutate( 金額_百万円 = 金額/100000 ) %>% # 旧帝大の課題だけ抽出 filter( 機関 %in% univ ) %>% # 研究機関でグループ化 group_by( 機関 ) %>% # 研究機関ごとに合計金額を集計 suumarize( 合計金額 = sum( 金額_百万円 ) 38
40.
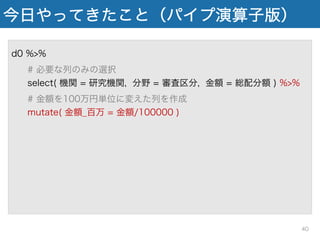
今日やってきたこと(パイプ演算子版) d0 %>% # 必要な列のみの選択 select(
機関 = 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) %>% # 金額を100万円単位に変えた列を作成 mutate( 金額_百万円 = 金額/100000 ) %>% # 旧帝大の課題だけ抽出 filter( 機関 %in% univ ) %>% # 研究機関でグループ化 group_by( 機関 ) %>% # 研究機関ごとに合計金額を集計 suumarize( 合計金額 = sum( 金額_百万円 ) 39
41.
今日やってきたこと(パイプ演算子版) d0 %>% # 必要な列のみの選択 select(
機関 = 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) %>% # 金額を100万円単位に変えた列を作成 mutate( 金額_百万 = 金額/100000 ) %>% # 旧帝大の課題だけ抽出 filter( 機関 %in% univ ) %>% # 研究機関でグループ化 group_by( 機関 ) %>% # 研究機関ごとに合計金額を集計 suumarize( 合計金額 = sum( 金額_百万円 ) 40
42.
今日やってきたこと(パイプ演算子版) d0 %>% # 必要な列のみの選択 select(
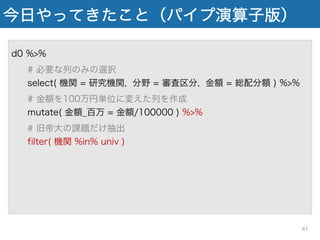
機関 = 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) %>% # 金額を100万円単位に変えた列を作成 mutate( 金額_百万 = 金額/100000 ) %>% # 旧帝大の課題だけ抽出 filter( 機関 %in% univ ) %>% # 研究機関でグループ化 group_by( 機関 ) %>% # 研究機関ごとに合計金額を集計 suumarize( 合計金額 = sum( 金額_百万円 ) 41
43.
今日やってきたこと(パイプ演算子版) d0 %>% # 必要な列のみの選択 select(
機関 = 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) %>% # 金額を100万円単位に変えた列を作成 mutate( 金額_百万 = 金額/100000 ) %>% # 旧帝大の課題だけ抽出 filter( 機関 %in% univ ) %>% # 研究機関でグループ化 group_by( 機関 ) %>% # 研究機関ごとに合計金額を集計 suumarize( 合計金額 = sum( 金額_百万円 ) 42
44.
今日やってきたこと(パイプ演算子版) d0 %>% # 必要な列のみの選択 select(
機関 = 研究機関, 分野 = 審査区分, 金額 = 総配分額 ) %>% # 金額を100万円単位に変えた列を作成 mutate( 金額_百万 = 金額/1000000 ) %>% # 旧帝大の課題だけ抽出 filter( 機関 %in% univ ) %>% # 研究機関でグループ化 group_by( 機関 ) %>% # 研究機関ごとに合計金額を集計 summarize( 合計金額 = sum( 金額_百万 ) ) 43
45.
練習問題 44
46.
問題① 大区分ごとに、①採択件数と総配分額の②最大値、 ③最小値を集計する d0 %>% # 「審査区分」列でグループ化 group_by(
審査区分 ) %>% # グループごとに採択件数と総配分額の最大値、最小値を集計 summarize( 件数 = n( ), 最大 = max( 総配分額 ), 最小 = min( 総配分額 ) ) 45
47.
問題② 旧帝大を除いて、最も基盤研究Sに採択されている 研究機関はどこか? ヒント① 旧帝大以外の判定: !(
研究機関 %in% univ ) TRUE / FALSE ! TRUE 👉 FALSE, !FALSE ⇨ TRUE ヒント② 並べ替えの関数:arrange( df, 列名 ) ※降順の際は arrange( df, - 列名 ) 46
48.
問題② 旧帝大を除いて、最も基盤研究Sに採択されている 研究機関はどこか? d0 %>% # 旧帝大以外を抽出 filter(
!( 研究機関 %in% univ ) ) %>% # 研究機関でグループ化 group_by( 研究機関 ) %>% # 採択件数の集計 summarize( N = n( ) ) %>% # 降順で並べ替え arrange( -N ) 47
49.
データの入出力 48
50.
csvファイルのインポート/エクスポート インポート エクスポート base read.csv(
) write.csv( ) readr read_csv( ) write_csv( ) − readrパッケージはbaseパッケージよりも入出力がかな り早い。 − しかし、日本語を扱う場合、baseパッケージの方が文字 化けの問題を回避しやすい(気がする) ※ WindowsではKAKENデータのインポートが大変なので インポートではreadrパッケージを利用 49
51.
csvファイルのインポート/エクスポート # readrパッケージ write_csv( d0,
output1.csv ) # baseパッケージ write.csv( d0, output2.csv , fileEncoding = CP932 ) インポート エクスポート base read.csv( ) write.csv( ) readr read_csv( ) write_csv( ) 50
Download