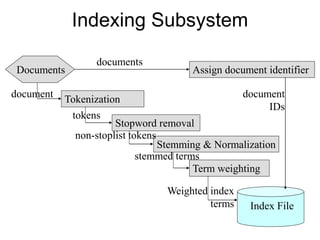
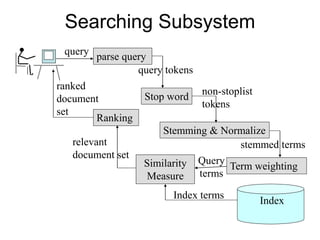
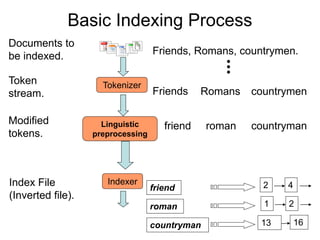
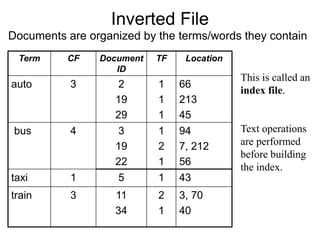
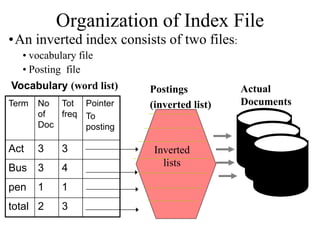
The document describes the process of building an inverted index for information retrieval. Key points:
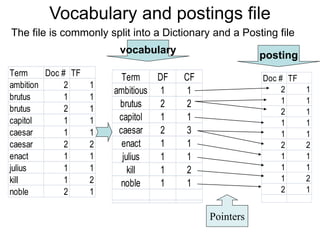
- Documents are parsed to extract terms which are sorted in a vocabulary file along with document frequency and collection frequency.
- A postings file stores the document IDs and term frequencies for each unique term. This separates the small vocabulary file for fast searching from the large postings file.
- The process involves tokenizing documents, removing stopwords, stemming terms, and counting term frequencies to build the inverted index files for efficient searching of documents based on terms.





























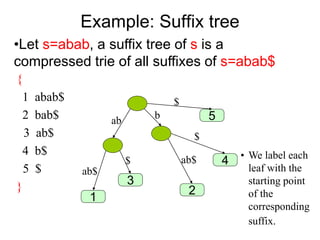
![Complexity Analysis
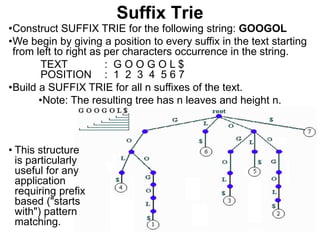
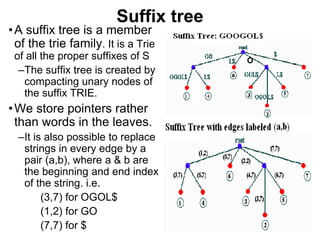
• The suffix tree for a string has been built in
O(n2) time.
• The search time is proportional to the length
of string S; i.e. O(|S|).
• Searching for a substring[1..m], in string[1..n],
can be solved in O(m) time
– It requires to search for the length of the string
O(|S|).
• Updating the index file can be done
incrementally without affecting the existing
index](https://image.slidesharecdn.com/3indexing-231029172717-3872b1a3/85/3_Indexing-ppt-39-320.jpg)
















































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)
