Downloaded 13 times






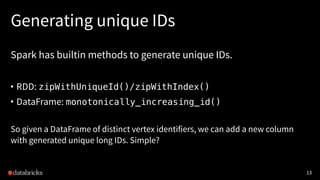
![Quick examples
Find 2nd-degree followers:
g.find(“(A)-[]->(B); (B)-[]->(C); !(A)-[]->(C)”)
.filter(“A.id != C.id”)
.select(“A”, “C”)
6](https://image.slidesharecdn.com/graphframes-cc-170608200435/85/Challenging-Web-Scale-Graph-Analytics-with-Apache-Spark-6-320.jpg)












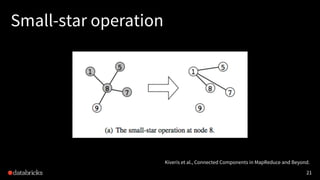
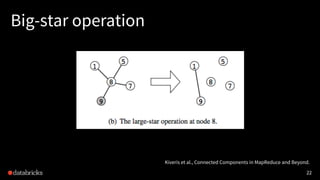
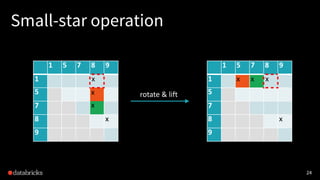
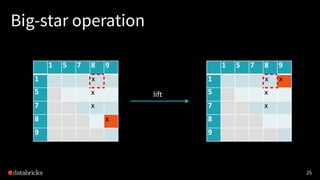
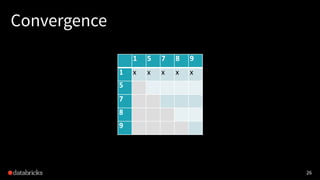
![Small-/large-star algorithm [Kiveris14]
Kiveris et al., Connected Components in MapReduce and Beyond.
1. Assign each vertex a unique ID.
2. Alternatively update edges in batches until convergence:
• (small-star) for each vertex, connect its smaller neighbors to the
smallest neighbor vertex
• (big-star) for each vertex, connect its bigger neighbors to the
smallest neighbor vertex (or itself)
20](https://image.slidesharecdn.com/graphframes-cc-170608200435/85/Challenging-Web-Scale-Graph-Analytics-with-Apache-Spark-20-320.jpg)



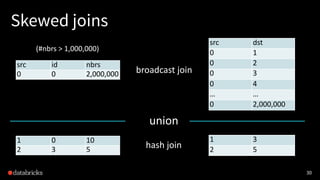








The document discusses graph analytics using Apache Spark's GraphFrames, a package that allows for optimized graph processing with DataFrames and supports various graph algorithms. It highlights lessons learned from implementing algorithms like connected components, addressing challenges such as data skew in graph iterations, and the advantages of using integral vertex IDs. The document also compares performance experiments between GraphFrames and GraphX, showing GraphFrames' efficiency for large datasets.























































































