Download as PDF, PPTX







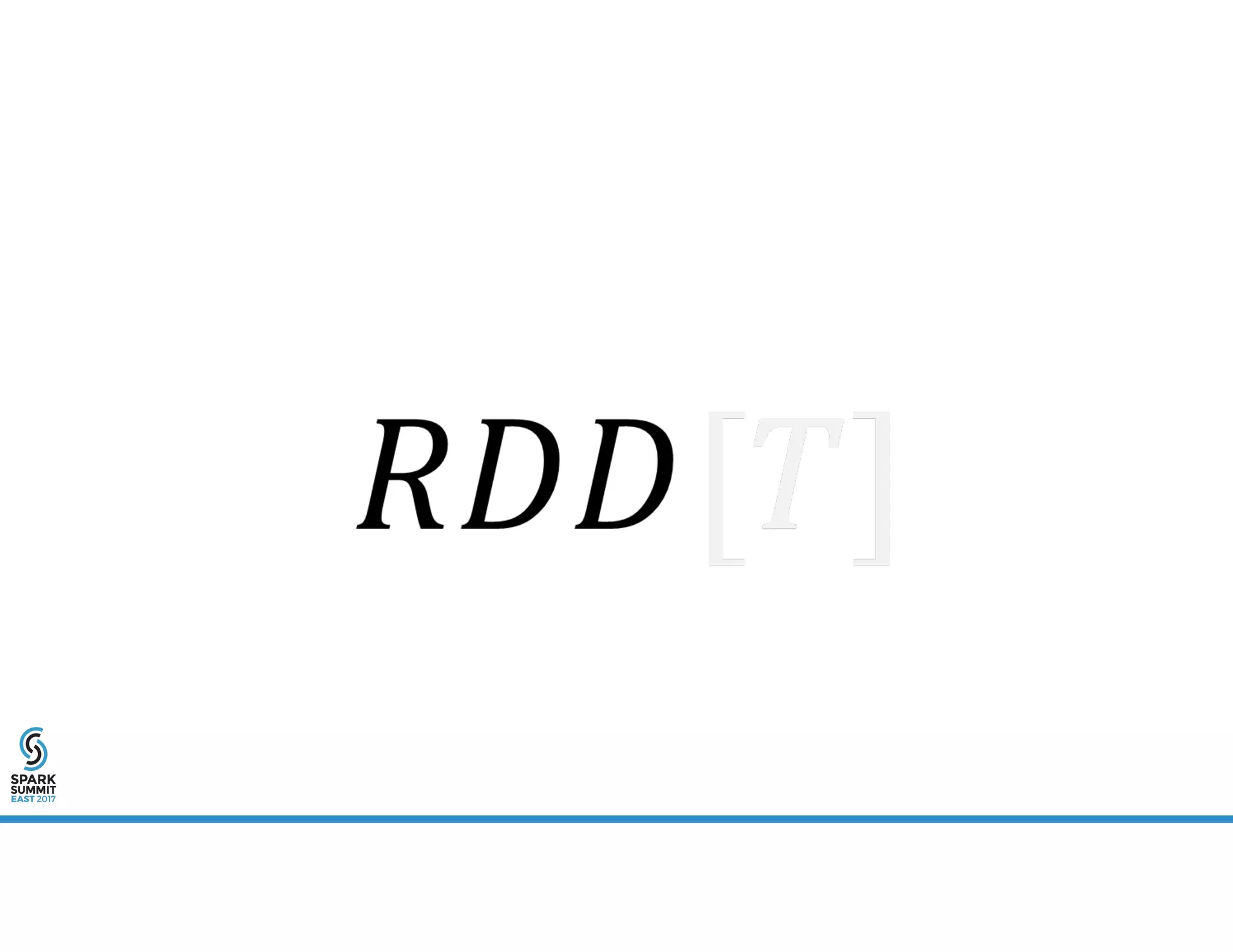




















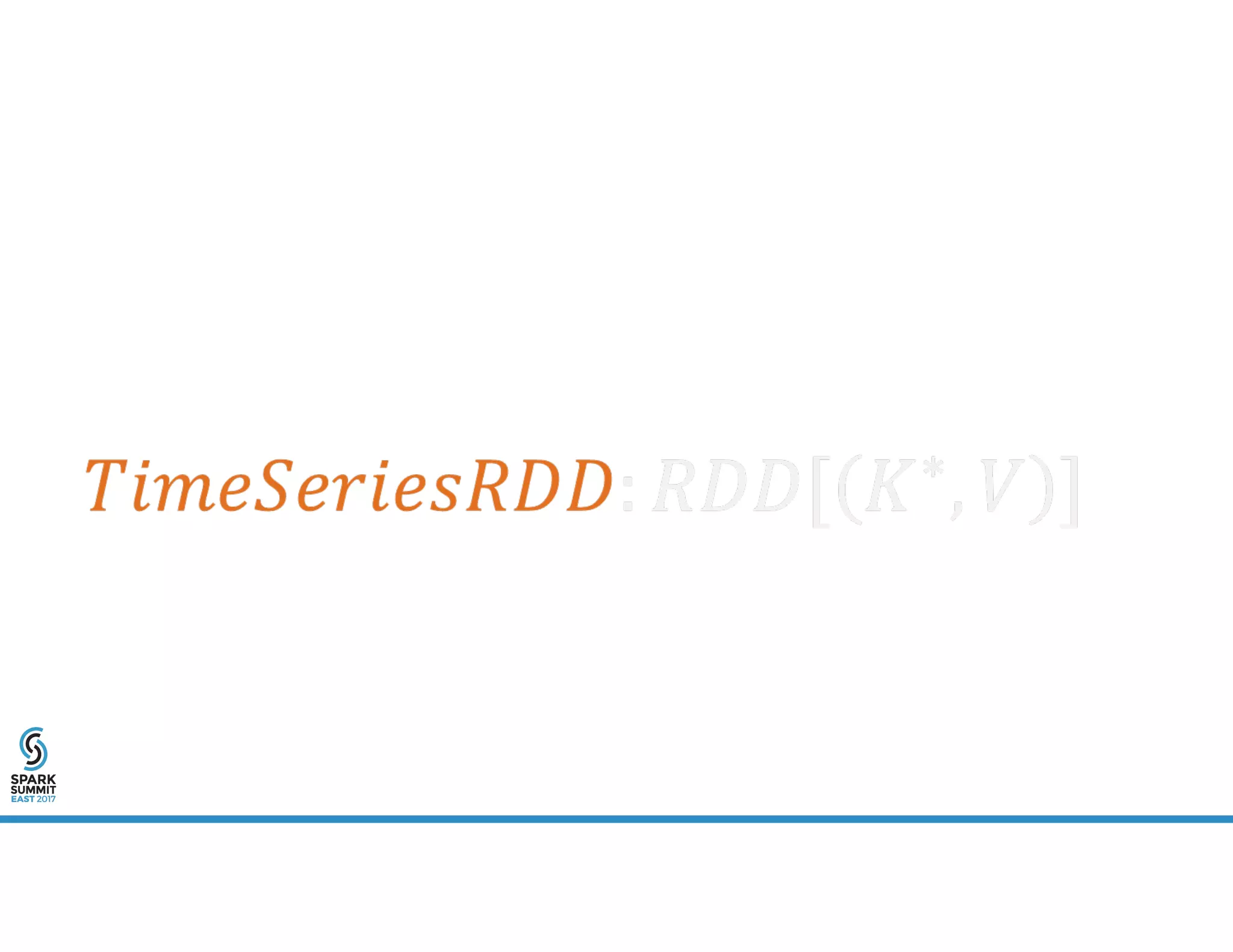



![w is a window specification e.g. 500ms, 5s, 3 business days
RDD[(K,V)] -> RDD[(K,Seq[V])]](https://image.slidesharecdn.com/1adavidpalaitis-170214185024/75/New-Directions-in-pySpark-for-Time-Series-Analysis-Spark-Summit-East-talk-by-David-Palaitis-40-2048.jpg)
![reduceByWindow(f: (V, V) => V, w): RDD[(K, W)] => RDD[(K, V)]](https://image.slidesharecdn.com/1adavidpalaitis-170214185024/75/New-Directions-in-pySpark-for-Time-Series-Analysis-Spark-Summit-East-talk-by-David-Palaitis-41-2048.jpg)
![reduceByWindow(f: (V, V) => V, w): RDD[(K, V)] => RDD[(K, V)]](https://image.slidesharecdn.com/1adavidpalaitis-170214185024/75/New-Directions-in-pySpark-for-Time-Series-Analysis-Spark-Summit-East-talk-by-David-Palaitis-42-2048.jpg)


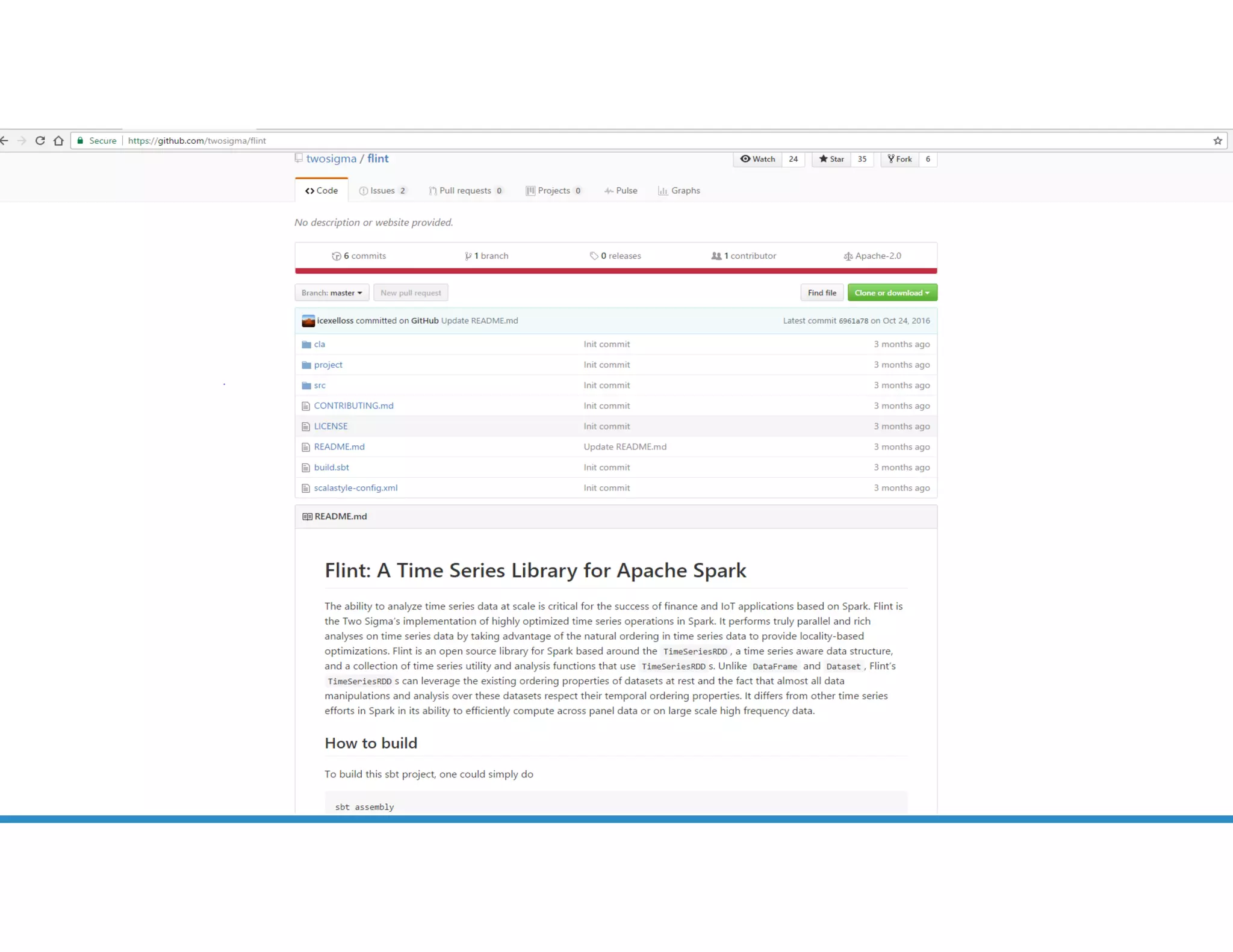
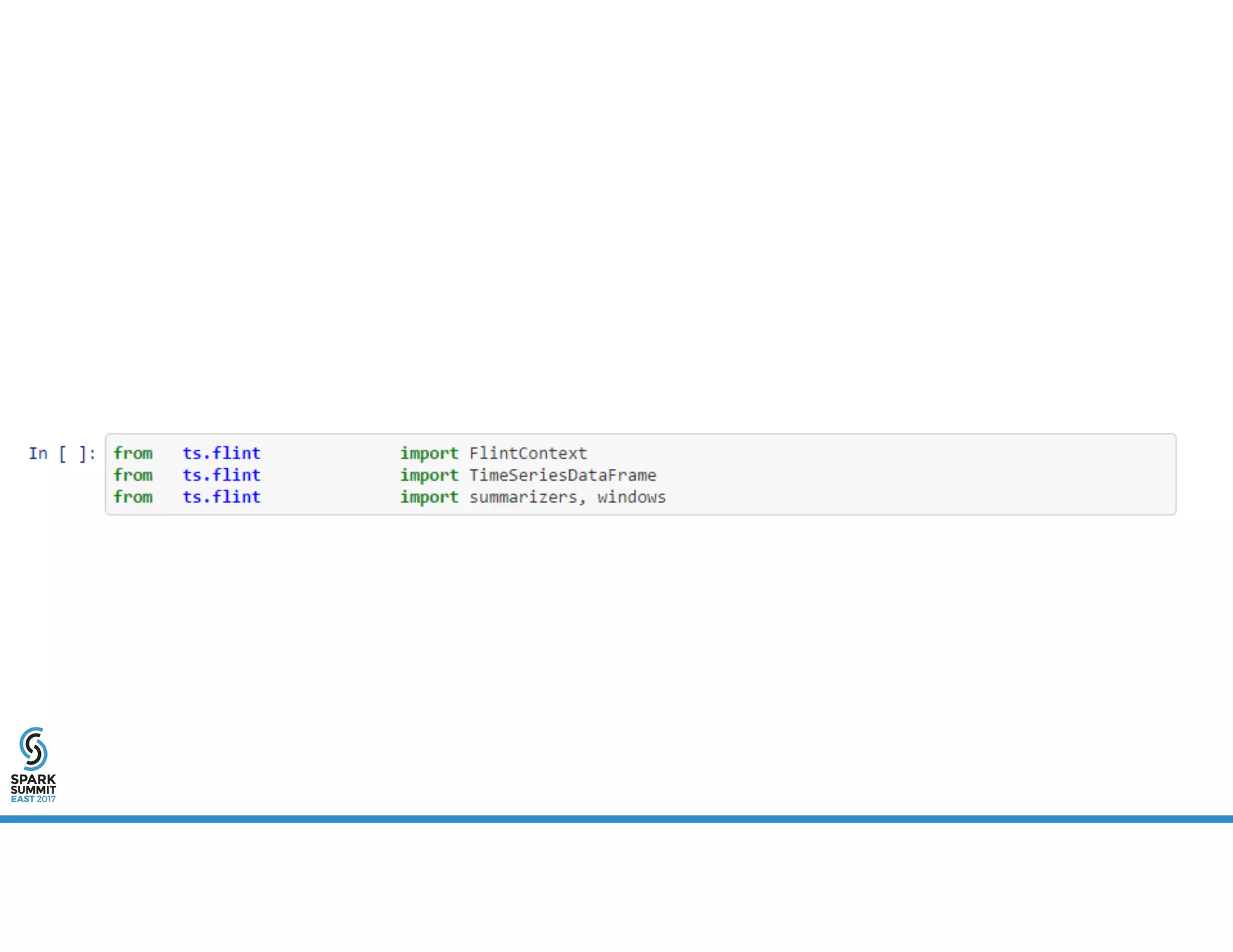
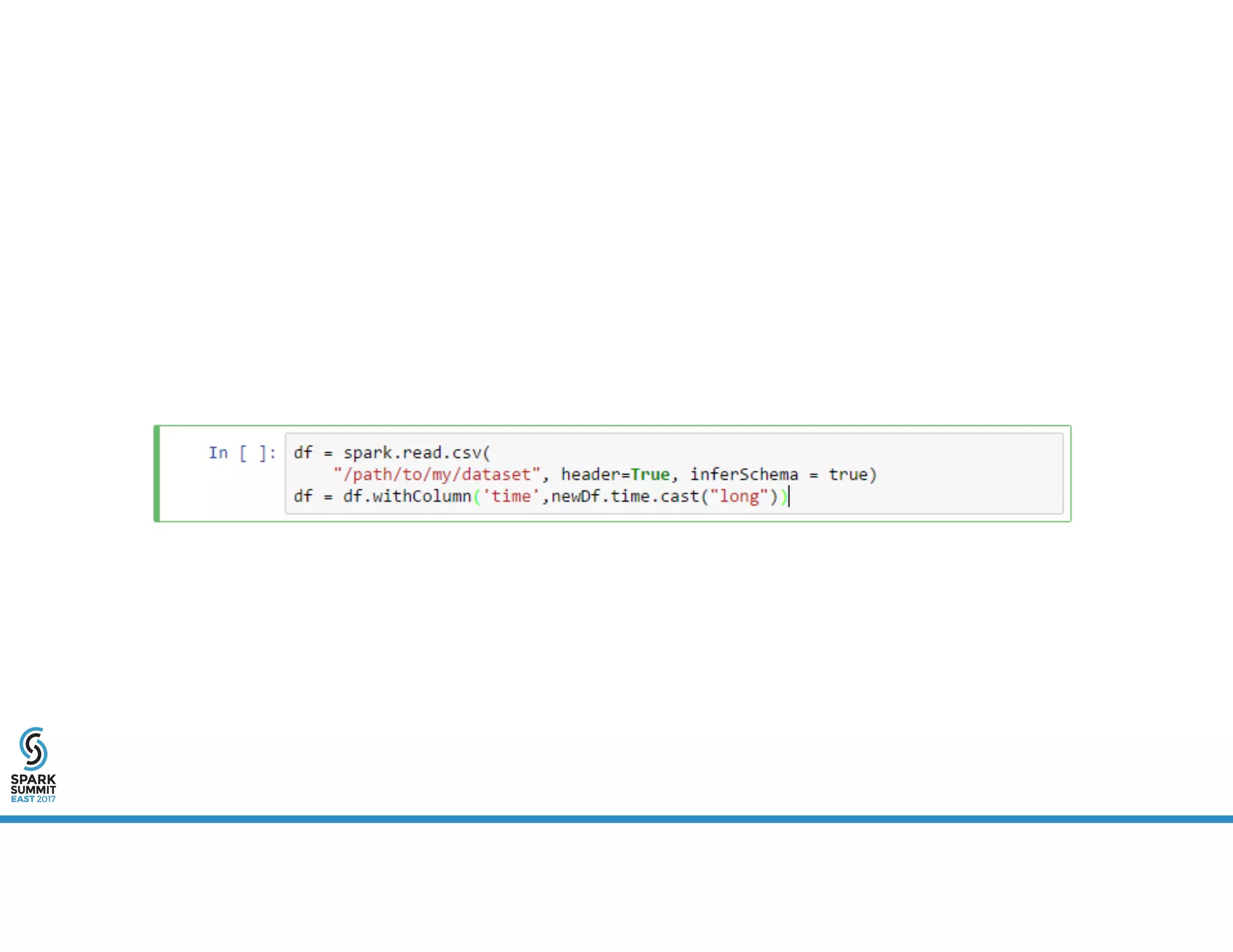
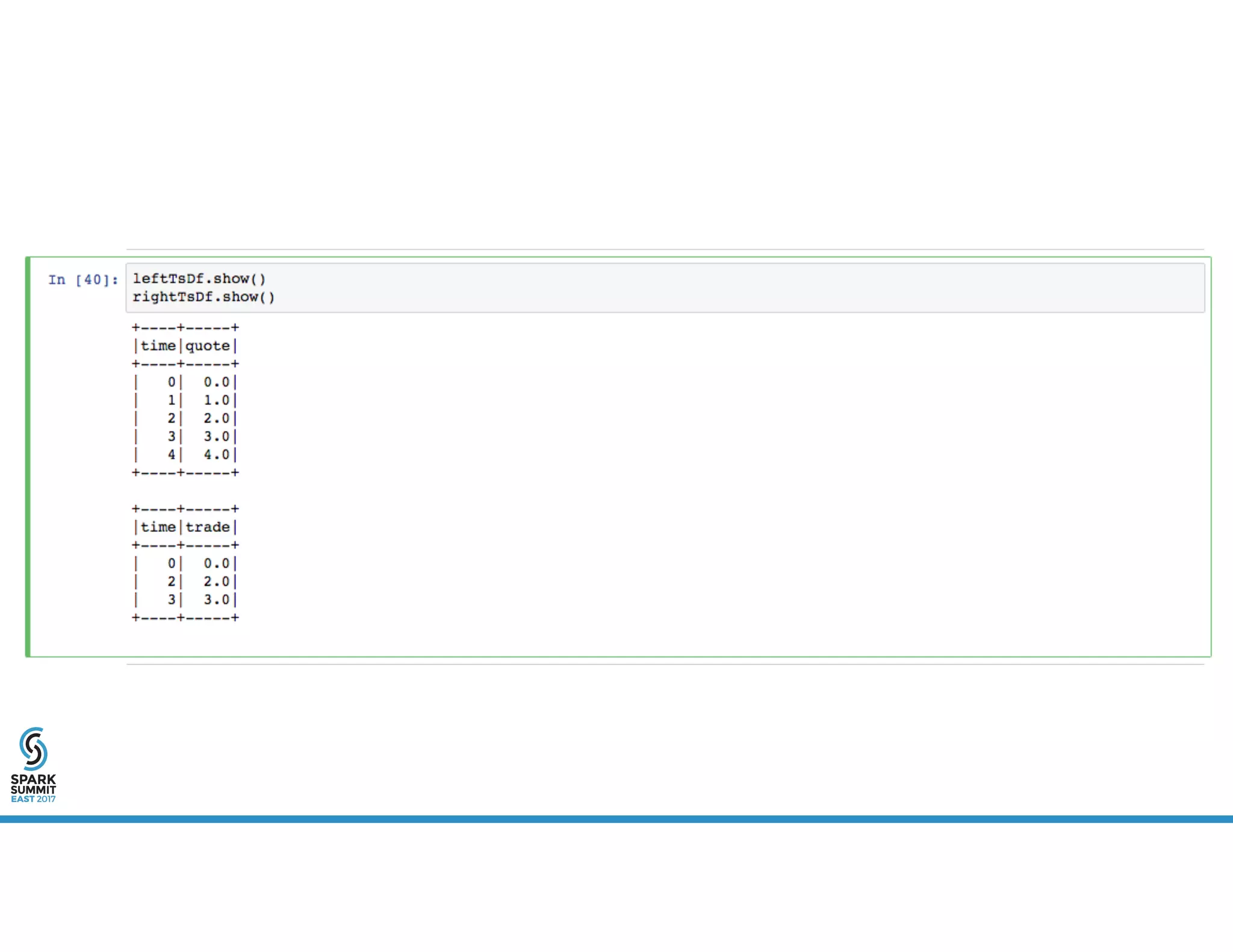
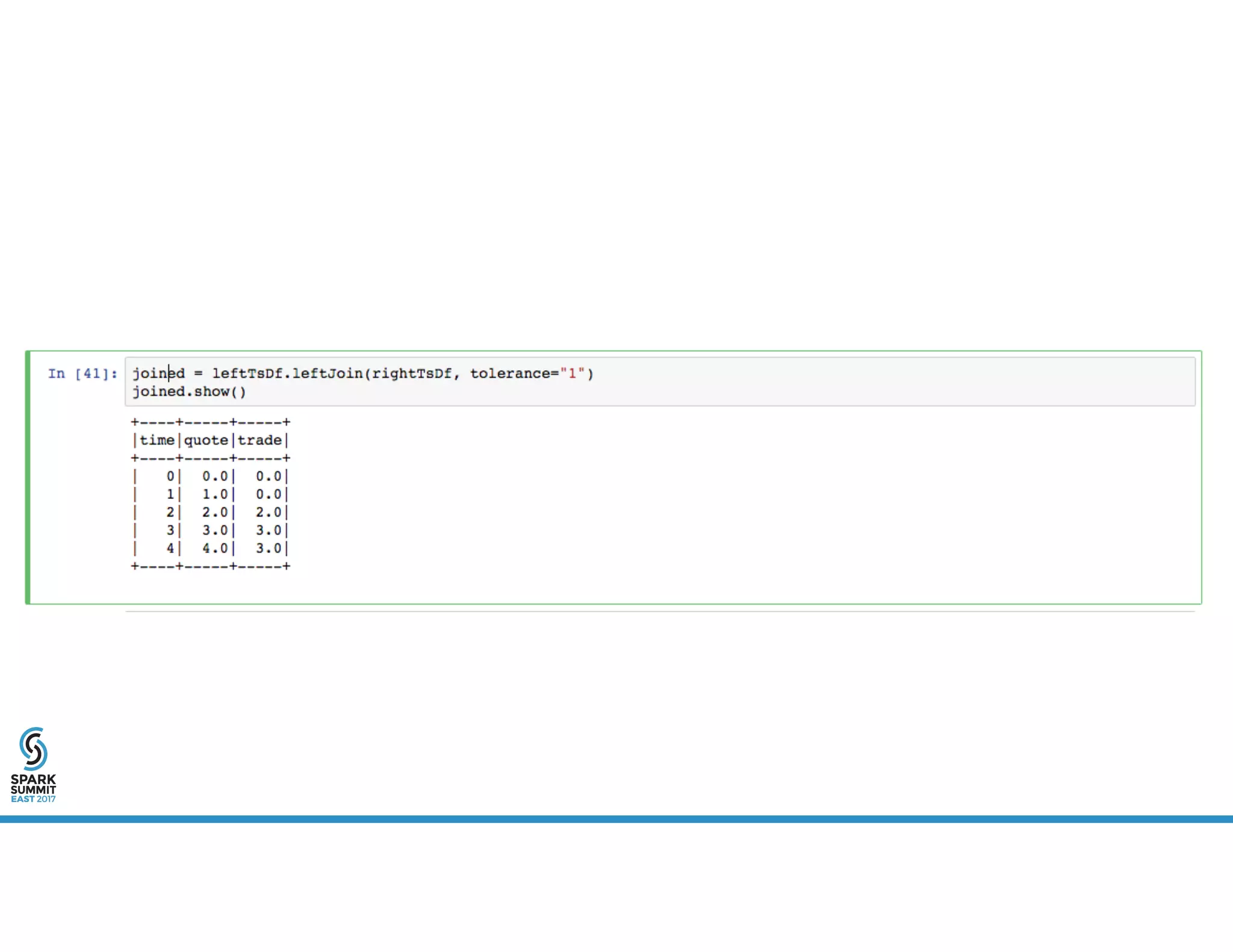
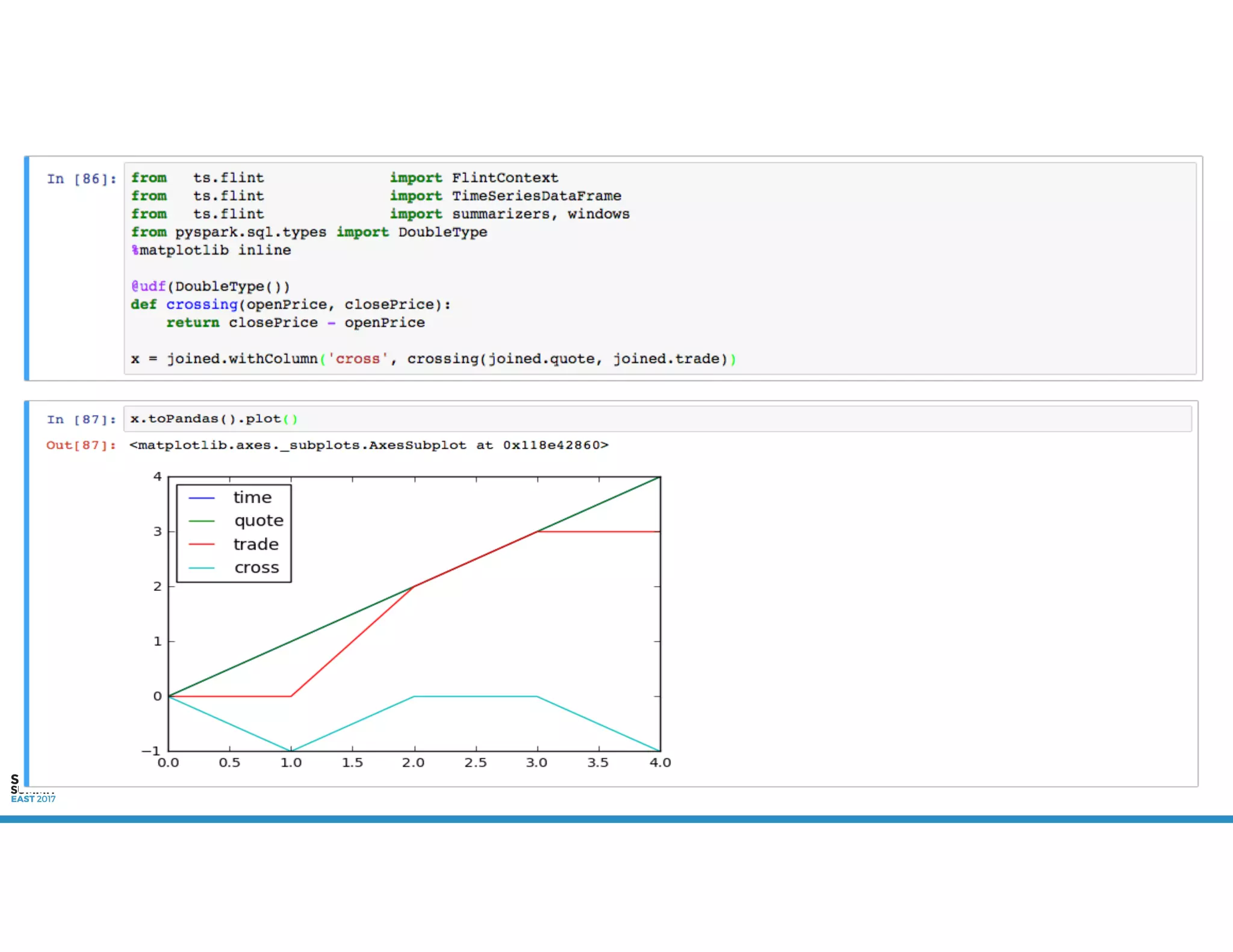
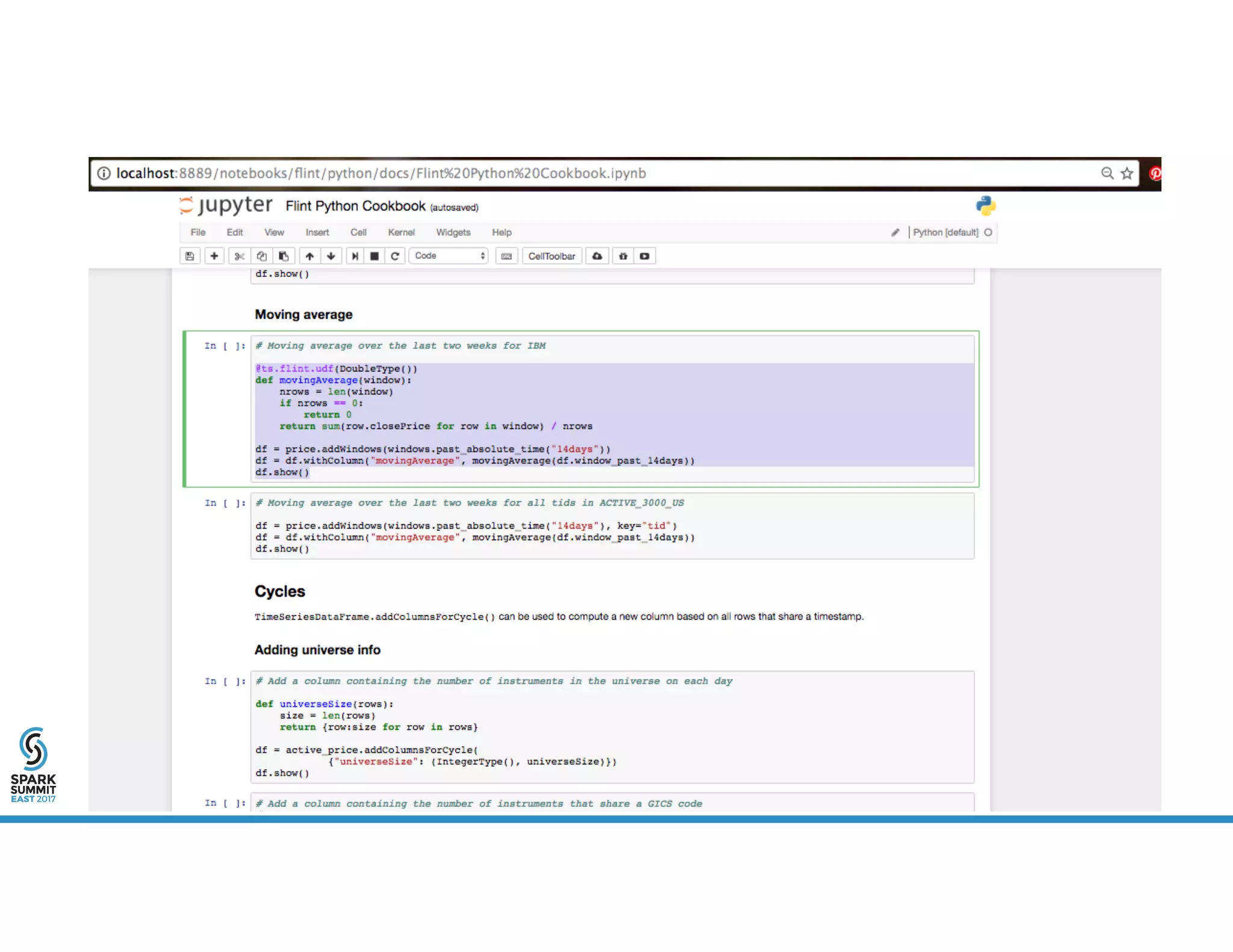


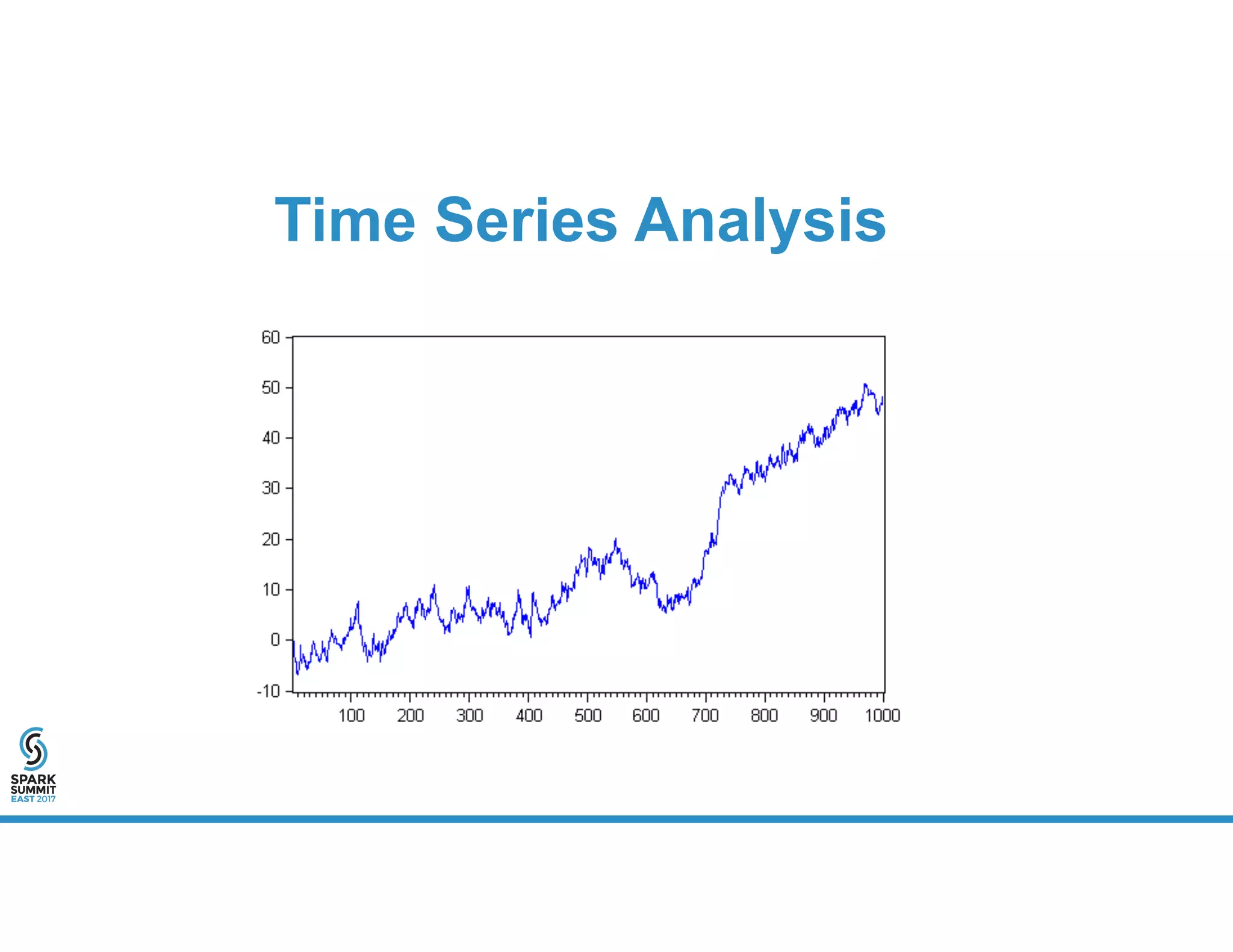
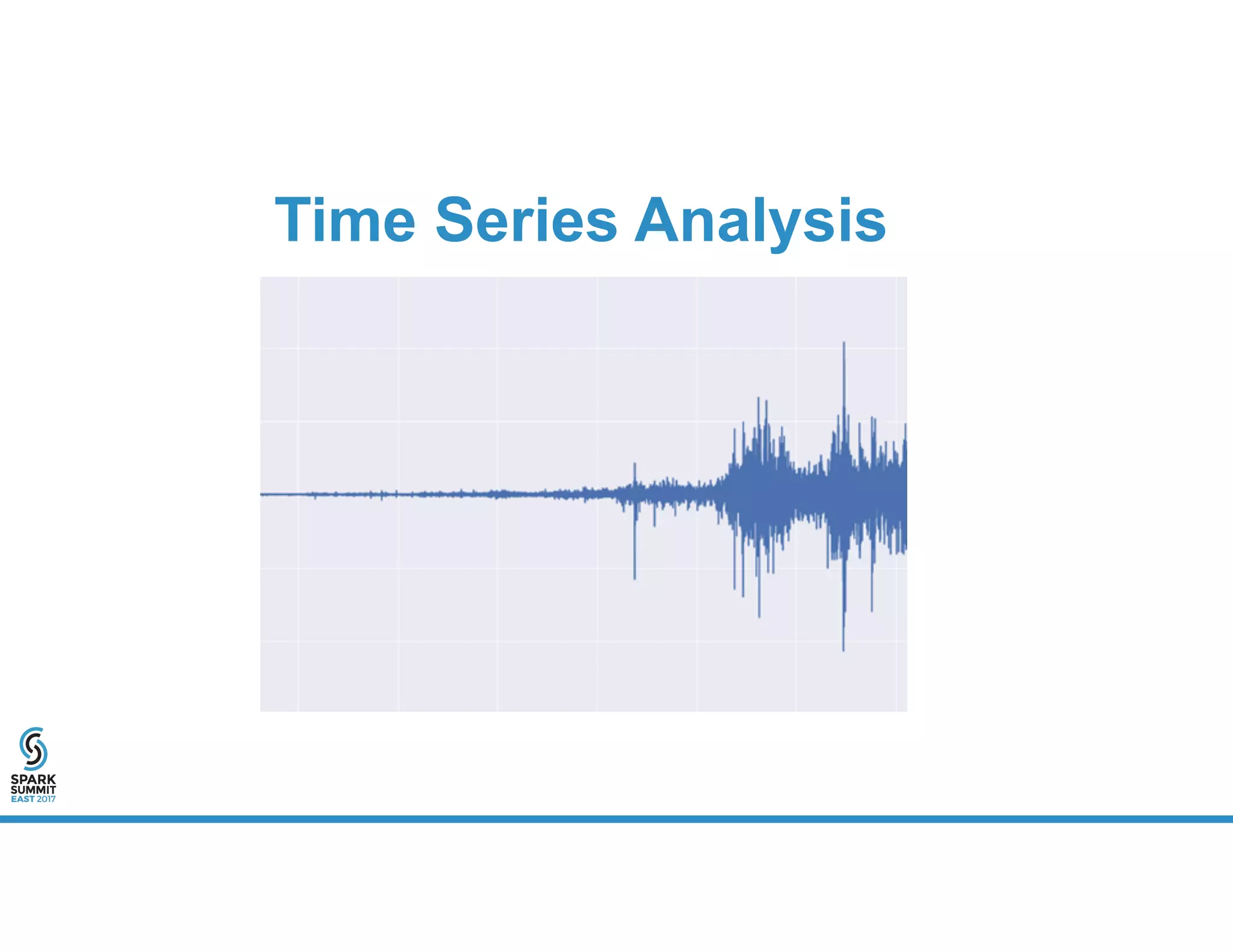
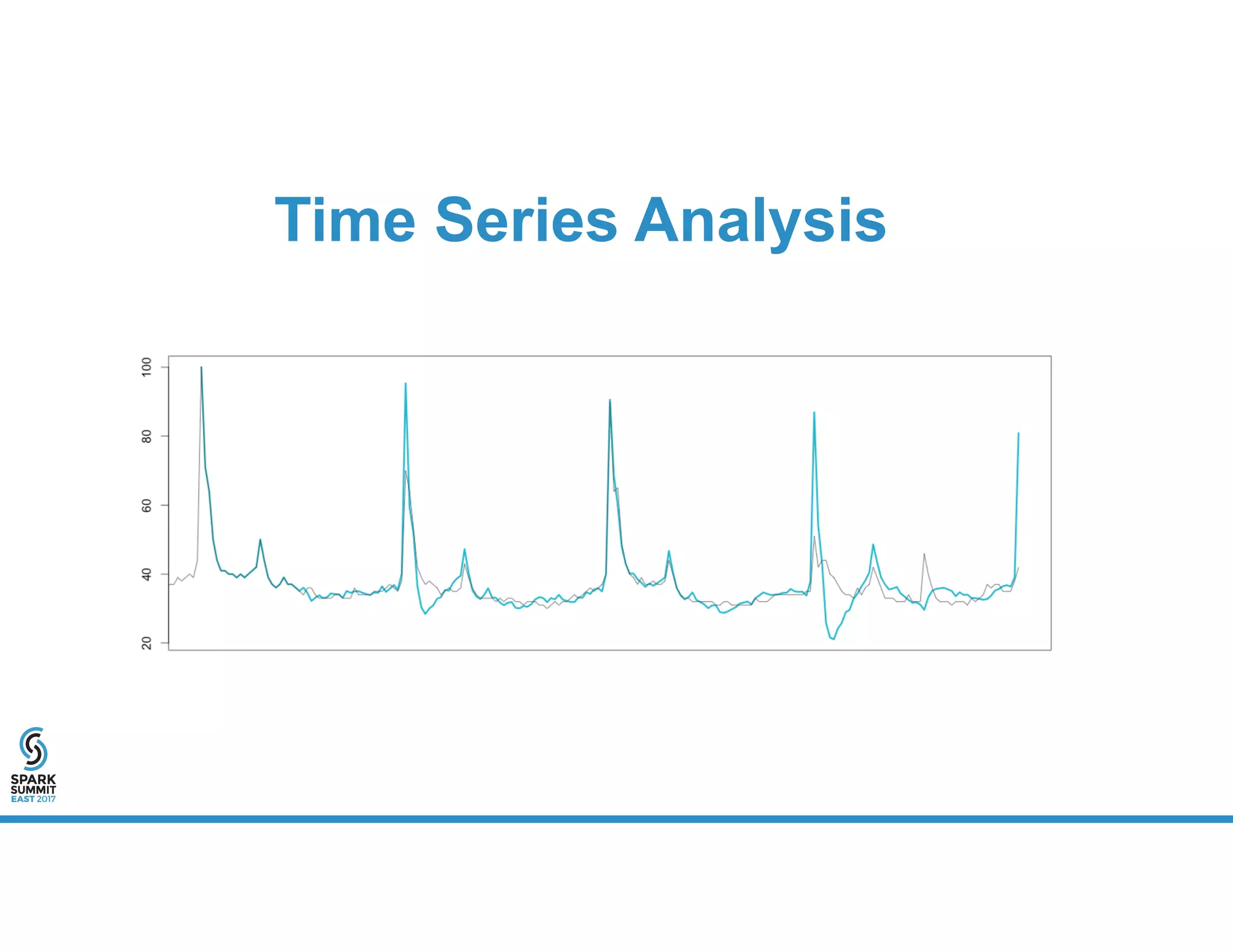
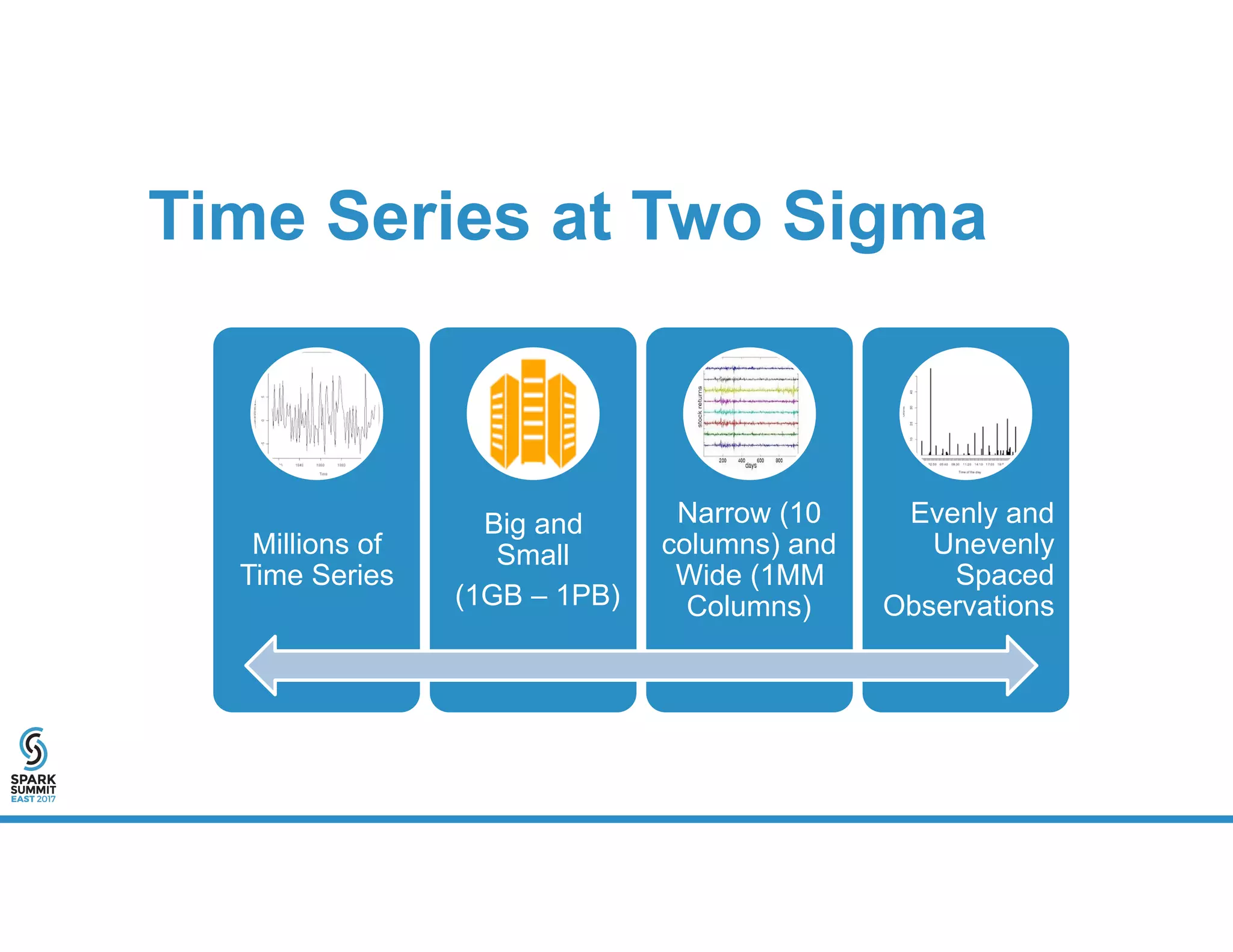
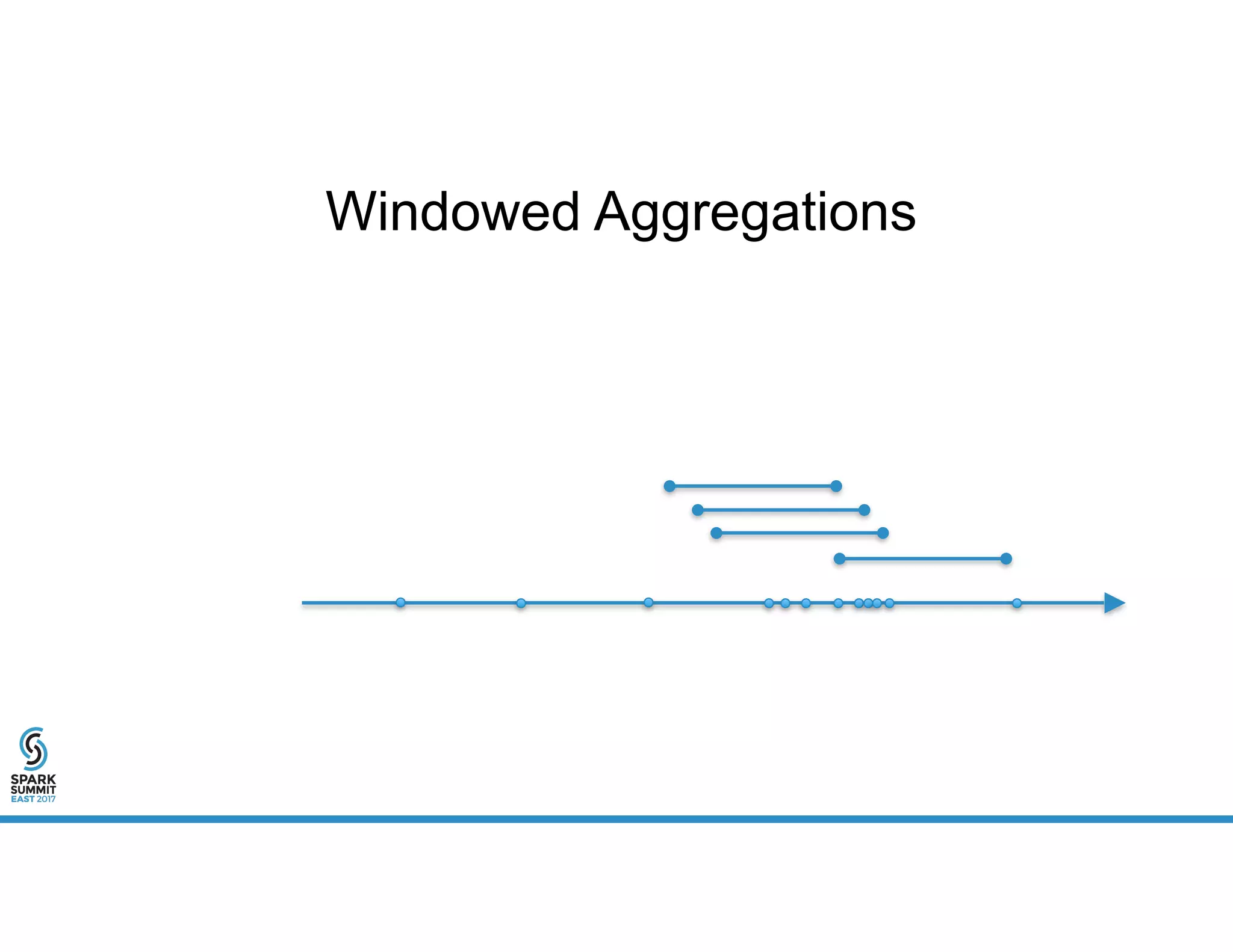
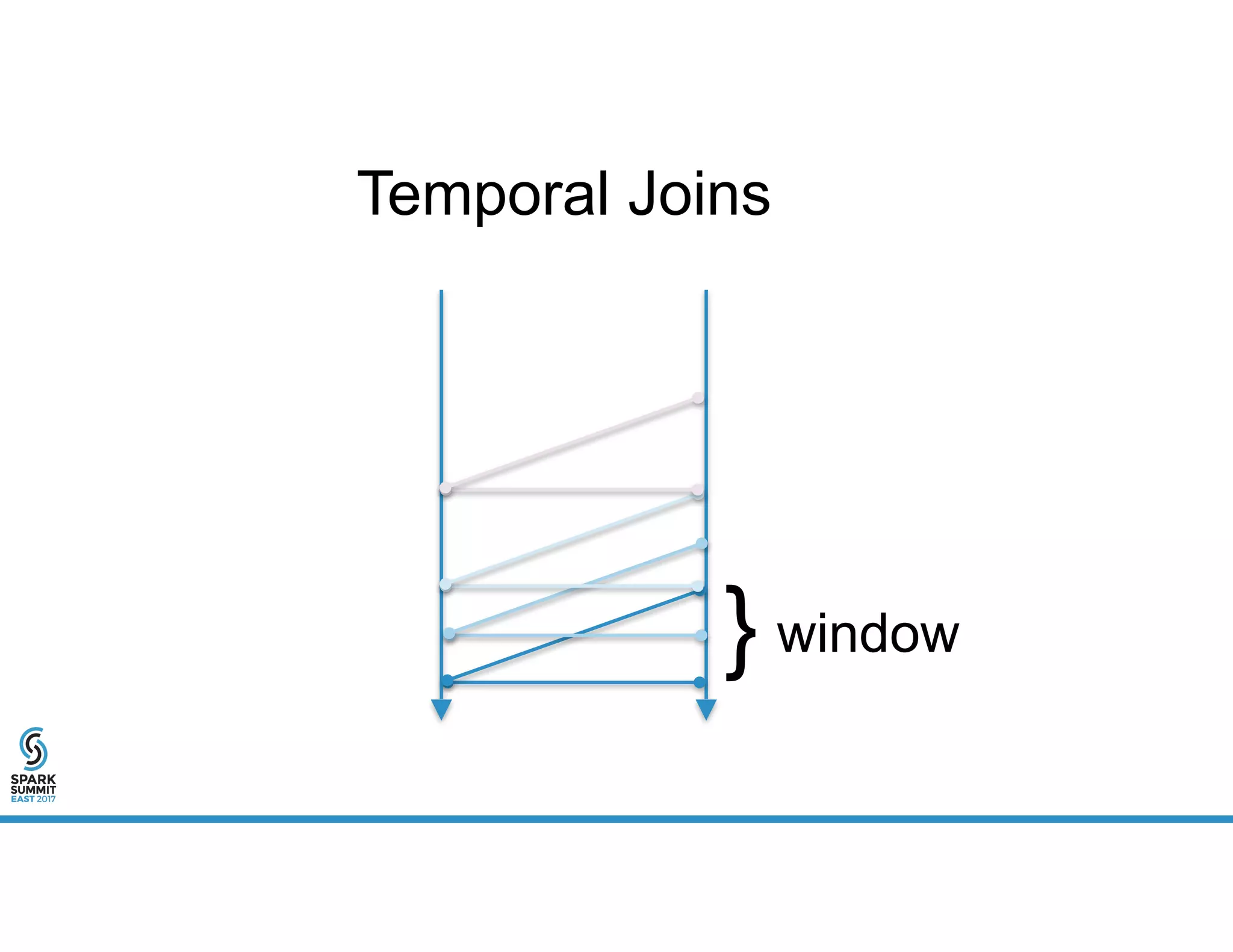
The document provides an overview of using PySpark for time series analysis. It discusses that time series data can come from sources like IOT feeds, sensor data, and economic indicators. Time series analysis in PySpark allows for windowed aggregations and temporal joins on massive time series datasets that can be both wide and narrow. While basic analytics are possible in PySpark, libraries like Flint provide additional functions specialized for time series analysis on large datasets in a distributed environment. The document encourages attendees to speak with the author after the talk to see a time series analysis library in PySpark demonstrated.



































































![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)