Download as PDF, PPTX







![Streaming graph analysis
Terminology (not universal):
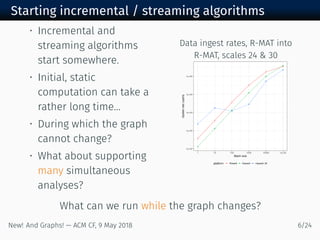
• Streaming changes into a massive, evolving graph
• Need to handle deletions as well as insertions
Previous STINGER performance results (x - ):
Data ingest > M upd/sec [Ediger, McColl, Poovey, Campbell, &
Bader ]
Clustering coefficients > K upd/sec [R, Meyerhenke, B, E,
& Mattson ]
Connected comp. > M upd/sec [McColl, Green, & B ]
Community clustering > K upd/sec∗
[R & B ]
PageRank Up to × latency improvement [R ]
New! And Graphs! — ACM CF, May /](https://image.slidesharecdn.com/computing-frontiers-ejr-out-180509140537/85/Graph-Analysis-New-Algorithm-Models-New-Architectures-7-320.jpg)

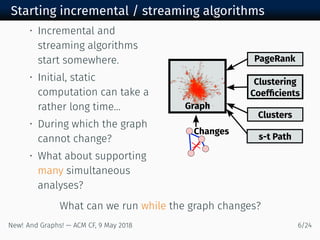

![Sample of other execution models
• Put in a query, wait for sufficient data [Phillips, et al.
at Sandia]
• Different but very interesting model.
• Evolving: Sample, accurate w/high-prob.
• Difficult to generalize into graph results (e.g.
shortest path tree).
• Classical: dynamic algorithms, versioned data
• Can require drastically more storage, possibly a copy
of the graph per property, or more overhead for
techniques like read-copy-update.
Generally do not address the latency of computing the
“static” starting point.
New! And Graphs! — ACM CF, May /](https://image.slidesharecdn.com/computing-frontiers-ejr-out-180509140537/85/Graph-Analysis-New-Algorithm-Models-New-Architectures-12-320.jpg)








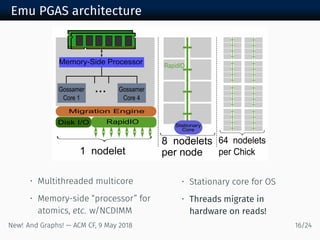

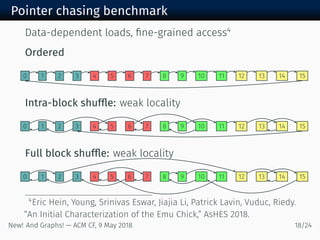
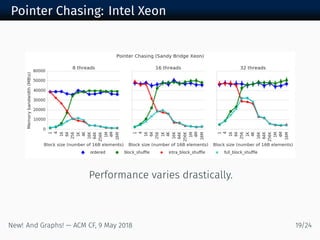
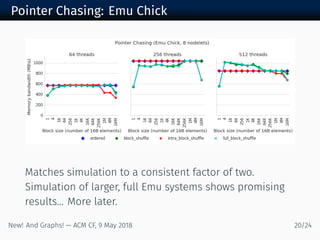
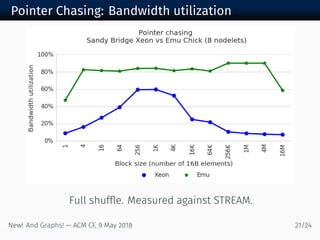
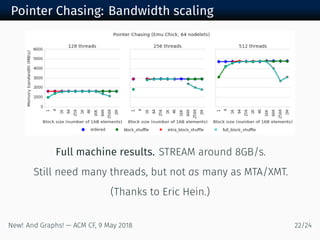
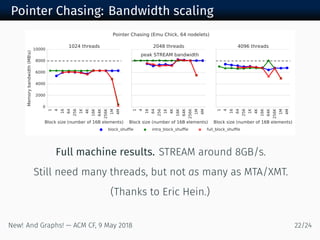




The document discusses new algorithms and architectures for graph analysis on streaming data. It introduces a new algorithm model that allows analysis to run concurrently with graph changes without locking the graph. Some algorithms like degree computation are valid under this model while others like shortest paths may not be. A new architecture called Emu uses lightweight threads that migrate to data, showing better performance on pointer-chasing benchmarks than CPUs by better utilizing memory bandwidth. Overall the document explores new approaches for analyzing massive streaming graphs in real-time.


















































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)








