More Related Content

PDF

PPT

PDF

PDF

PPTX
単一事例研究法と統計的推測:ベイズ流アプローチを架け橋として 
PDF

PDF
Rubinの論文(の行間)を読んでみる-傾向スコアの理論- 
PDF
DARM勉強会第3回 (missing data analysis) What's hot

PDF

PDF

PDF
構造方程式モデルによる因果推論: 因果構造探索に関する最近の発展 
PDF

PDF

PDF

PDF

PDF

PPTX

PDF

PDF
Cmdstanr入門とreduce_sum()解説 
PDF

PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ 
PDF

PDF

PDF

PPTX
心理学におけるオープンサイエンス入門(OSF&PsyArXiv編) 
PDF

PPTX
【読書会資料】『StanとRでベイズ統計モデリング』Chapter12:時間や空間を扱うモデル 
PPTX
Viewers also liked

PPTX
Fluentd,mongo db,rでお手軽ログ解析環境 
PDF

PPTX

PDF

PDF
Collaborativefilteringwith r 
PDF
「plyrパッケージで君も前処理スタ☆」改め「plyrパッケージ徹底入門」 
PDF

PPTX
Similar to Rでコンジョイント分析

PDF
SQLで身につける!初めてのレコメンド 〜 基礎から応用まで ~ 
PPT

PDF
tokyo webmining3 2010.04.17. 
PPT

PDF
Tokyo.R #22 Association Rules 
PDF

PPTX
機械学習 / Deep Learning 大全 (3) 時系列 / リコメンデーション編 
PPTX
Personalized Fashion Recommendation from Personal Social Media Data An Item t... 
DOCX

PDF

PDF

PDF

PDF

PDF

PDF
Retty recommendation project 
PPT

PPTX
Multiple optimization and Non-dominated sorting with rPref package in R 
PDF
![[Tokyor08] Rによるデータサイエンス�第2部 第3章 対応分析](https://cdn.slidesharecdn.com/ss_thumbnails/tokyor08-100827202403-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Tokyor08] Rによるデータサイエンス�第2部 第3章 対応分析 
PDF
More from osamu morimoto

PPTX

PDF

ODP

PDF
Tokyo r 11_self_organizing_map 
PDF
Tokyo.R8 brand positioning 2010.08.28. 
PDF

PDF

PDF
Rでコンジョイント分析
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
そこで直交計画
• 実験計画法の世界で生まれた
実験の回数を少なくするテク
ニック。
– 直交表と呼ばれる「どの属性
でも全ての要素が同じ数だけ
出現する、すべて異なる組み
合わせの表」を使う。
–直交表は各列間の相関係数が
ゼロになる。
– L8直交表なら全組み合わせで
128通りの実験が必要なとこ
ろが8通りの実験で済む(交
互作用を考えない場合)。
– それでも実験数が減らせない
場合、直交性を妥協して実験
数を減らす場合もある。
実験
番号
属性
A B C D E F G
1 1 1 1 1 1 1 1
2 1 1 1 2 2 2 2
3 1 2 2 1 1 2 2
4 1 2 2 2 2 1 1
5 2 1 2 1 2 1 2
6 2 1 2 2 1 2 1
7 2 2 1 1 2 2 1
8 2 2 1 2 1 1 2
※直交表の例:L8(27)直交表
詳しくは第22回Tokyo.Rでの @itoyan さん
の発表資料を参照してください。
「Rで実験計画法(後編)」
http://www.slideshare.net/itoyan110/r-
14261638
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
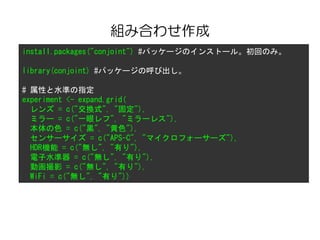
組み合わせ作成
install.packages("conjoint") #パッケージのインストール。初回のみ。
library(conjoint) #パッケージの呼び出し。
#属性と水準の指定
experiment <- expand.grid(
レンズ = c("交換式", "固定"),
ミラー = c("一眼レフ", "ミラーレス"),
本体の色 = c("黒", "黄色"),
センサーサイズ = c("APS-C", "マイクロフォーサーズ"),
HDR機能 = c("無し", "有り"),
電子水準器 = c("無し", "有り"),
動画撮影 = c("無し", "有り"),
WiFi = c("無し", "有り"))
- 13.
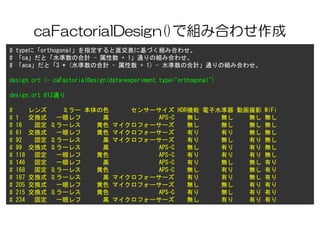
caFactorialDesign()で組み合わせ作成
# typeに「orthogonal」を指定すると直交表に基づく組み合わせ。
# 「ca」だと「水準数の合計- 属性数 + 1」通りの組み合わせ。
# 「aca」だと「3 * (水準数の合計 - 属性数 + 1) - 水準数の合計」通りの組み合わせ。
design.ort <- caFactorialDesign(data=experiment,type="orthogonal")
design.ort #12通り
# レンズ ミラー 本体の色 センサーサイズ HDR機能 電子水準器 動画撮影 WiFi
# 1 交換式 一眼レフ 黒 APS-C 無し 無し 無し 無し
# 16 固定 ミラーレス 黄色 マイクロフォーサーズ 無し 無し 無し 無し
# 61 交換式 一眼レフ 黄色 マイクロフォーサーズ 有り 有り 無し 無し
# 92 固定 ミラーレス 黒 マイクロフォーサーズ 有り 無し 有り 無し
# 99 交換式 ミラーレス 黒 APS-C 無し 有り 有り 無し
# 118 固定 一眼レフ 黄色 APS-C 有り 有り 有り 無し
# 146 固定 一眼レフ 黒 APS-C 有り 無し 無し 有り
# 168 固定 ミラーレス 黄色 APS-C 無し 有り 無し 有り
# 187 交換式 ミラーレス 黒 マイクロフォーサーズ 有り 有り 無し 有り
# 205 交換式 一眼レフ 黄色 マイクロフォーサーズ 無し 無し 有り 有り
# 215 交換式 ミラーレス 黄色 APS-C 有り 無し 有り 有り
# 234 固定 一眼レフ 黒 マイクロフォーサーズ 無し 有り 有り 有り
- 14.
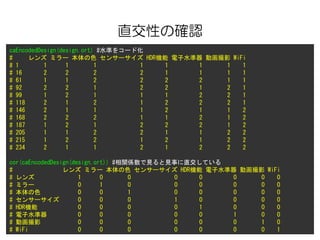
直交性の確認
caEncodedDesign(design.ort) #水準をコード化
# レンズミラー 本体の色 センサーサイズ HDR機能 電子水準器 動画撮影 WiFi
# 1 1 1 1 1 1 1 1 1
# 16 2 2 2 2 1 1 1 1
# 61 1 1 2 2 2 2 1 1
# 92 2 2 1 2 2 1 2 1
# 99 1 2 1 1 1 2 2 1
# 118 2 1 2 1 2 2 2 1
# 146 2 1 1 1 2 1 1 2
# 168 2 2 2 1 1 2 1 2
# 187 1 2 1 2 2 2 1 2
# 205 1 1 2 2 1 1 2 2
# 215 1 2 2 1 2 1 2 2
# 234 2 1 1 2 1 2 2 2
cor(caEncodedDesign(design.ort)) #相関係数で見ると見事に直交している
# レンズ ミラー 本体の色 センサーサイズ HDR機能 電子水準器 動画撮影 WiFi
# レンズ 1 0 0 0 0 0 0 0
# ミラー 0 1 0 0 0 0 0 0
# 本体の色 0 0 1 0 0 0 0 0
# センサーサイズ 0 0 0 1 0 0 0 0
# HDR機能 0 0 0 0 1 0 0 0
# 電子水準器 0 0 0 0 0 1 0 0
# 動画撮影 0 0 0 0 0 0 1 0
# WiFi 0 0 0 0 0 0 0 1
- 15.
- 16.
- 17.
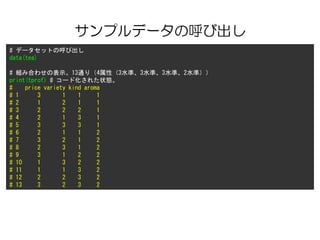
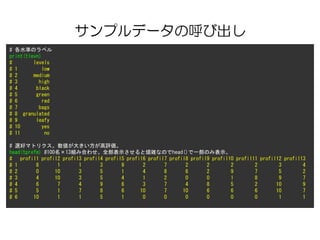
サンプルデータの呼び出し
# 各水準のラベル
print(tlevn)
# levels
#1 low
# 2 medium
# 3 high
# 4 black
# 5 green
# 6 red
# 7 bags
# 8 granulated
# 9 leafy
# 10 yes
# 11 no
# 選好マトリクス。数値が大きい方が高評価。
head(tprefm) #100名×13組み合わせ。全部表示させると煩雑なのでhead()で一部のみ表示。
# profil1 profil2 profil3 profil4 profil5 profil6 profil7 profil8 profil9 profil10 profil11 profil12 profil13
# 1 8 1 1 3 9 2 7 2 2 2 2 3 4
# 2 0 10 3 5 1 4 8 6 2 9 7 5 2
# 3 4 10 3 5 4 1 2 0 0 1 8 9 7
# 4 6 7 4 9 6 3 7 4 8 5 2 10 9
# 5 5 1 7 8 6 10 7 10 6 6 6 10 7
# 6 10 1 1 5 1 0 0 0 0 0 0 1 1
- 18.
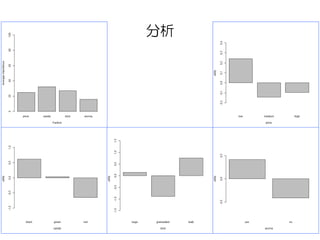
分析
# 引数は順に選好マトリクス、組み合わせ、水準のラベル
# 分析結果の値と同時に効用値と重要度のグラフが出力される。
Conjoint(tprefm,tprof, tlevn)
# [1] "Part worths (utilities) of levels (model parameters for whole sample):"
# levnms utls
# 1 intercept 3,5534
# 2 low 0,2402
# 3 medium -0,1431
# 4 high -0,0971
# 5 black 0,6149
# 6 green 0,0349
# 7 red -0,6498
# 8 bags 0,1369
# 9 granulated -0,8898
# 10 leafy 0,7529
# 11 yes 0,4108
# 12 no -0,4108
# [1] "Average importance of factors (attributes):"
# [1] 24,76 32,22 27,15 15,88
# [1] Sum of average importance: 100,01
# [1] "Chart of average factors importance"
効用値
重要度
- 19.
- 20.
- 21.
ベネフィット・セグメンテーション
# 引数は順に選好マトリクス、コード化した組み合わせ、分けたいクラスタの数
segments <-caSegmentation(tprefm, tprof, 4)
segments
# K-means clustering with 4 clusters of sizes 44, 13, 26, 17
#
# Cluster means:
# (省略)
# Clustering vector:
# [1] 1 2 3 4 4 1 3 2 4 3 3 3 1 1 1 1 2 1 4 1 1 3 1 4 3 1 2 3 4 4 1 3 2 4 3 3 3
# [38] 1 1 1 1 2 1 4 1 3 3 1 1 1 3 1 1 1 4 3 1 4 1 2 1 1 3 3 2 3 1 1 1 4 3 1 1 2
# [75] 3 4 4 1 3 1 2 3 4 3 1 1 1 1 2 1 2 1 4 1 1 3 1 2 4 3
# (以下略)
# segments$cluster とすればどのクラスタ番号が得られるので、他のデータと組み合わせて使う。
- 22.














![分析
# 引数は順に選好マトリクス、組み合わせ、水準のラベル
# 分析結果の値と同時に効用値と重要度のグラフが出力される。
Conjoint(tprefm, tprof, tlevn)
# [1] "Part worths (utilities) of levels (model parameters for whole sample):"
# levnms utls
# 1 intercept 3,5534
# 2 low 0,2402
# 3 medium -0,1431
# 4 high -0,0971
# 5 black 0,6149
# 6 green 0,0349
# 7 red -0,6498
# 8 bags 0,1369
# 9 granulated -0,8898
# 10 leafy 0,7529
# 11 yes 0,4108
# 12 no -0,4108
# [1] "Average importance of factors (attributes):"
# [1] 24,76 32,22 27,15 15,88
# [1] Sum of average importance: 100,01
# [1] "Chart of average factors importance"
効用値
重要度](https://image.slidesharecdn.com/r-130419230120-phpapp01/85/R-18-320.jpg)

![ベネフィット・セグメンテーション
# 引数は順に選好マトリクス、コード化した組み合わせ、分けたいクラスタの数
segments <- caSegmentation(tprefm, tprof, 4)
segments
# K-means clustering with 4 clusters of sizes 44, 13, 26, 17
#
# Cluster means:
# (省略)
# Clustering vector:
# [1] 1 2 3 4 4 1 3 2 4 3 3 3 1 1 1 1 2 1 4 1 1 3 1 4 3 1 2 3 4 4 1 3 2 4 3 3 3
# [38] 1 1 1 1 2 1 4 1 3 3 1 1 1 3 1 1 1 4 3 1 4 1 2 1 1 3 3 2 3 1 1 1 4 3 1 1 2
# [75] 3 4 4 1 3 1 2 3 4 3 1 1 1 1 2 1 2 1 4 1 1 3 1 2 4 3
# (以下略)
# segments$cluster とすればどのクラスタ番号が得られるので、他のデータと組み合わせて使う。](https://image.slidesharecdn.com/r-130419230120-phpapp01/85/R-21-320.jpg)
