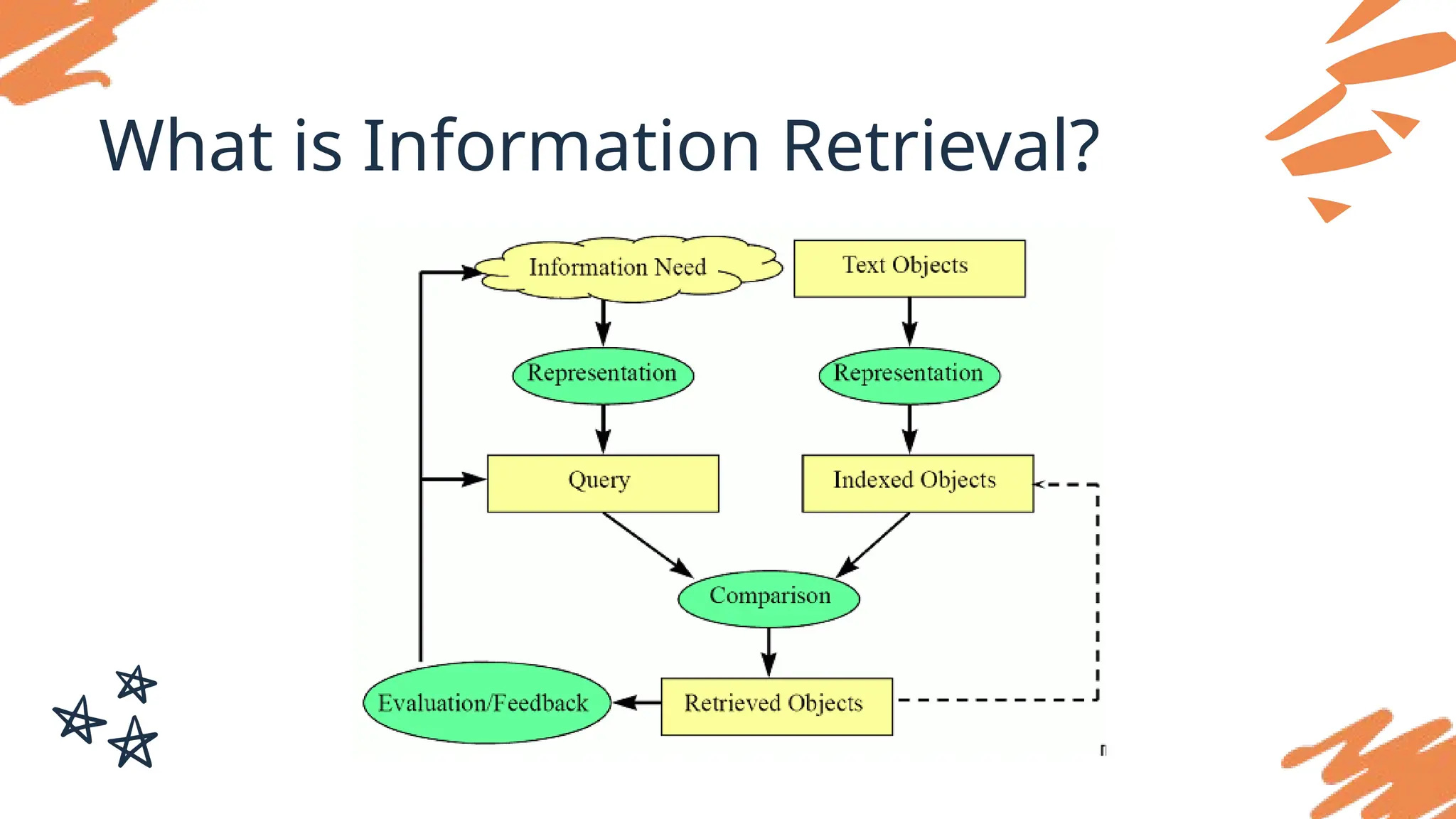
What is InformationRetrieval?
Information retrieval (IR) is finding material (usually documents) of an
unstructured nature (usually text) that satisfies an information need from
within large collections (usually stored on computers).
Our goal is to develop a system to address the ad hoc retrieval task, which is
the most standard IR task. In it, a system aims to provide documents from
within the collection that are relevant to an arbitrary user information need,
communicated to the system by means of a one-off, user-initiated query.
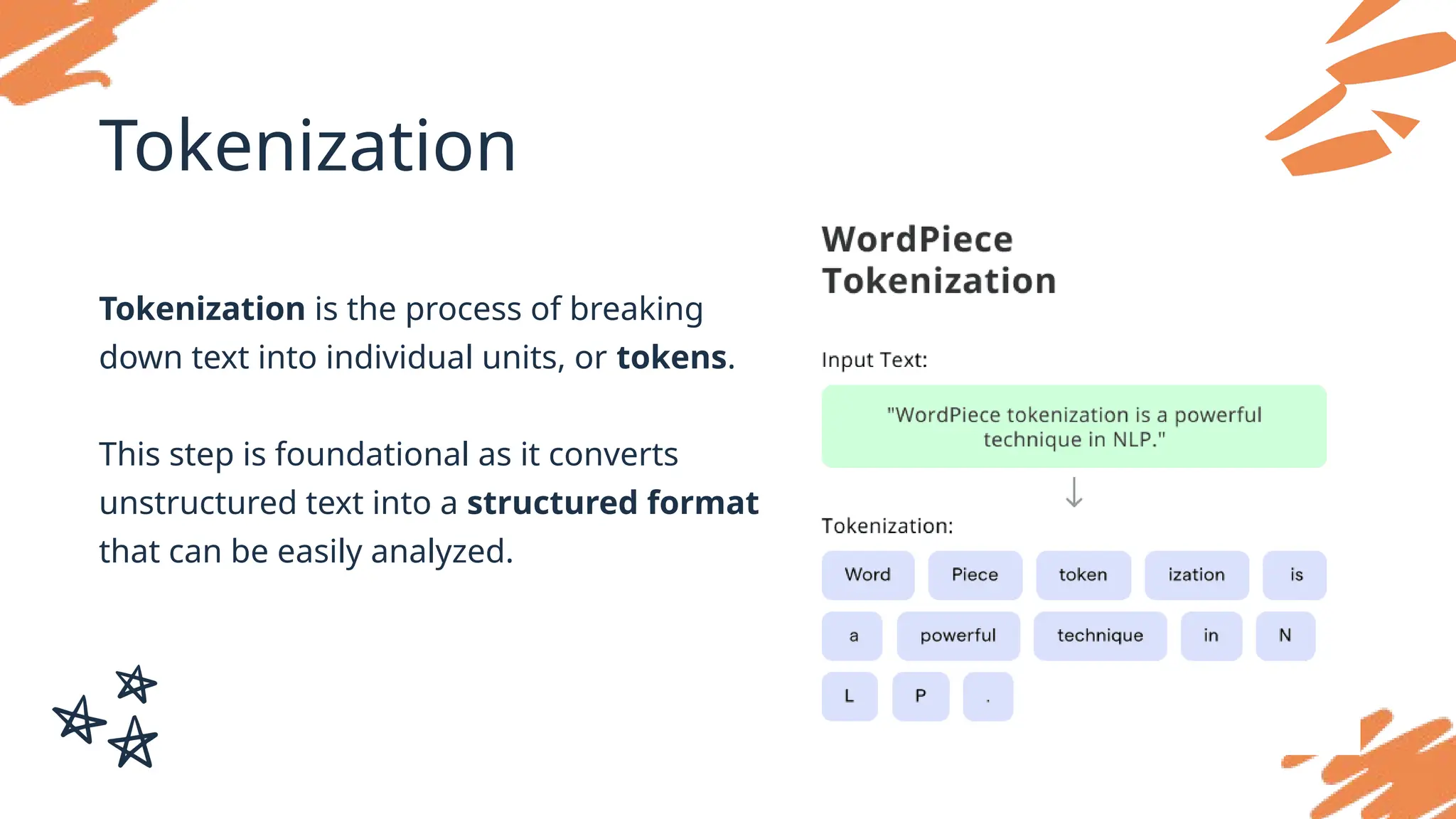
Tokenization
Tokenization is theprocess of breaking
down text into individual units, or tokens.
This step is foundational as it converts
unstructured text into a structured format
that can be easily analyzed.
11.
Removing Stopwords
Stopwords arecommon, low-information
words, which frequently appear in text but
often do not carry significant meaning.
Removing stopwords reduces the amount
of data for processing, focusing on more
meaningful terms.
12.
Normalization
Text normalization isthe process of converting text to a consistent format,
which helps to avoid variations that may lead to mismatches in analysis. This
includes:
• Lowercasing: “Text”, “TEXT”, “text” -> “text”
• Removing punctuation and special characters (.,;:)
• Replacing contractions: “can’t” -> “cannot”
• Standardizing accents: “café” -> “cafe”
13.
Stemming and Lemmatization
•Stemming is the process of
reducing words to their root or base
form, often by removing common
suffixes.
• Lemmatization reduces words to
their lemma, or dictionary form,
which maintains semantic meaning
more accurately than stemming.
Inverted Index
We keepa dictionary of terms. Then
for each term, we have a list that
records which documents the term
occurs in. Each item in the list is
conventionally called a posting. The
list is then called a postings list.
16.
Index Construction
Index constructionalgorithms and
techniques
• Blocked Sort-Based Indexing
• Single-Pass In-Memory Indexing
• Distributed Indexing
• Dynamic Indexing
17.
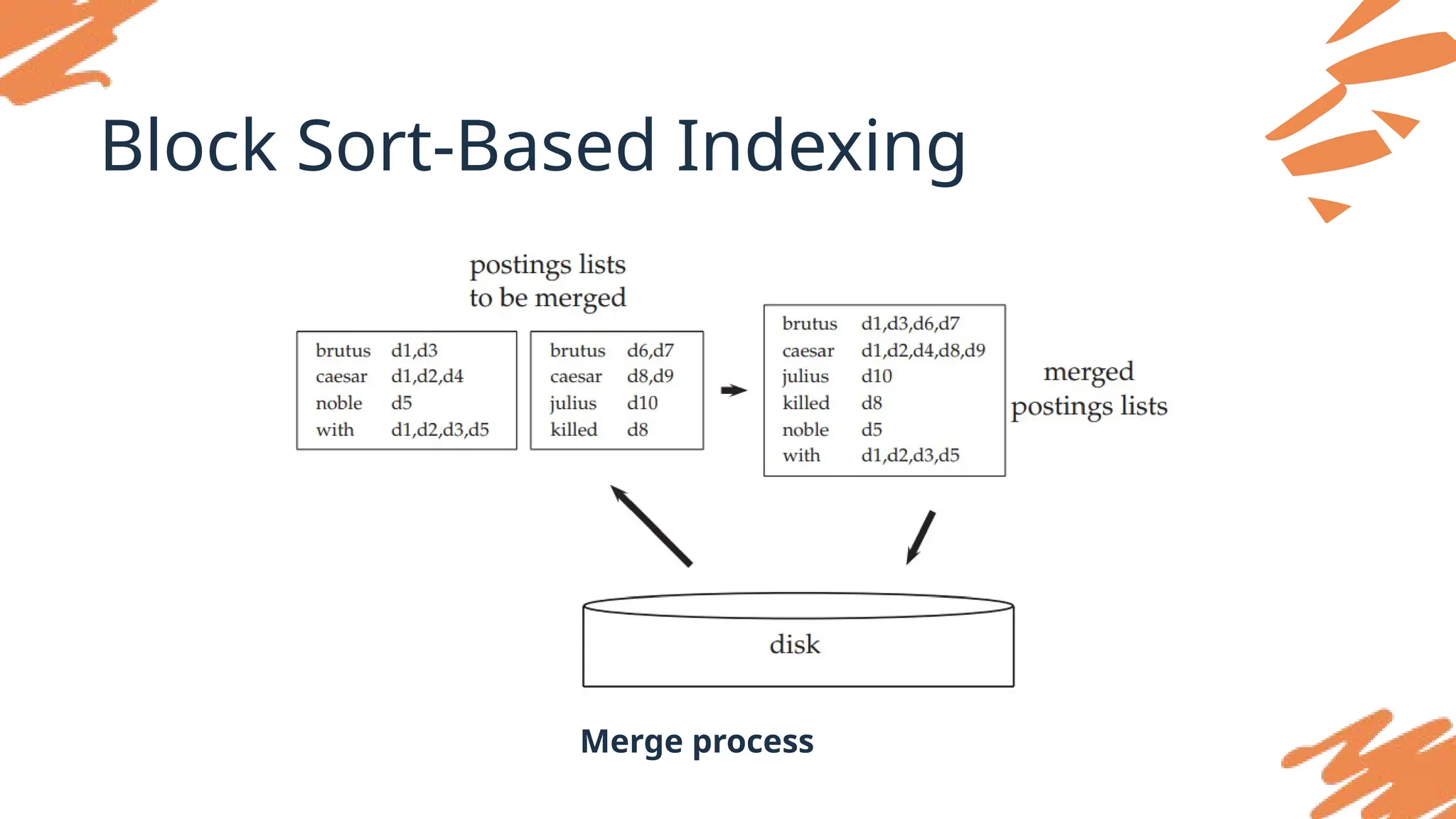
Block Sort-Based Indexing
BlockedSort-Based Indexing (BSBI) is an indexing method that builds an
inverted index by processing large datasets in manageable chunks or
"blocks," which are then merged to create the final index.
This approach is particularly useful when indexing large datasets that do not
fit in memory.
18.
Block Sort-Based Indexing
Indexingprocess:
• Documents are divided into fixed-size blocks (e.g., 100,000 documents
per block).
• Indexing Each Block:
⚬ Each block is read into memory, and a term-document mapping is
created for that block.
⚬ The terms are sorted within each block to construct a local inverted
index.
• The individual sorted blocks are written to disk. After all blocks have been
processed, a multi-way merge algorithm is used to combine them into
a single, comprehensive inverted index.
Single-Pass In-Memory Indexing
Single-PassIn-Memory Indexing (SPIMI) is an alternative to BSBI designed
for efficiency by avoiding repeated sorting operations. Instead, SPIMI builds
each block of the index in a single pass, reducing the memory needed for
term storage.
22.
Single-Pass In-Memory Indexing
SPIMIindexing process
• Unlike BSBI, SPIMI processes each term immediately. Terms are not stored for
later sorting, they are indexed as they appear in documents.
• Building posting lists:
⚬ As terms are encountered, SPIMI creates a posting list for each unique
term.
⚬ If the term already exists, SPIMI simply updates the list with the new
document information.
• Once the memory is full, the block (containing all posting lists for terms
processed so far) is written to disk, and memory is cleared for the next block.
• Similar to BSBI, the individual blocks are merged to create the final inverted
index.
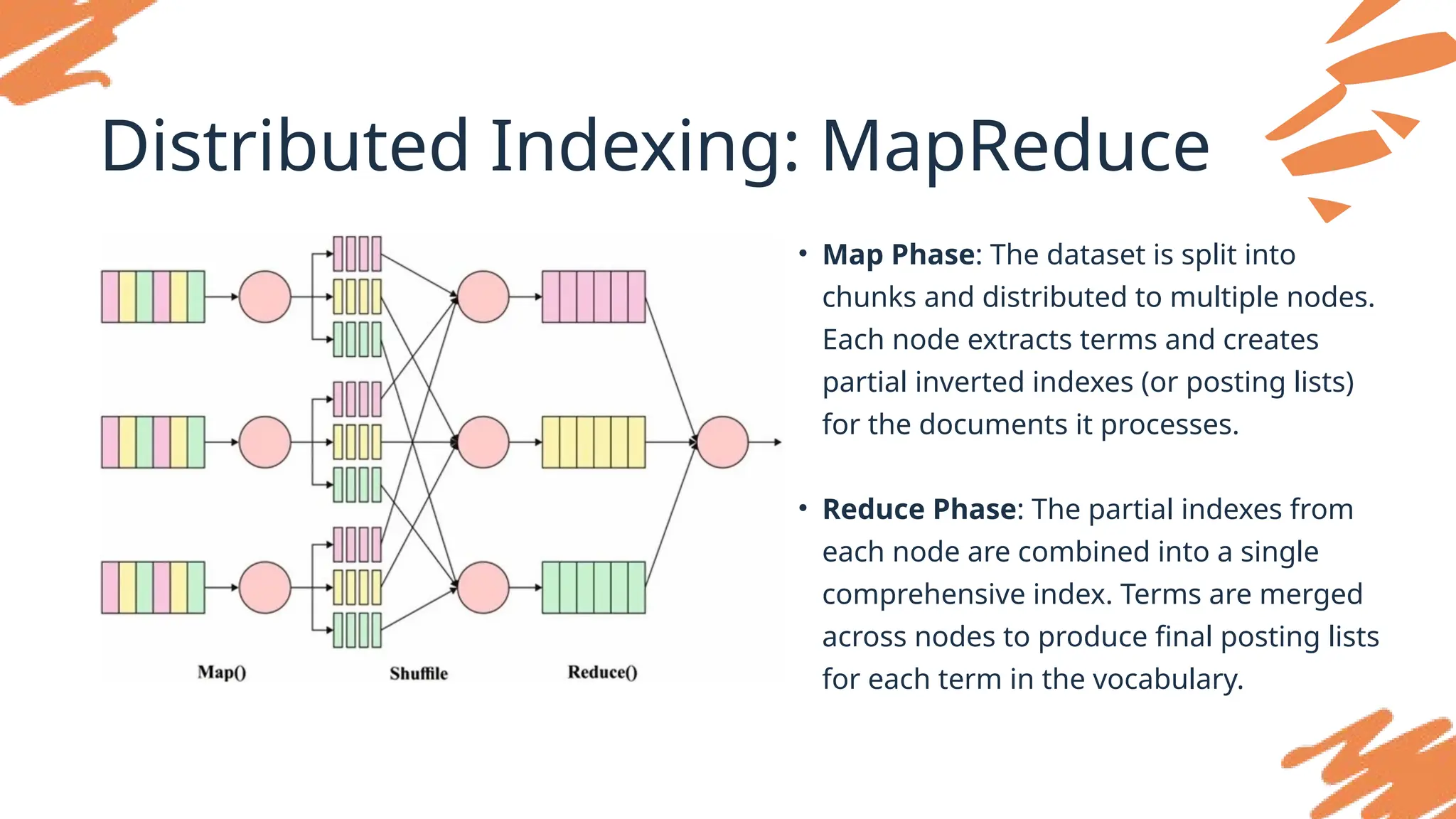
Distributed Indexing
As datasizes increase, indexing single-machine
capabilities become insufficient.
Distributed Indexing addresses this by distributing
the workload across multiple machines or nodes,
allowing for faster processing and larger index sizes.
25.
• Map Phase:The dataset is split into
chunks and distributed to multiple nodes.
Each node extracts terms and creates
partial inverted indexes (or posting lists)
for the documents it processes.
• Reduce Phase: The partial indexes from
each node are combined into a single
comprehensive index. Terms are merged
across nodes to produce final posting lists
for each term in the vocabulary.
Distributed Indexing: MapReduce
Dynamic Indexing
In manyreal-world scenarios, new documents are added, and old documents may be
removed or modified frequently. Dynamic Indexing is designed to handle such changes
without needing to rebuild the entire index.
Approach to Updates:
• For new documents, a separate in-memory index is created, which contains the
latest updates.
• Periodically, the in-memory index is merged with the main index to maintain a
single, consistent index.
• When a document is removed, a "deletion marker" is added to the in-memory index
to signal that the document should no longer appear in search results. During
periodic merges, these markers are used to purge entries from the main index.
28.
Index Compression: Why?
Indexcompression is essential in Information Retrieval systems to:
• Reduce the storage size of indexes
• Optimize memory usage
• Speed up retrieval operations
By compressing both the dictionary and the postings files, IR systems can
handle large-scale datasets more efficiently.
29.
Dictionary as anArray
The simplest data structure for the dictionary is to sort the vocabulary
lexicographically and store it in an array of fixed-width entries
Problem: Using fixed-width entries for terms is clearly wasteful, as the average
length of a term in English is just about eight characters
30.
Dictionary as aString
We can overcome the fixed-width entries shortcomings by storing the
dictionary terms as one long string of characters.
31.
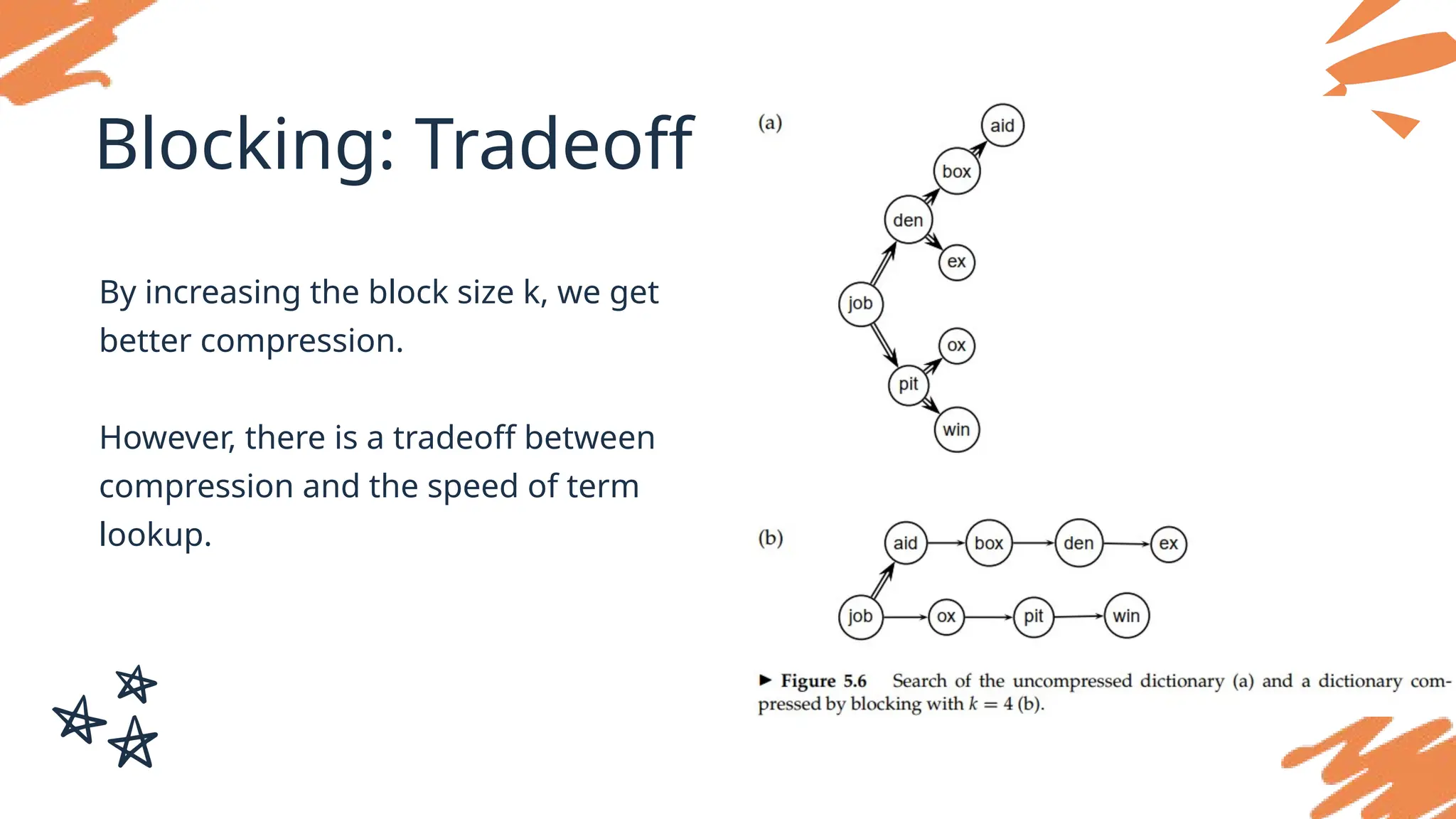
Blocking
We can furthercompress the dictionary by grouping terms in the string into blocks
of size k and keeping a term pointer only for the first term of each block.
32.
Blocking: Tradeoff
By increasingthe block size k, we get
better compression.
However, there is a tradeoff between
compression and the speed of term
lookup.
33.
Front Coding
A commonprefix is identified for a subsequence of the term list and then referred
to with a special character.
34.
Minimal Perfect Hashing
Otherschemes with even greater compression rely on minimal perfect hashing,
that is, a hash function that maps M terms onto [1, . . . , M] without collisions.
However, we cannot adapt perfect hashes incrementally because each new term
causes a collision and therefore requires the creation of a new perfect hash
function. Therefore, they cannot be used in a dynamic environment.
Boolean Retrieval Model
TheBoolean retrieval model is a model for information retrieval in which we can
pose any query in the form of a Boolean expression of terms.
• AND: All terms connected by AND must be present in the document for it to be
retrieved.
• OR: At least one of the terms connected by OR must be present in the
document.
• NOT: The term following NOT must not be present in the document.
37.
Vector Space Model
Inthe case of large document collections, the resulting number of matching
documents can far exceed the number a human user could possibly sift through.
Accordingly, it is essential for a search engine to rank-order the documents
matching a query. To do this, the search engine computes, for each matching
document, a score with respect to the query at hand.
Vector space model (VSM) can achieve this by viewing each document as a vector
of such weights, we can compute a score between a query and each document.
This view is known as vector space scoring.
38.
Term Weighting: tf-idf
Insteadof using raw word counts, we compute a term weight for each
document word. One of the most common term weighting schemes is the tf-
idf weighting, which is the product of two terms:
• Term frequency (tf): the number of occurrences of term t in document d
• Inverse document frequency (idf): Inverse of document frequency,
which is the number of documents in the collection that contain a term t
39.
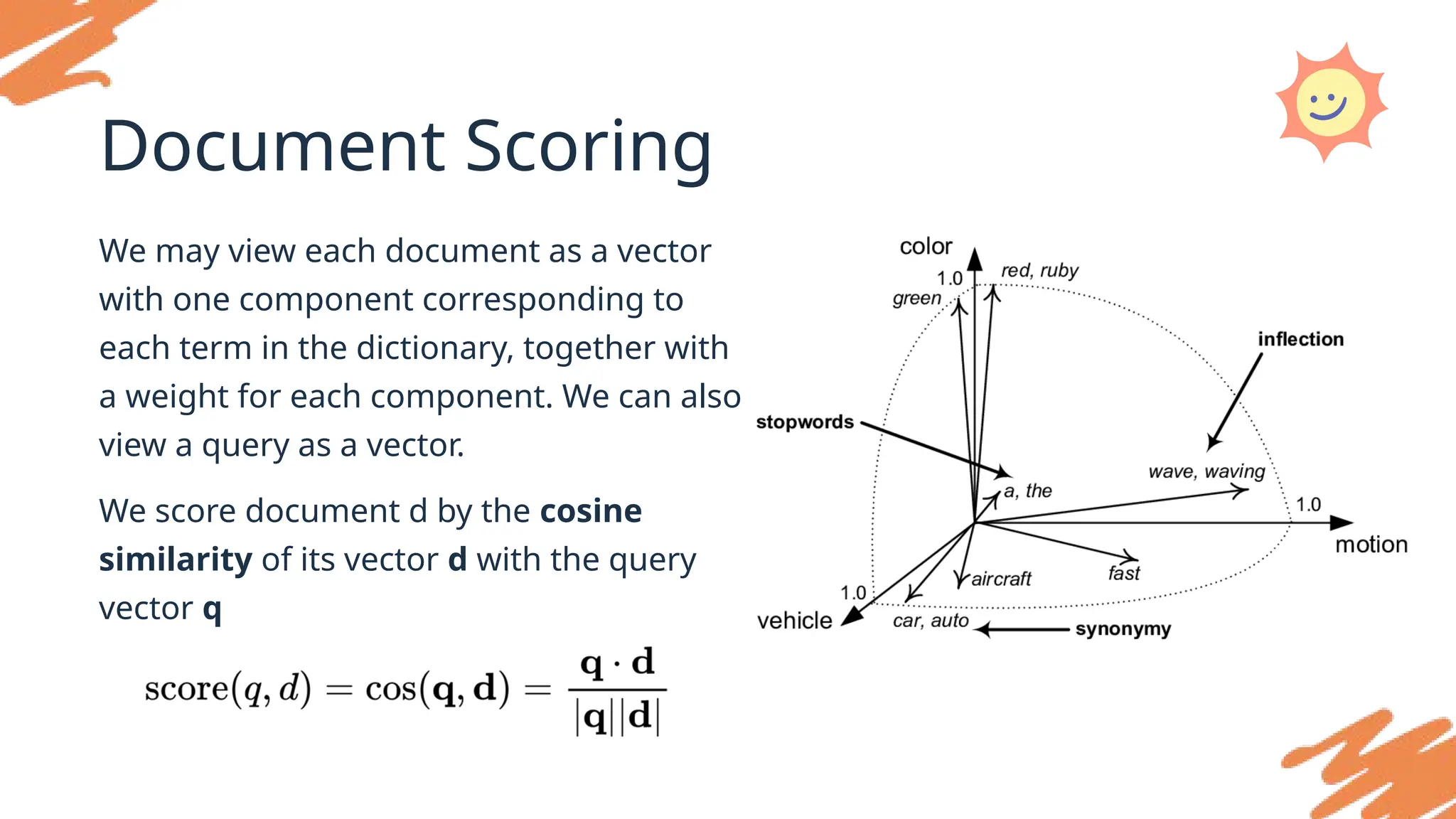
Document Scoring
We mayview each document as a vector
with one component corresponding to
each term in the dictionary, together with
a weight for each component. We can also
view a query as a vector.
We score document d by the cosine
similarity of its vector d with the query
vector q
40.
Probabilistic Models
In theBoolean or vector space models of IR, matching is done in a formally
defined but semantically imprecise calculus of index terms.
• Given only a query, an IR system has an uncertain understanding of
the information need.
• Given the query and document representations, a system has an
uncertain guess of whether a document has content relevant to the
information need.
Probability theory provides a principled foundation for such reasoning
under uncertainty. We can use probabilistic models to estimate how likely
it is that a document is relevant to an information need.
41.
Probability Ranking Principle
Theobvious order in which to present documents to the user is to rank
documents by their estimated probability of relevance with respect to the
information need:
This is the basis of the Probability Ranking Principle (PRP), shortly stated as:
An IR system should rank documents based on the probability that a document is
relevant to a query.
42.
Binary Independence Model
TheBinary Independence Model (BIM) is the model that has traditionally been
used with the PRP. It introduces some simple assumptions:
• Binary: Documents and queries are both represented as binary term
incidence vectors, where each entry has the value of 1 if the corresponding
term is presented in the document/query and 0 otherwise
• Independence: Terms are modeled as occurring in documents independently.
The model recognizes no association between terms.
43.
BIM: Relevance Probability
Underthe BIM, we model the probability that a document is relevant via the
probability in terms of term incidence vectors.
Using the Bayes rule we have:
44.
BIM: Ranking Function
Giventhose relevance probability, we can rank documents by their odds of
relevance:
We can further simplify this formula using the established assumptions,
eventually we arrive at the Retrieval Status Value (RSV):
45.
Okapi BM25
The BIMwas originally designed for short catalog records and abstracts of fairly
consistent length, and it works reasonably in these contexts, but for modern full-
text search collections, it seems clear that a model should pay attention to term
frequency and document length, as in VSM.
The BM25 weighting scheme, often called Okapi weighting, after the system in
which it was first implemented, was developed as a way of building a probabilistic
model sensitive to these quantities while not introducing too many additional
parameters into the model.
46.
Okapi BM25: RankingFunction
The retrieval status value formula used in BM25 weight scheme is:
Tuning parameters:
• k1 for document term frequency scaling (k1 > 0)
• b for the scaling by document length (0 b 1)
≤ ≤
• k3 for term frequency scaling of the query (k3 > 0)
Neural Ranking Models
•Traditional retrieval models obtain ranking
scores by searching for exact matches of words
in both the query and the document.
• However, this limits the availability of positional
and semantic information and may lead to
vocabulary mismatch.
• By contrast, neural ranking models construct
query-to-document relevance structures to learn
feature representations automatically.
Hihi
Haha
Hehe
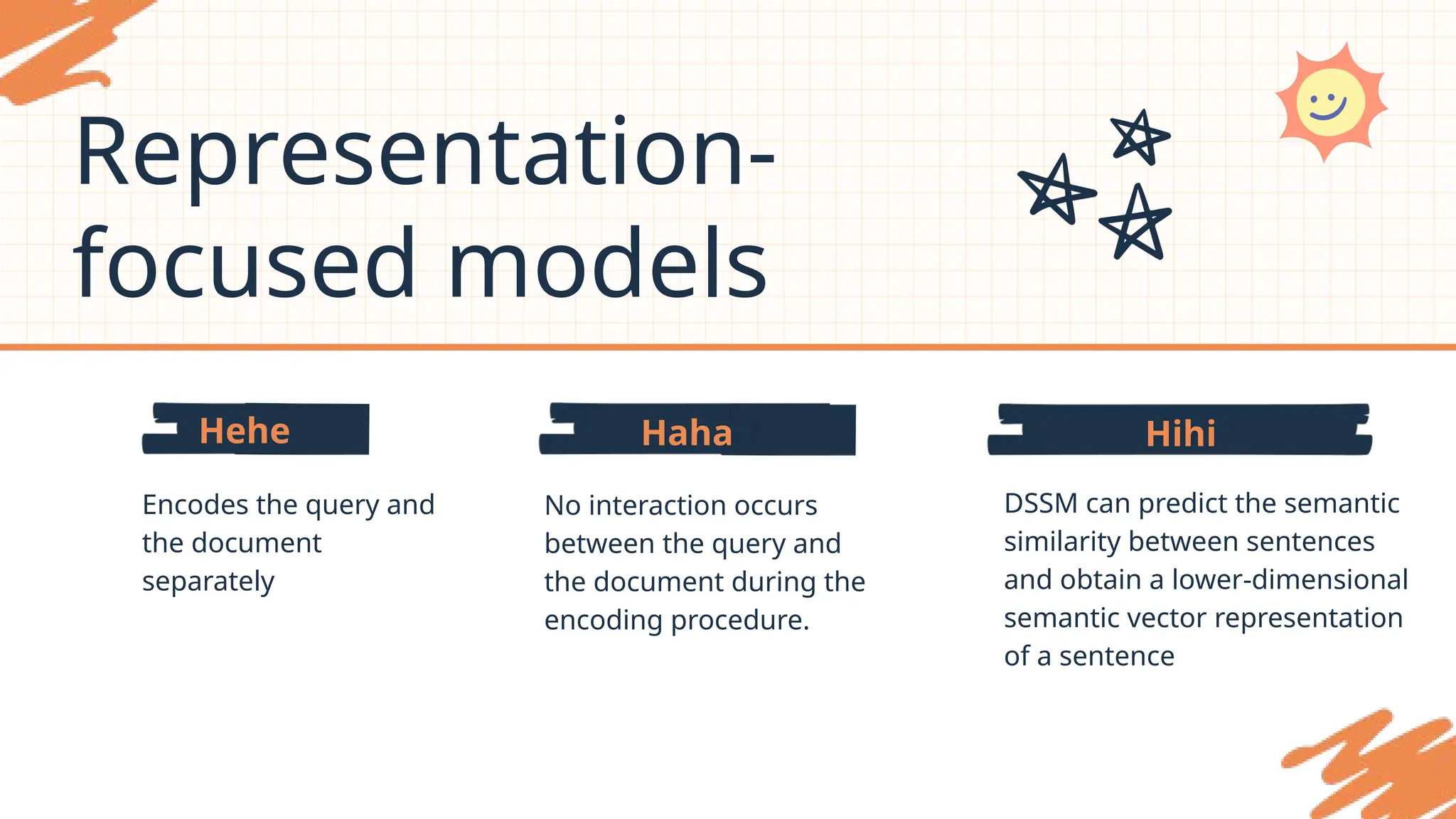
Representation-
focused models
Encodes thequery and
the document
separately
No interaction occurs
between the query and
the document during the
encoding procedure.
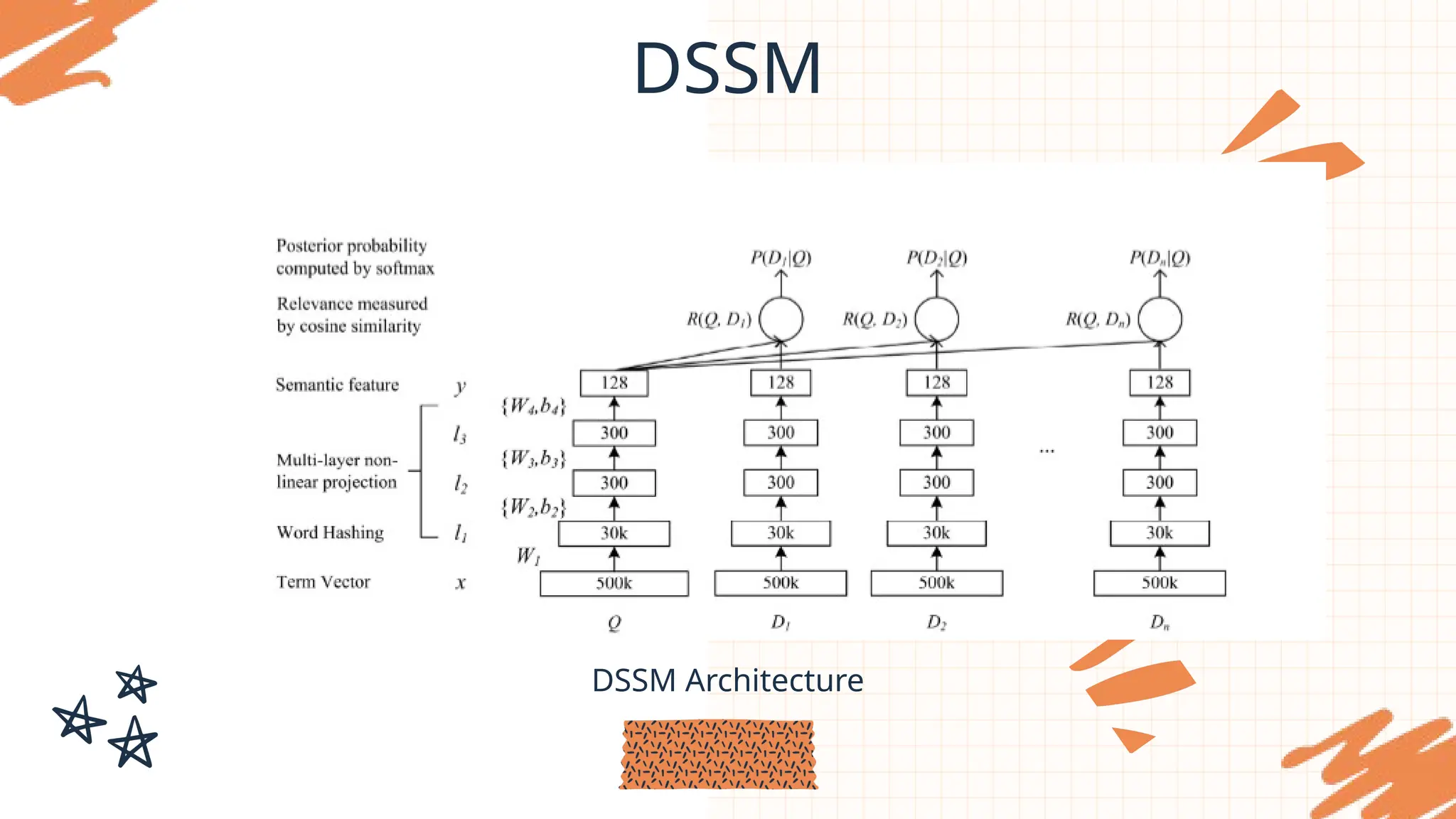
DSSM can predict the semantic
similarity between sentences
and obtain a lower-dimensional
semantic vector representation
of a sentence
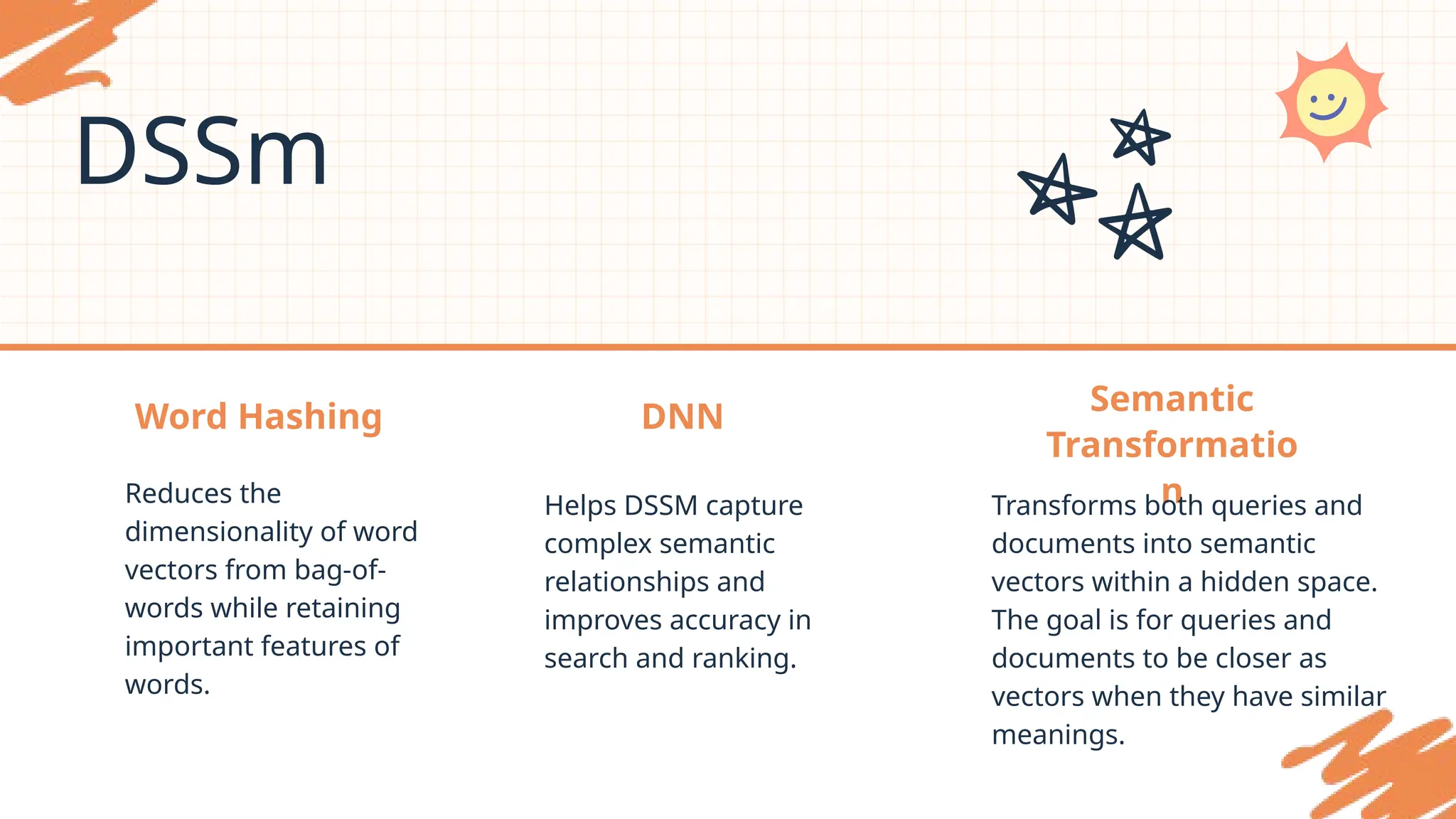
Semantic
Transformatio
n
DNN
Word Hashing
DSSm
Reduces the
dimensionalityof word
vectors from bag-of-
words while retaining
important features of
words.
Helps DSSM capture
complex semantic
relationships and
improves accuracy in
search and ranking.
Transforms both queries and
documents into semantic
vectors within a hidden space.
The goal is for queries and
documents to be closer as
vectors when they have similar
meanings.
53.
Loss Function
Similarity Function
DSSm
Measuresthe similarity
between the semantic
vectors of the query
and the document. The
closer the two vectors,
the higher the
relevance between the
query and the
document.
Pushes unrelated query-
document pairs farther apart
and pulls related pairs closer
together.
54.
Hihi
Haha
Hehe
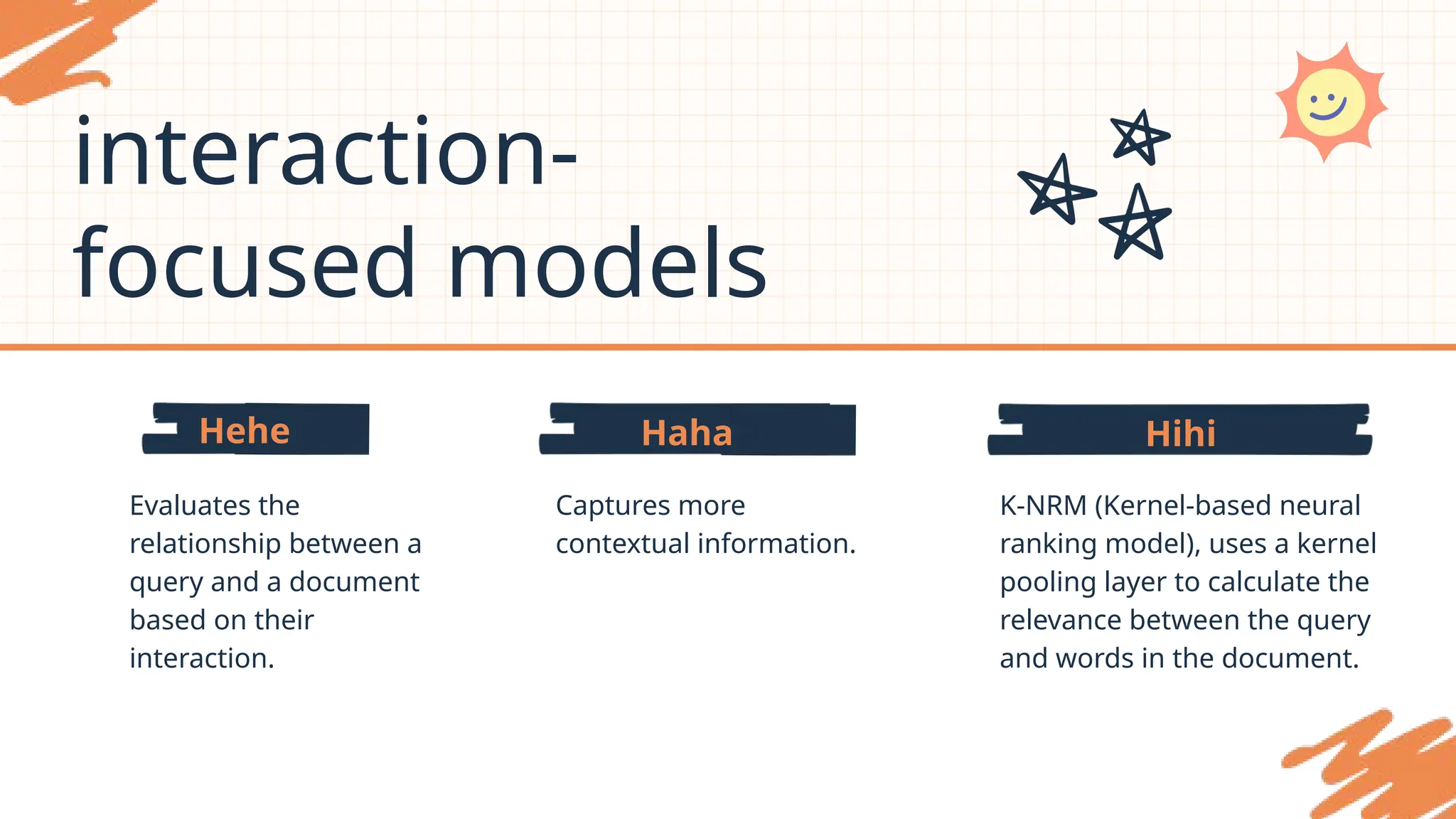
interaction-
focused models
Evaluates the
relationshipbetween a
query and a document
based on their
interaction.
Captures more
contextual information.
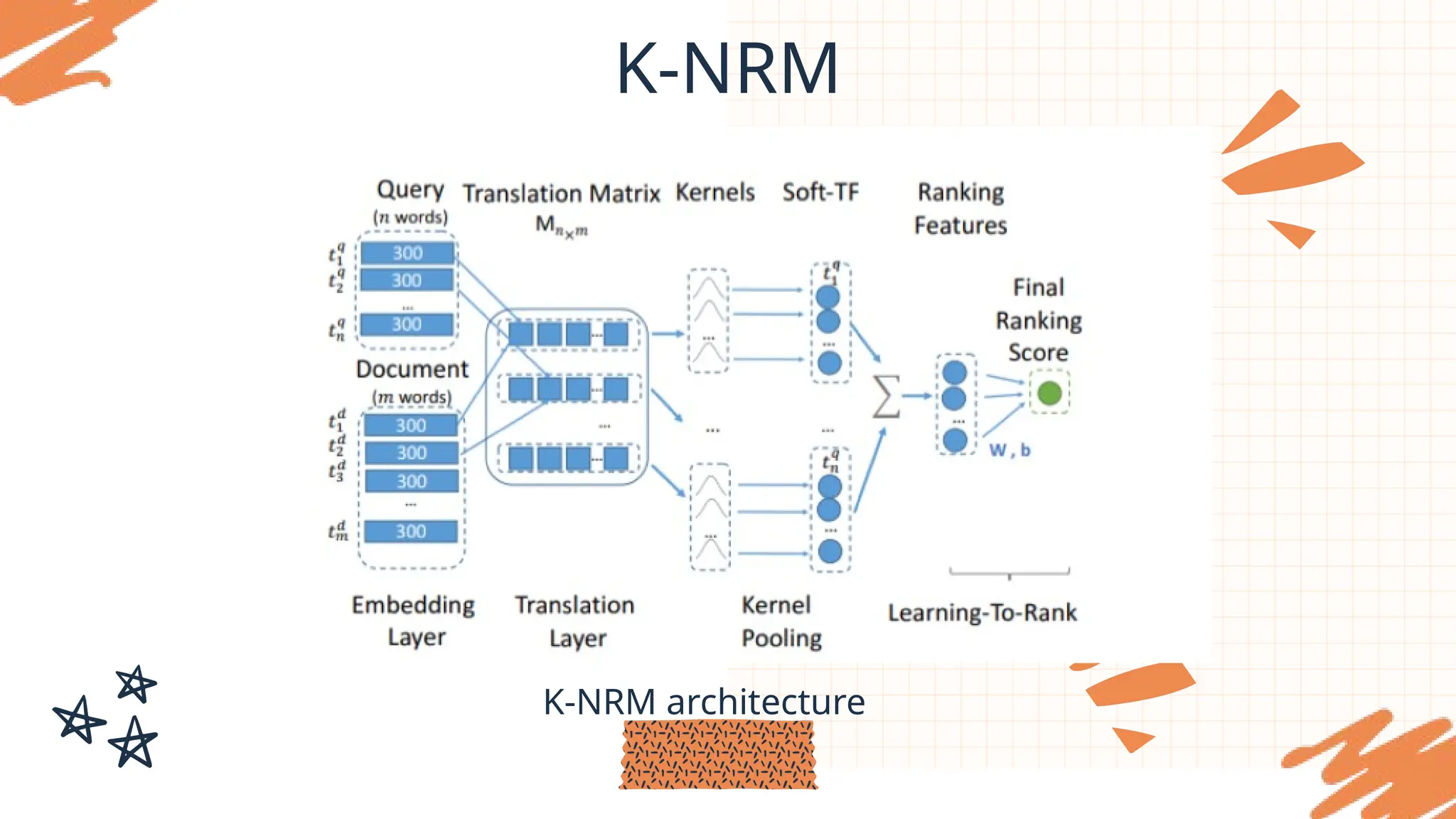
K-NRM (Kernel-based neural
ranking model), uses a kernel
pooling layer to calculate the
relevance between the query
and words in the document.
Pretrained Language Models
•Although all the methods
mentioned above improve
performance across various
information retrieval (IR)
applications, they do not perform
consistently well when trained on
small-scale data.
• Developing a better language
model is crucial for information
processing.
• Some pretrained language models
focus on deep transformer
architectures, such as GPT, BERT,
etc.
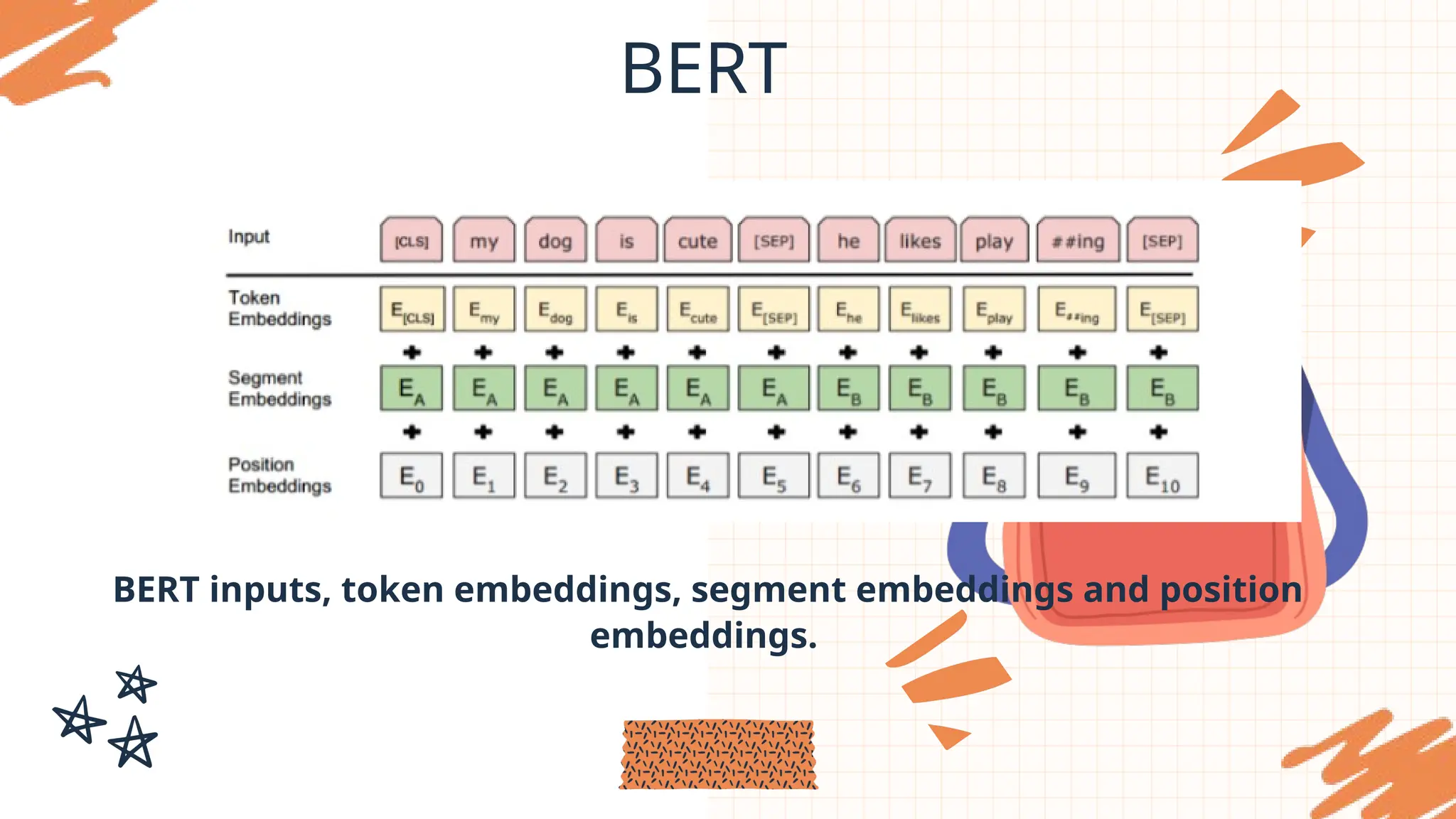
BERT
• BERT addressesthe limitations and disadvantages of ELMo and OpenAI GPT
(both are either undirectional or sequential, not exploiting contextual
relationships across all text inputs) by using pretraining objectives such as
MLM (Masked Language Model) and NSP (Next Sentence Prediction).
• 15% of WordPiece tokens are randomly selected for prediction.
• Each selected token has an 80% chance of being replaced with the [MASK]
token.
• There is a 10% chance that the token is replaced by a random token, and a 10%
chance it is kept as is.
60.
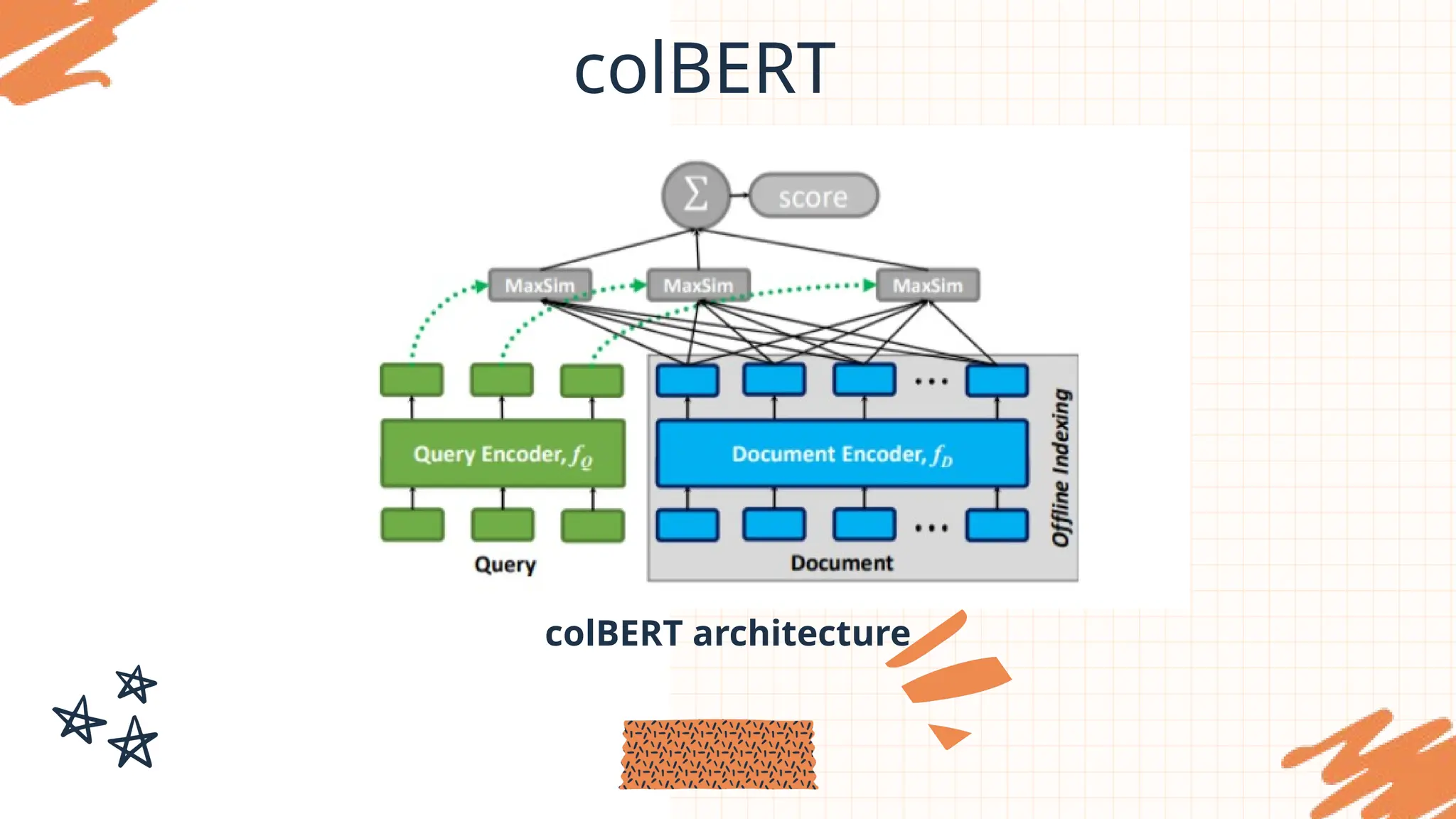
colBERT
• ColBERT (ContextualizedLate Interaction over BERT) is a model designed to
improve BERT's performance.
• ColBERT addresses several key challenges faced by traditional BERT models:
⚬ High computational cost.
⚬ Interaction latency.
⚬ Vector similarity search.
⚬ Scalability.
⚬ High performance.
colBERT
• CoLBERT consistsof 3 main components:
⚬ Query encoder.
⚬ Document encoder.
⚬ Late interaction mechanism.
63.
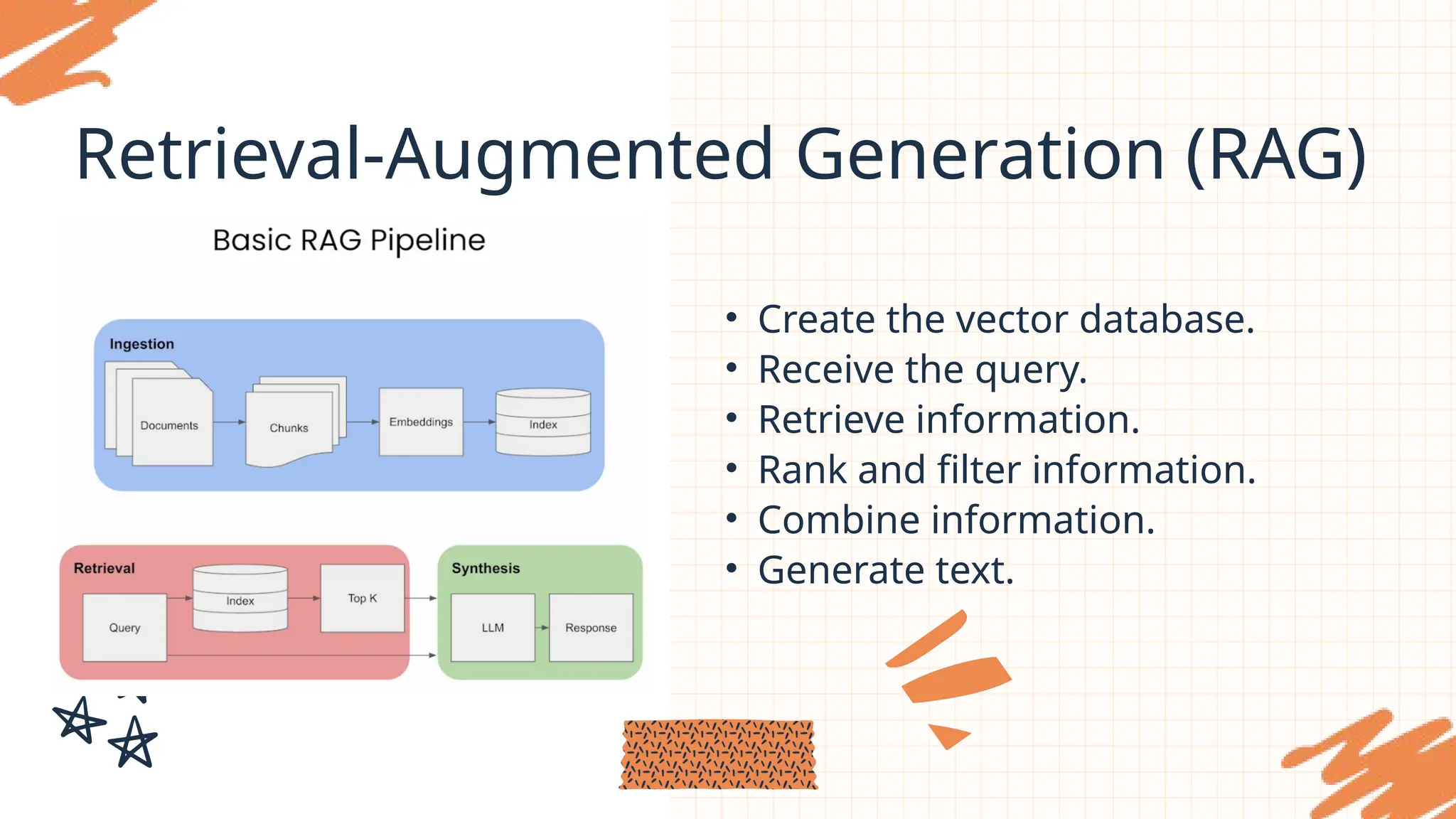
Retrieval-Augmented Generation (RAG)
RAGis an AI model that combines information retrieval
capabilities with the language generation abilities of large
language models (LLMs). It helps generate accurate, up-to-date
answers that closely align with factual information. By integrating
real-world data with the language skills of the model, RAG
minimizes "hallucination" errors, resulting in more reliable
responses.
Retrieval-Augmented Generation (RAG)
•Create the vector database.
• Receive the query.
• Retrieve information.
• Rank and filter information.
• Combine information.
• Generate text.
66.
Retrieval-Augmented Generation (RAG)
•Updated Information: Overcomes the
knowledge limitations of static language
models.
• Higher Accuracy: Reduces
misinformation.
• Cost Efficiency: Lowers the number of
tokens processed in the LLM model.
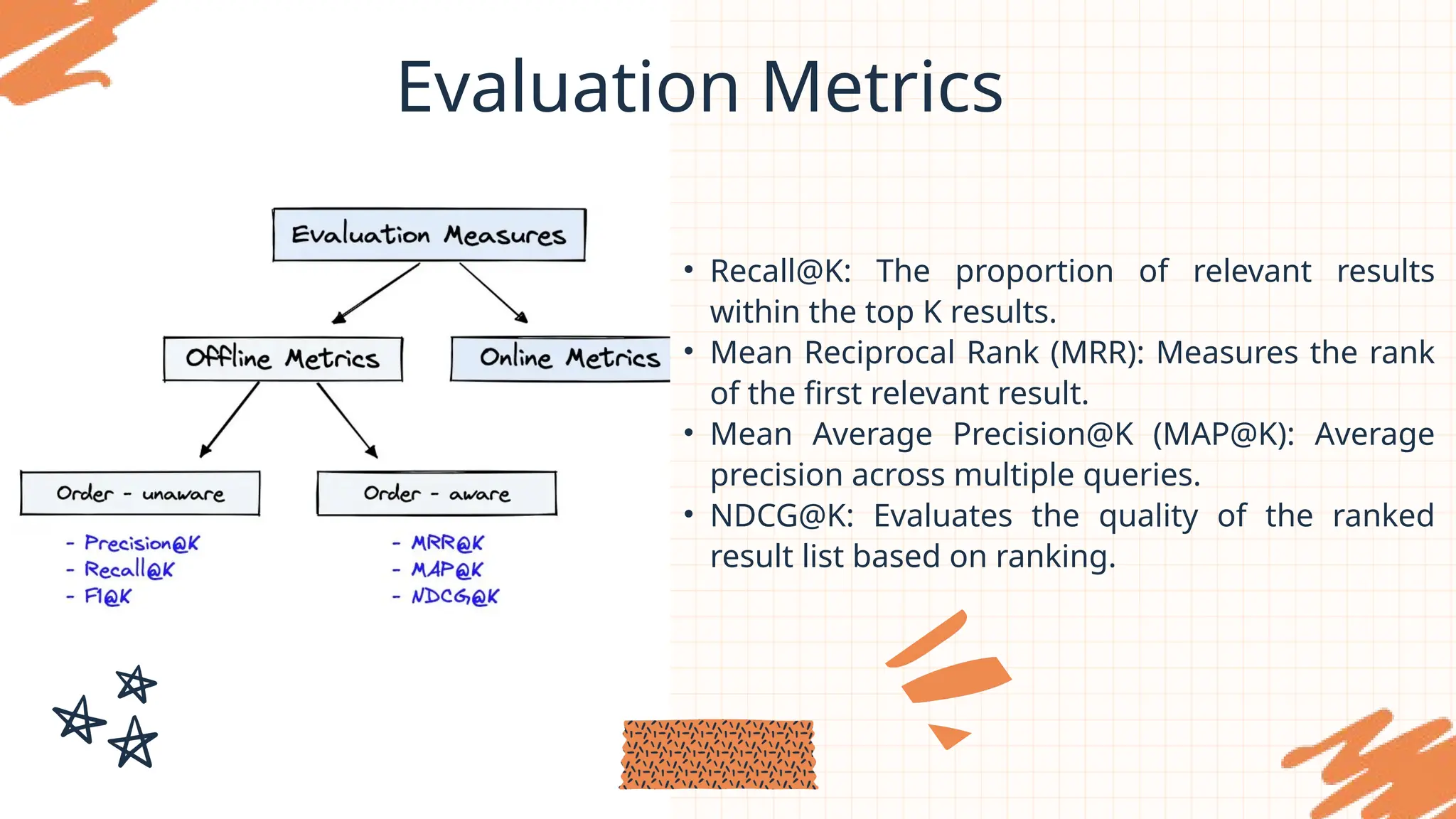
Evaluation Metrics
• OnlineMetrics: These measure user interactions
when the system is live, such as the click-through
rate (CTR).
• Offline Metrics: These are assessed before
deployment, focusing on the relevance of
returned results. They are often split into:
⚬ Order-aware: Metrics where the order of
results affects the score, such as NDCG@K.
⚬ Order-unaware: Metrics where order doesn’t
impact the score, such as Recall@K.
69.
Evaluation Metrics
• Recall@K:The proportion of relevant results
within the top K results.
• Mean Reciprocal Rank (MRR): Measures the rank
of the first relevant result.
• Mean Average Precision@K (MAP@K): Average
precision across multiple queries.
• NDCG@K: Evaluates the quality of the ranked
result list based on ranking.
General Application
• DigitalLibrary: Manages and provides access to
digital materials (text, images, audio, video).
• Information Filtering System: Eliminates
redundant information, such as spam filtering
and recommendation systems.
• Media Search: Finds images, music, and videos
based on keywords and features.
• Search Engine: Searches across the web,
desktop, mobile, and social media to meet users'
information needs.
72.
Domain applications ofIR techniques
Geography, Chemistry, Legal, and
Software Engineering: Domain-specific
search to support specialized information
retrieval within professional fields.
#15 We keep a dictionary of terms (sometimes also referred to as a vocabulary or lexicon).
Then for each term, we have a list that records which documents the term occurs in.
Each item in the list – which records that a term appeared in a document (and, later, often, the positions in the document) – is conventionally called a posting.
The list is then called a postings list (or inverted list), and all the postings lists taken together are referred to as the postings.
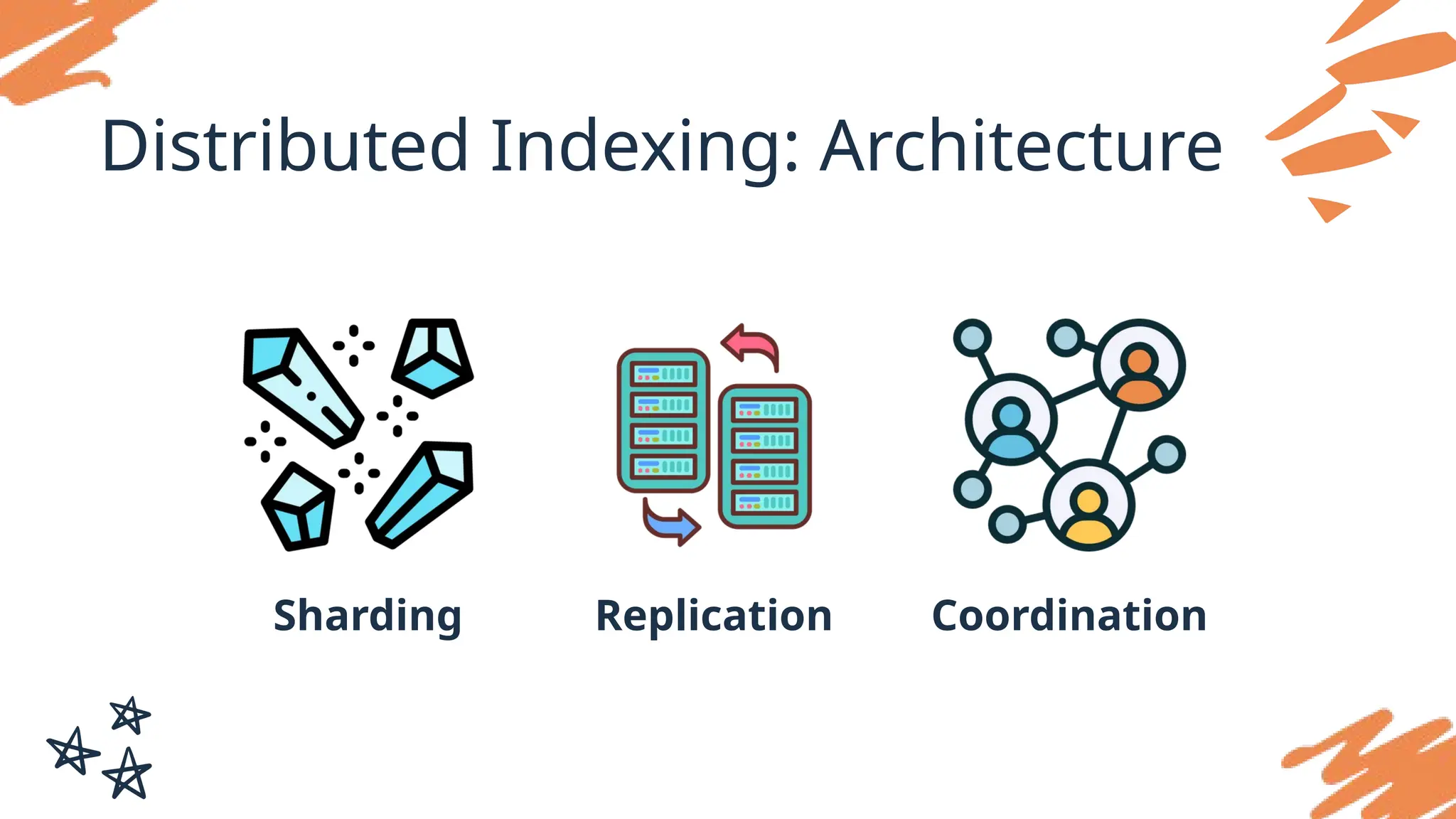
#26 Sharding: The document collection is divided into “shards,” each of which is handled by a different node. Each shard contains a subset of documents and has its own index.
Replication: To ensure fault tolerance and load balancing, shards are often replicated across multiple nodes. This way, if one node fails, another can take over its workload.
Coordination: A master node (or coordinator) manages shard assignment and oversees the indexing and retrieval processes, ensuring smooth distribution and merging.

























![Minimal Perfect Hashing
Other schemes with even greater compression rely on minimal perfect hashing,
that is, a hash function that maps M terms onto [1, . . . , M] without collisions.
However, we cannot adapt perfect hashes incrementally because each new term
causes a collision and therefore requires the creation of a new perfect hash
function. Therefore, they cannot be used in a dynamic environment.](https://image.slidesharecdn.com/mscesitmtn-250907184226-ab9fba32/75/Information-Retrieval-Natural-Language-Process-34-2048.jpg)















![BERT
• BERT addresses the limitations and disadvantages of ELMo and OpenAI GPT
(both are either undirectional or sequential, not exploiting contextual
relationships across all text inputs) by using pretraining objectives such as
MLM (Masked Language Model) and NSP (Next Sentence Prediction).
• 15% of WordPiece tokens are randomly selected for prediction.
• Each selected token has an 80% chance of being replaced with the [MASK]
token.
• There is a 10% chance that the token is replaced by a random token, and a 10%
chance it is kept as is.](https://image.slidesharecdn.com/mscesitmtn-250907184226-ab9fba32/75/Information-Retrieval-Natural-Language-Process-59-2048.jpg)