Download as PDF, PPTX











![Information Retrieval
and Data Science
SPARKLER #3: OSGI Plugins
● Plugins Interfaces are inspired by Nutch
● Plugins are developed as per Open Service Gateway Interface (OSGI)
● We chose Apache Felix implementation of OSGI
● Migrated a plugin from Nutch
•Regex URL Filter Plugin → The most used plugin in Nutch
● Added JavaScript plugin (described in the next slide)
● //TODO: Migrate more plugins from Nutch
•Mavenize nutch [NUTCH-2293]
17Feb 7-9, 2017Spark Summit East 2017, Boston](https://image.slidesharecdn.com/1312singhnarayanaswamy-170215225415/75/Sparkler-Crawler-on-Apache-Spark-Spark-Summit-East-talk-by-Karanjeet-Singh-and-Thamme-Gowda-Narayanaswamy-17-2048.jpg)










The document discusses the development and features of 'Sparkler', a new open-source web crawler built on Apache Spark. It addresses motivations for creating Sparkler, including the need for real-time progress reports and modern infrastructure upgrades for web crawling, as well as details about its technology stack and functionalities. The presentation also outlines future plans for enhancements, such as scoring crawled pages and improved documentation.
Presentation on Sparkler, a new open-source web crawler, introduced by the IRDS group from USC.Introduction to Sparkler's capabilities, technology stack, and features set to improve web crawling.
Challenges in existing systems like MEMEX and Datoin drove the development of a new crawler based on Apache Spark.
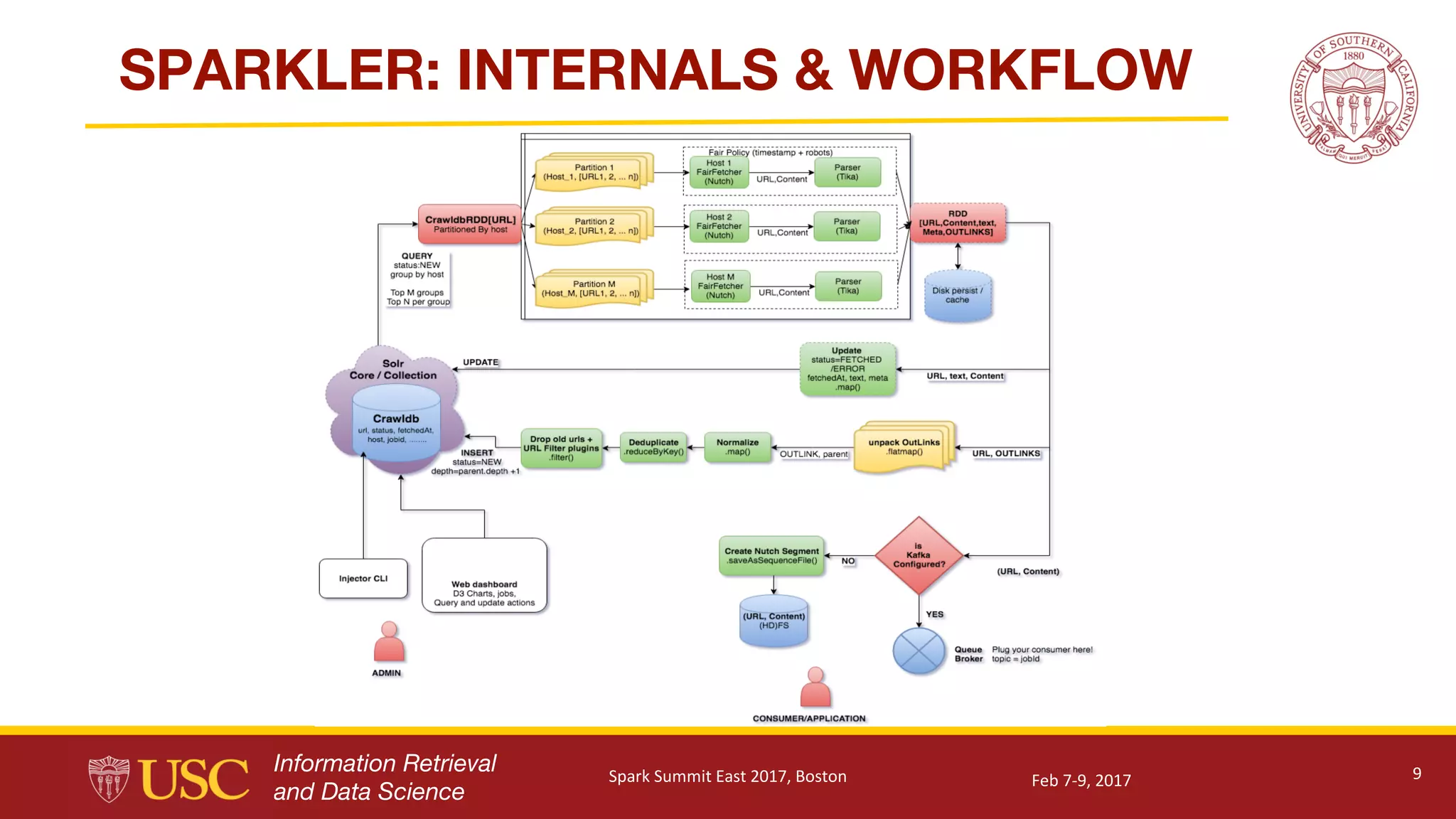
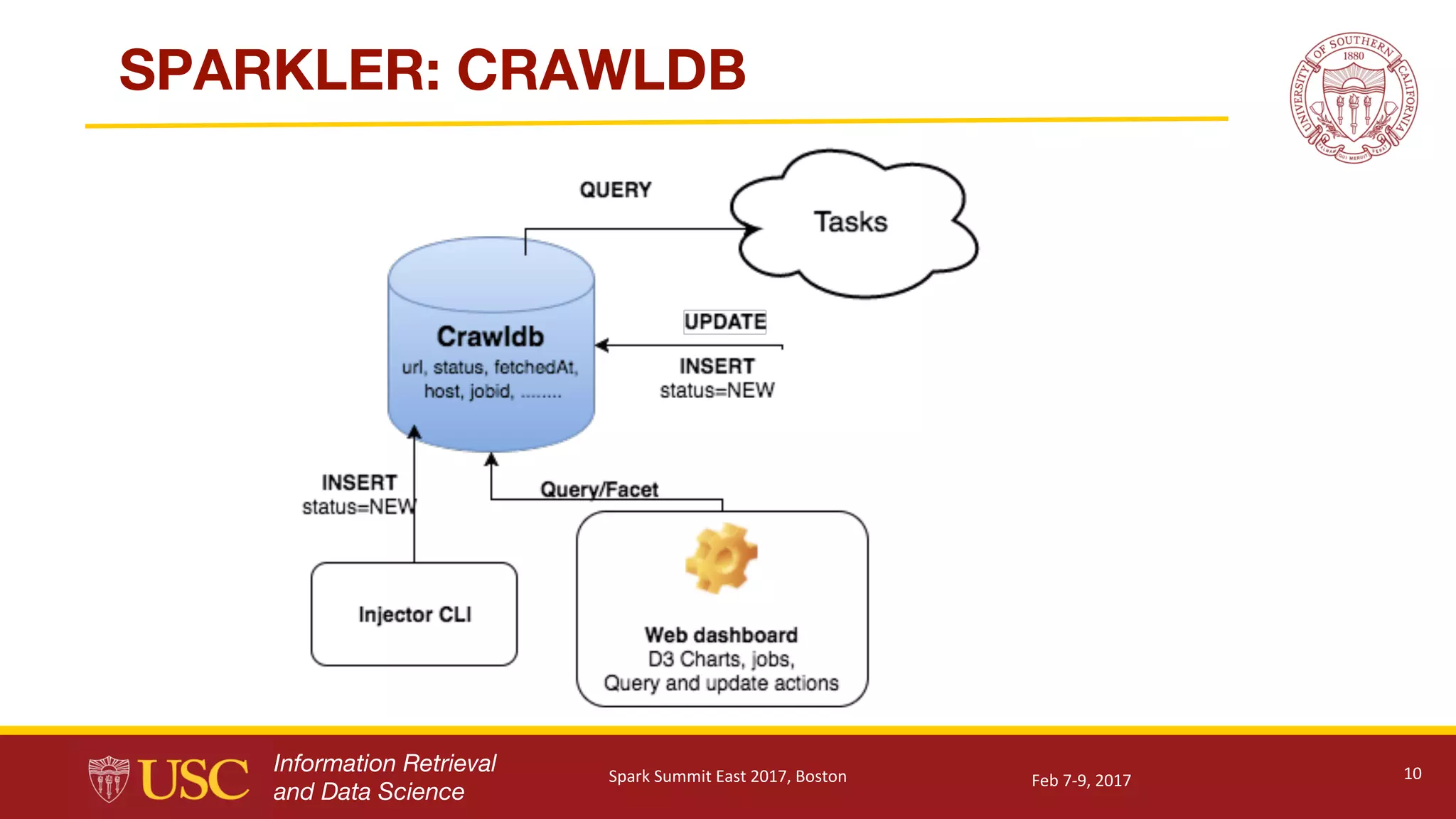
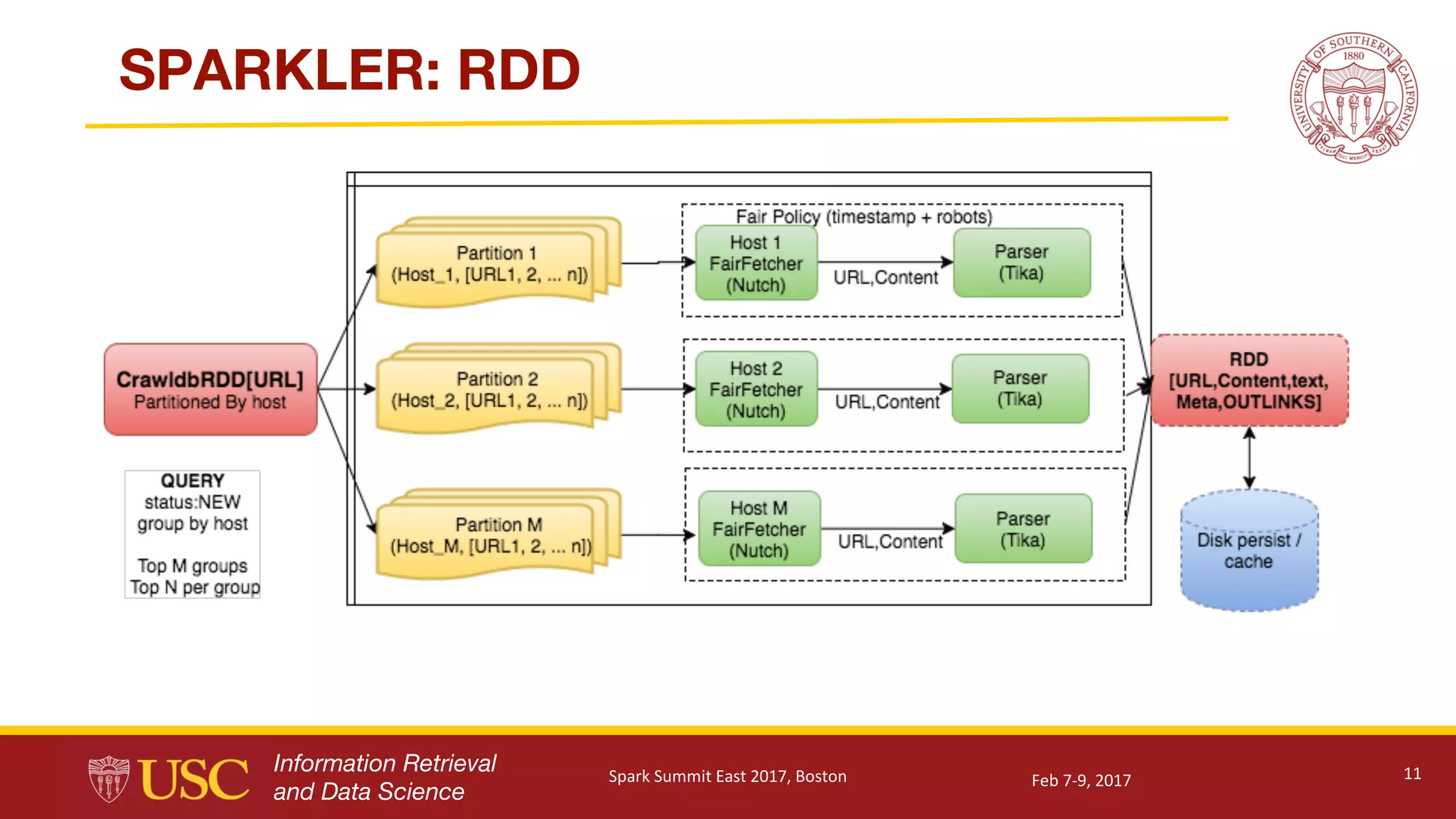
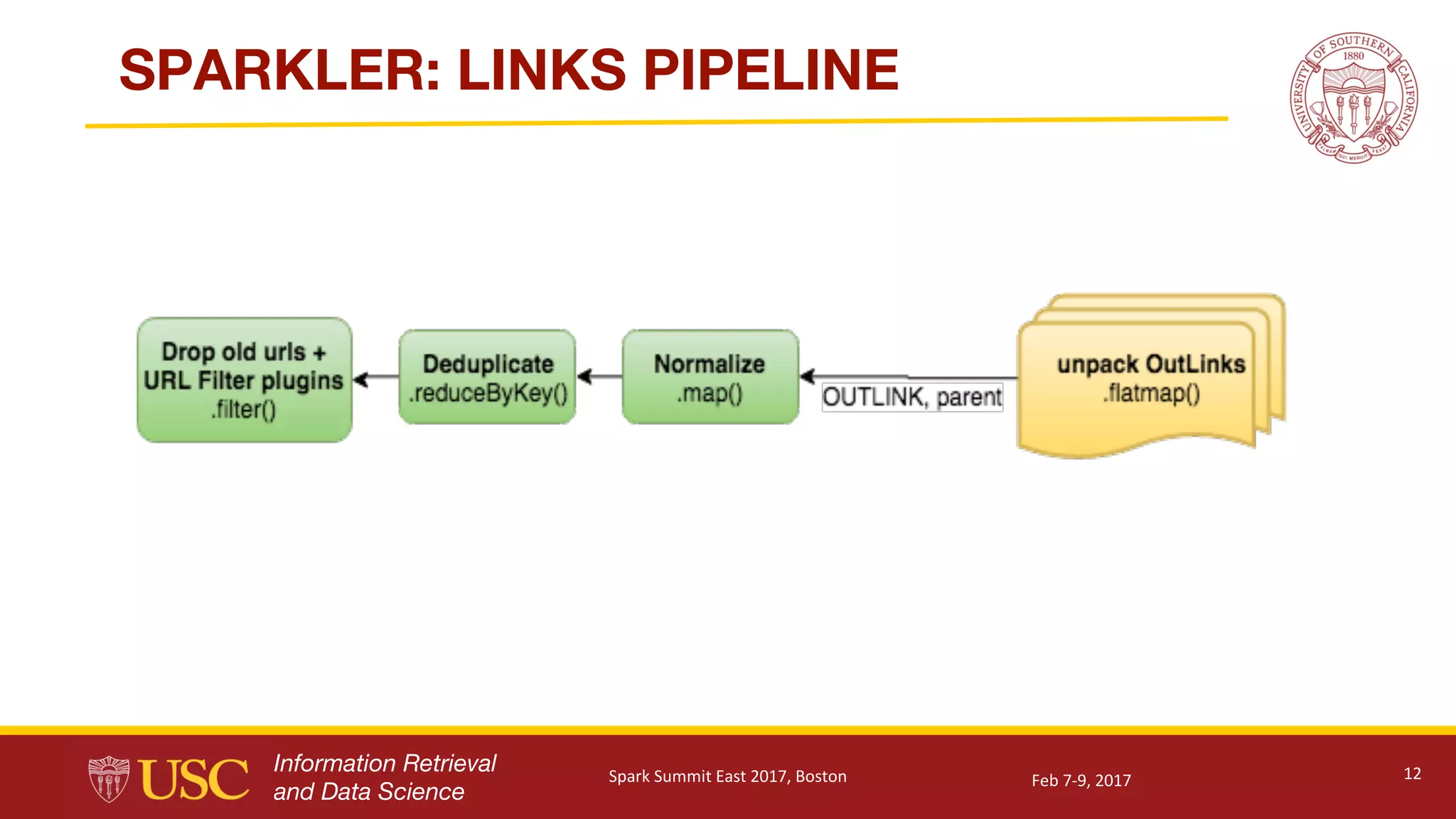
Details of Sparkler's technical architecture including database management, crawling methods, and data processing.
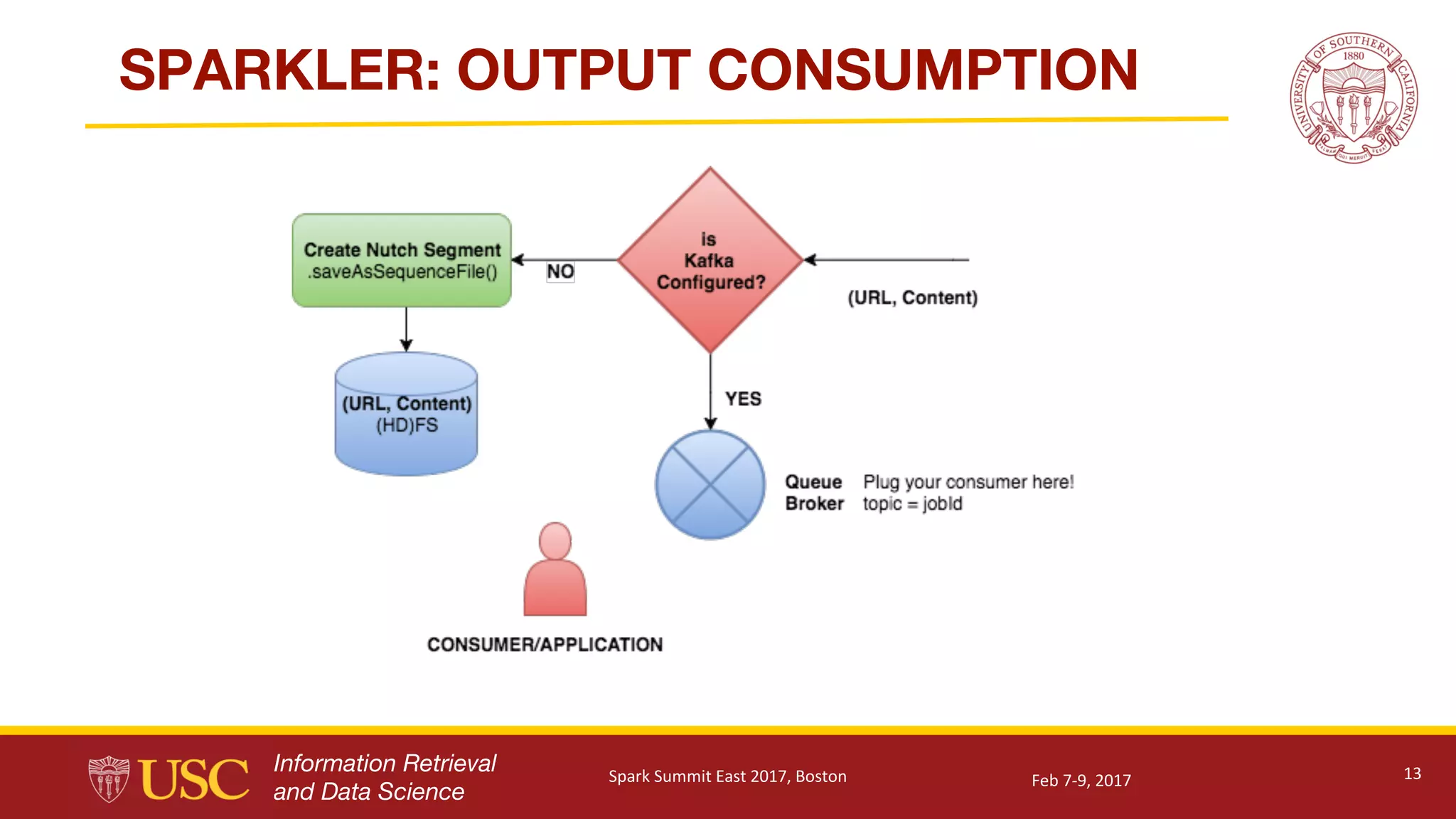
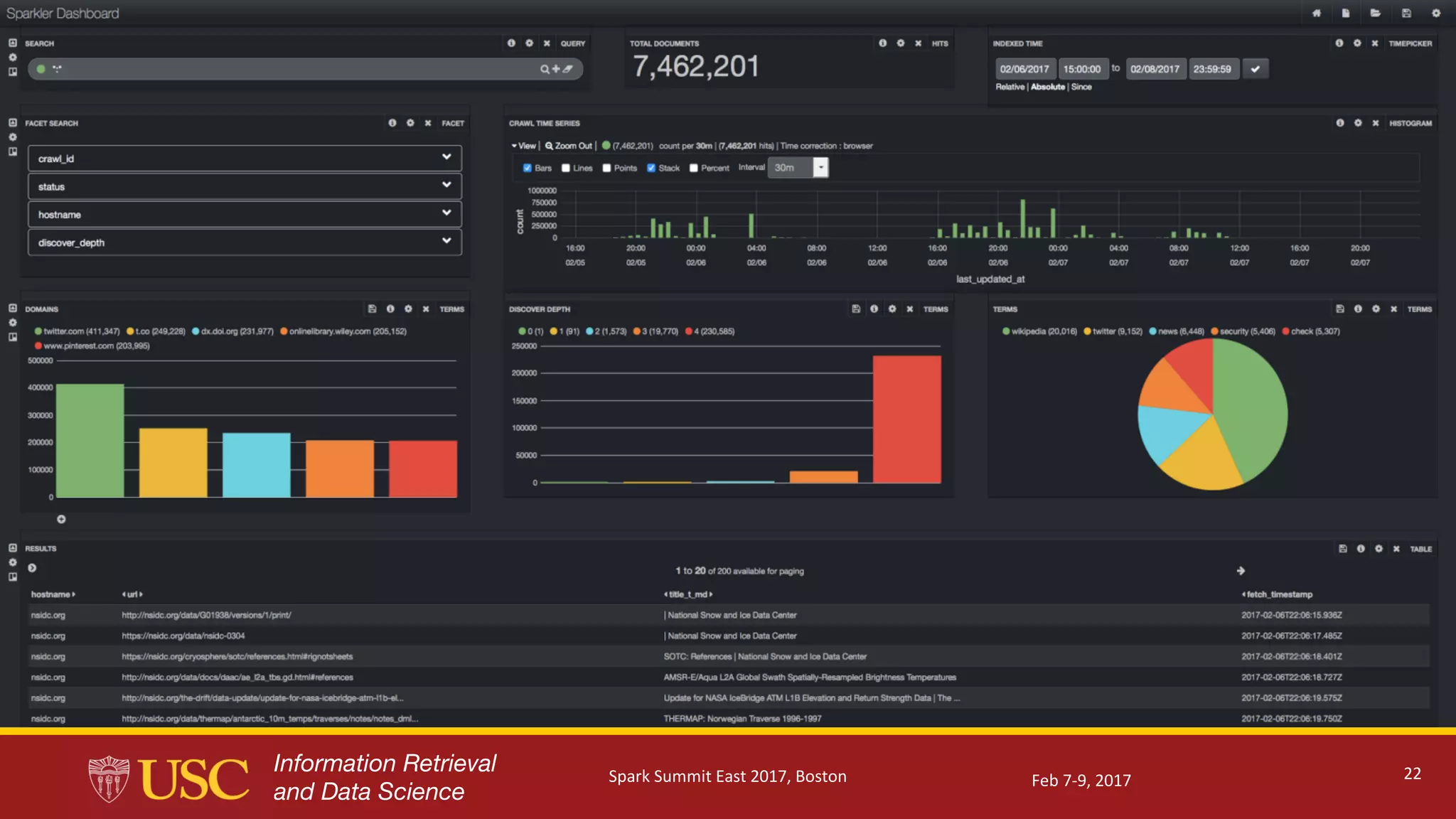
Description of output management, integration with Kafka, use of Apache Tika for parsing, and visual analytics capabilities.
Deployment options like Docker, future enhancements in crawling capabilities, and the roadmap ahead for Sparkler.
Demonstration of Sparkler's functionality and a session for questions from the audience.





































































![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)