Download to read offline








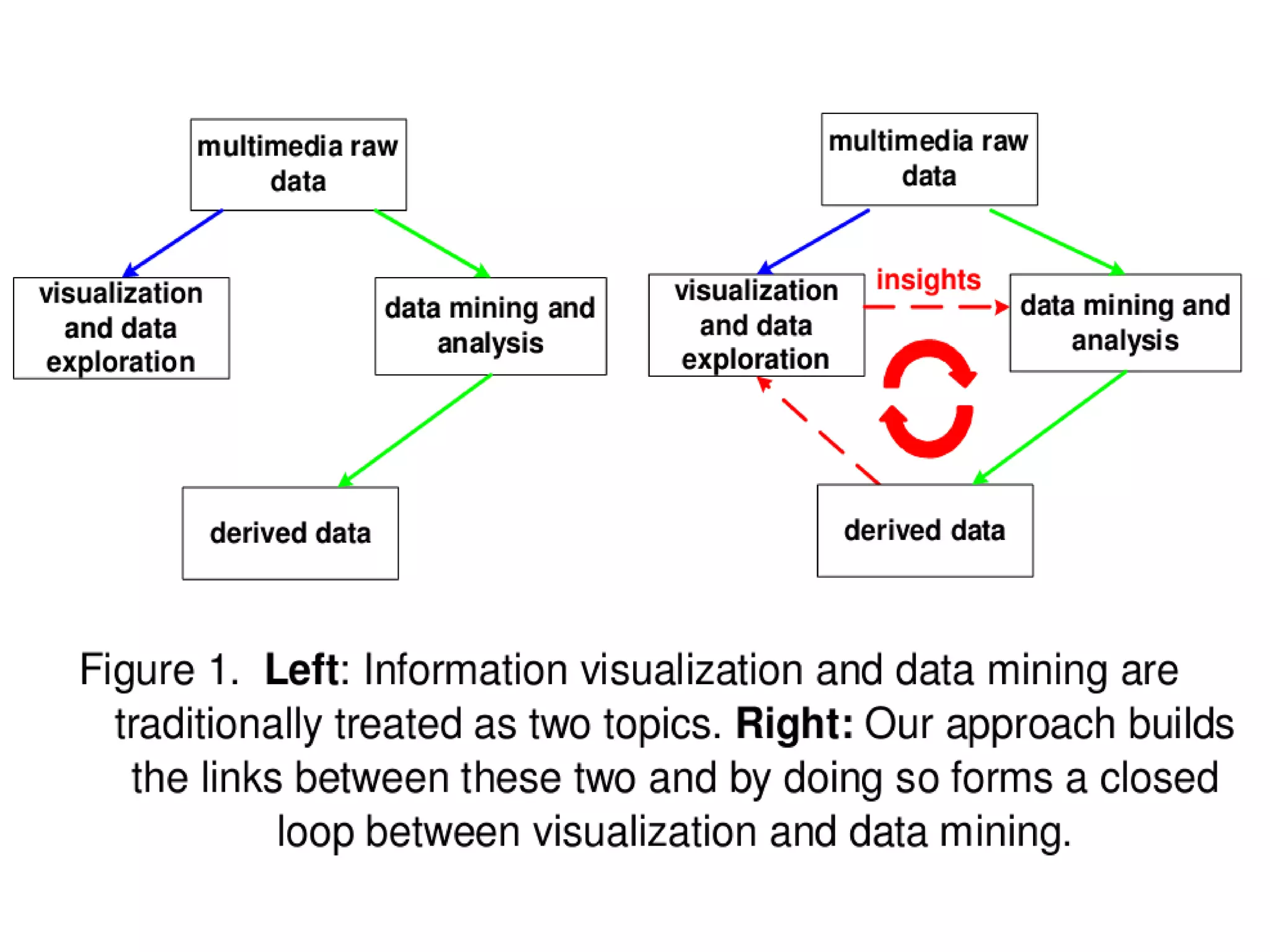

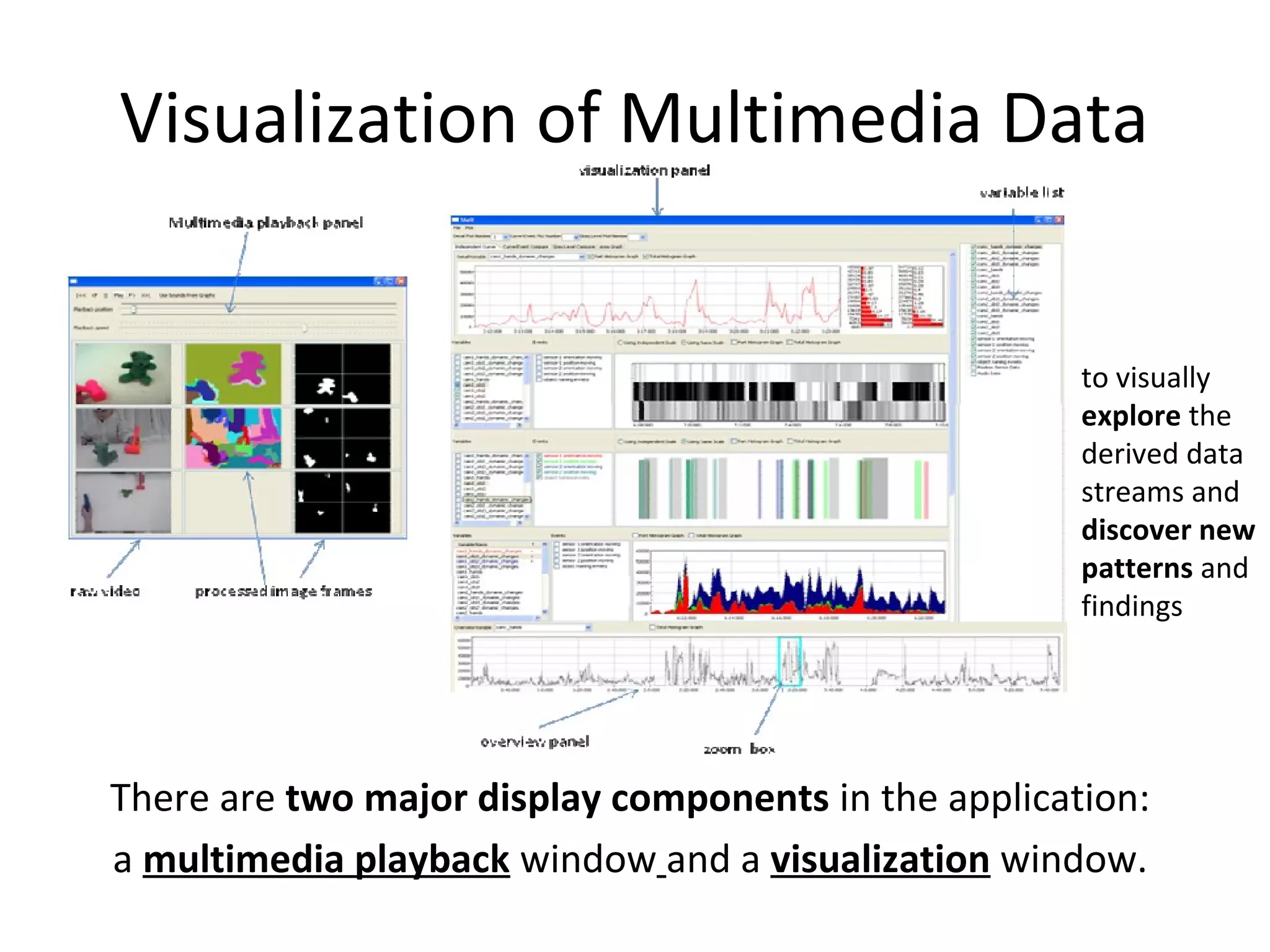


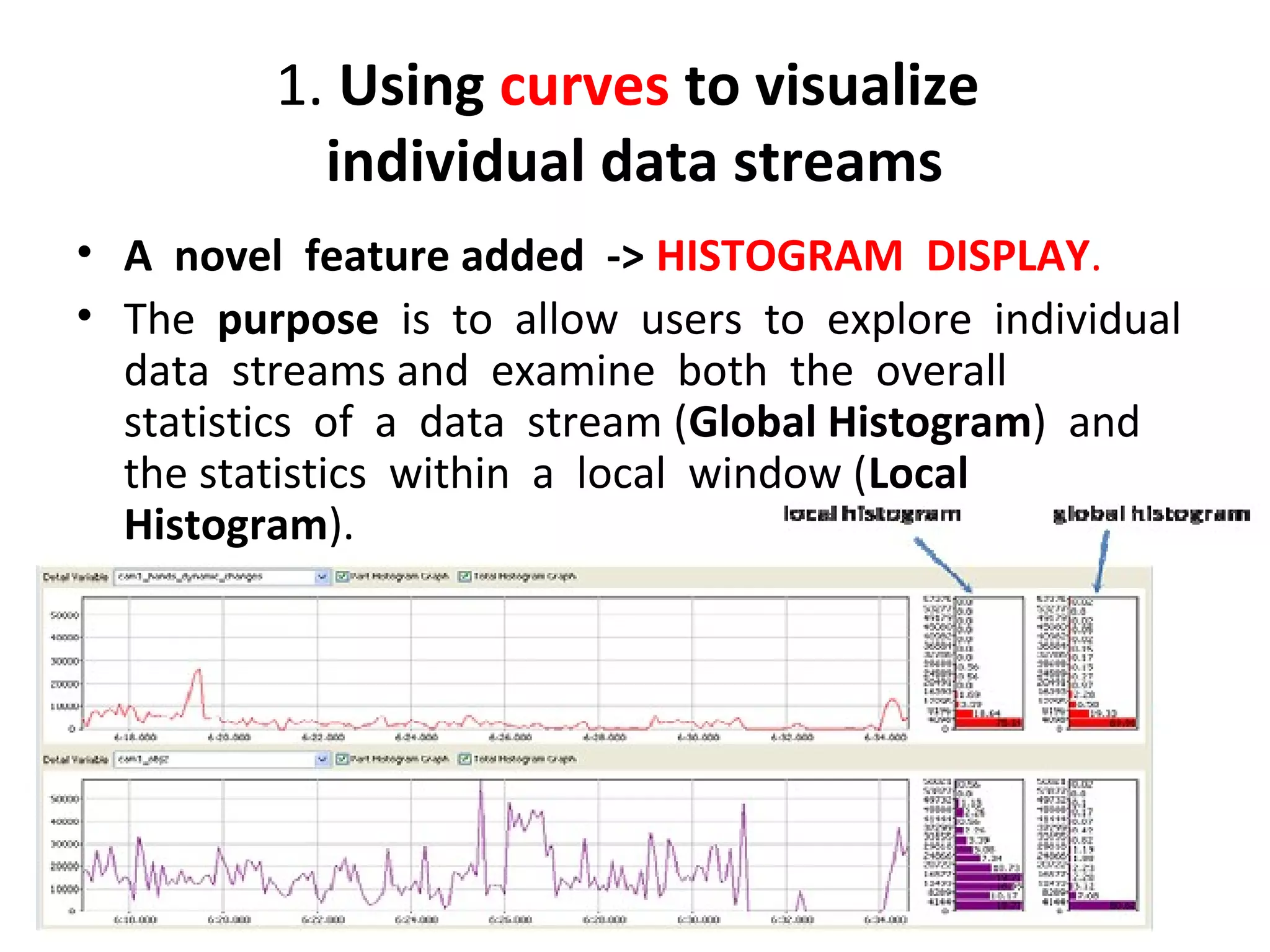

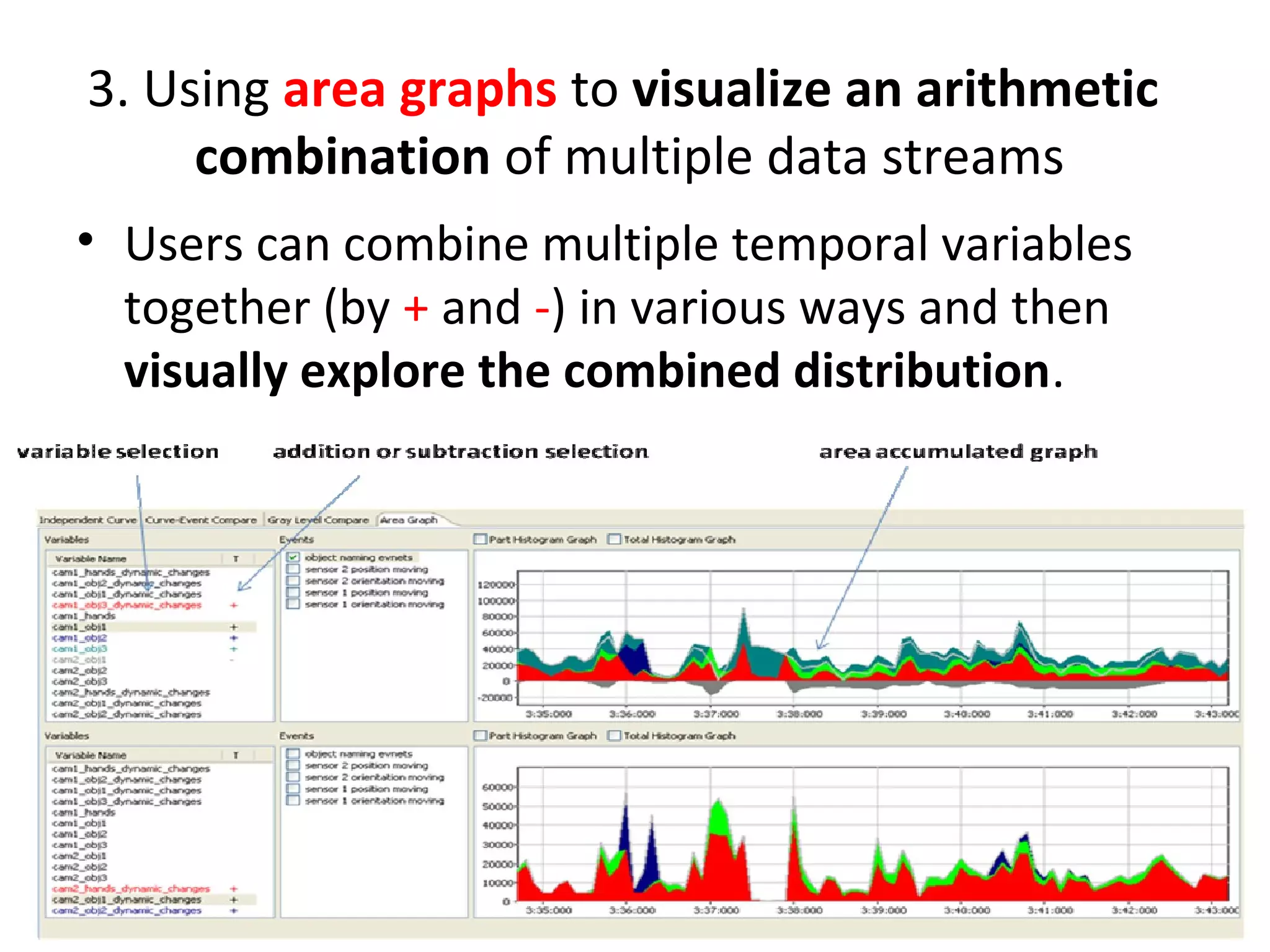

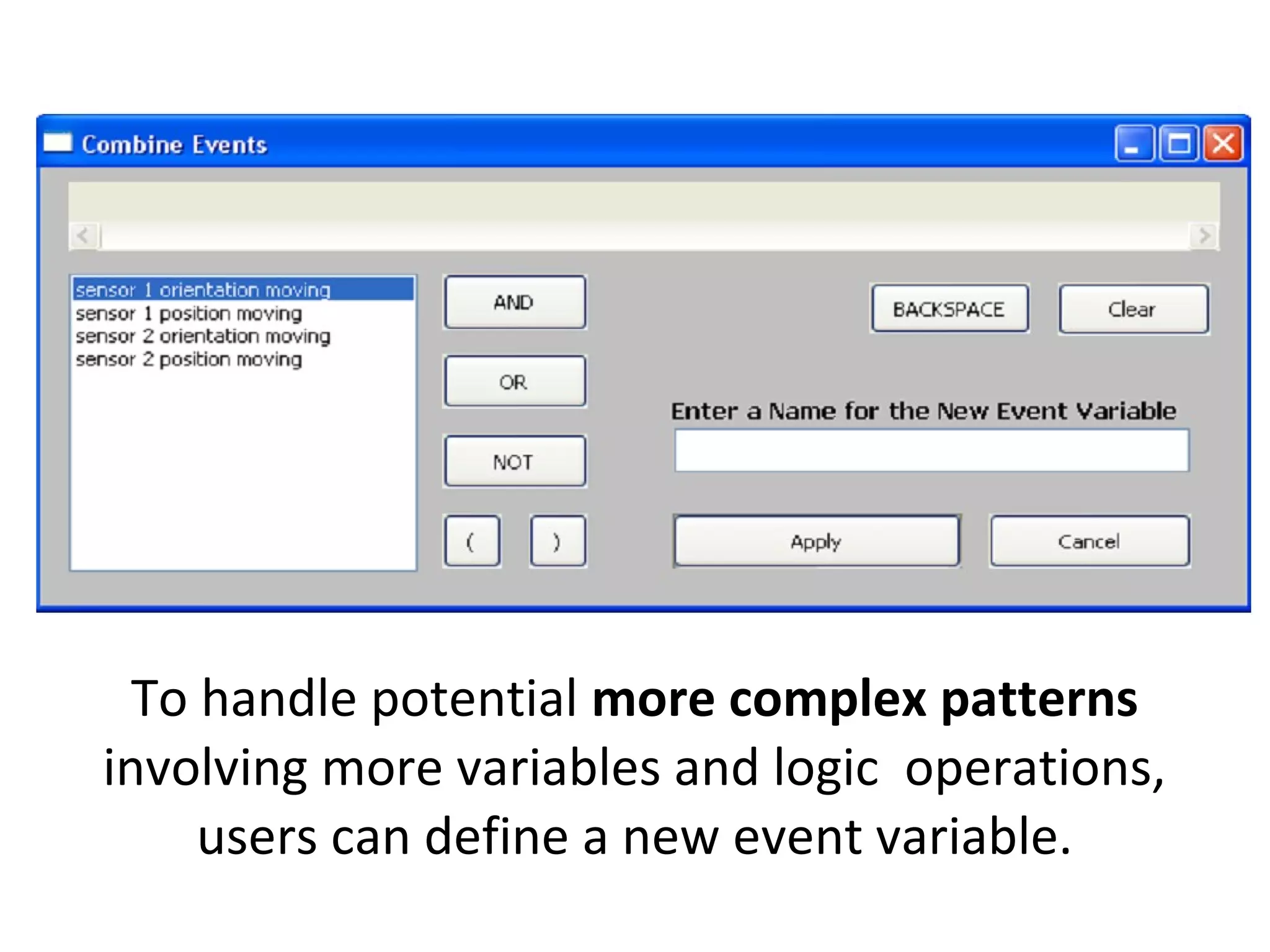
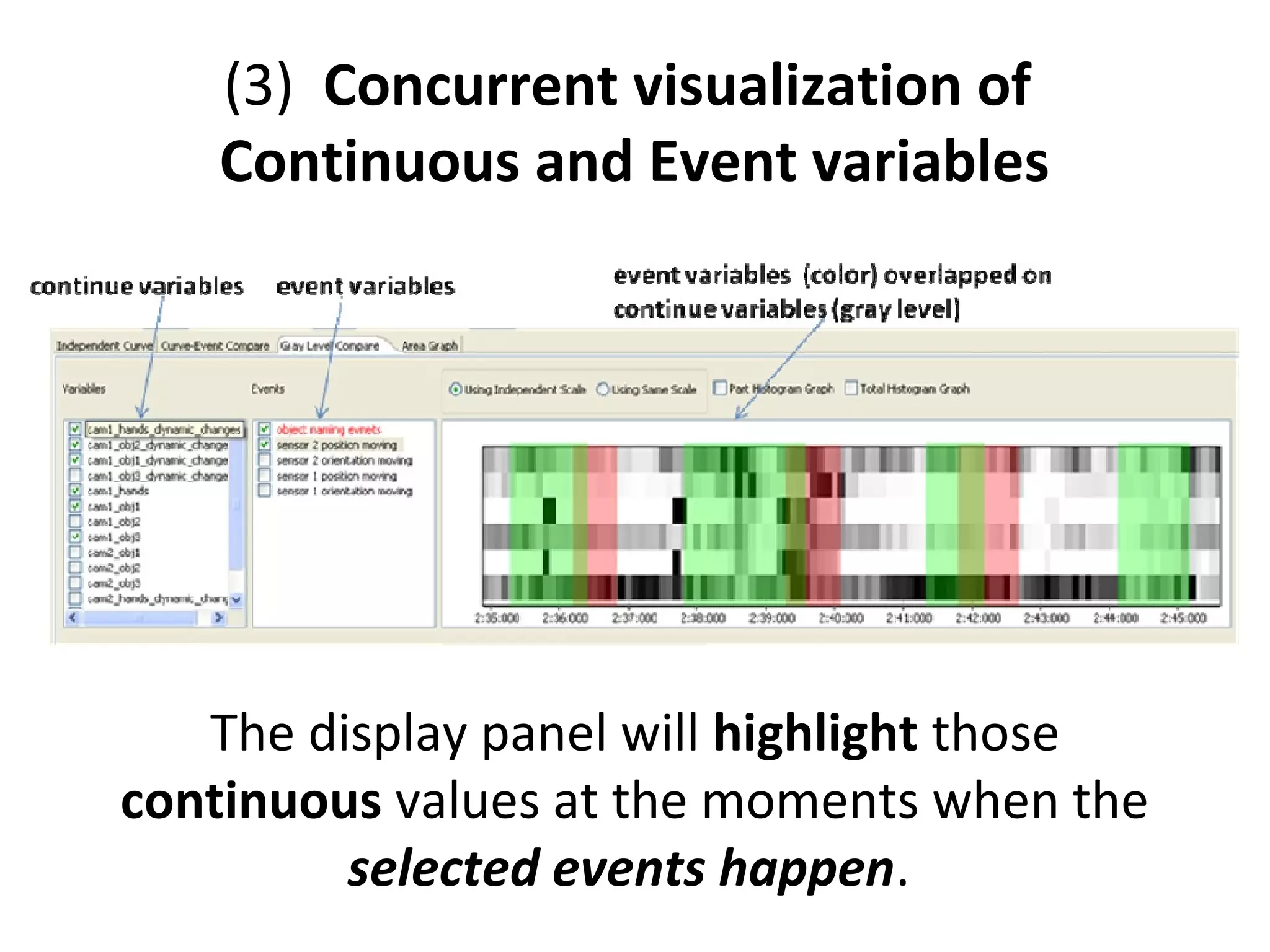
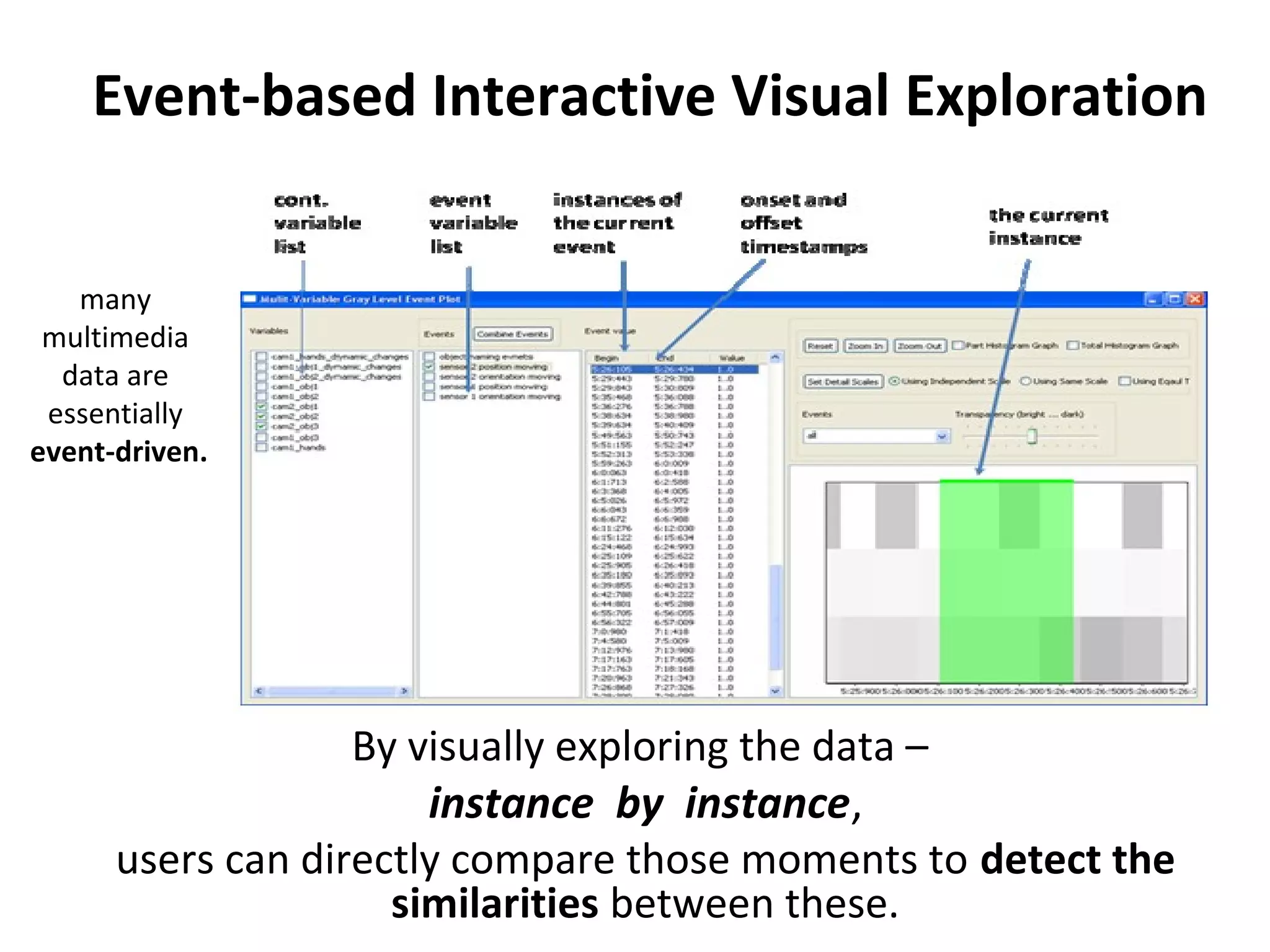
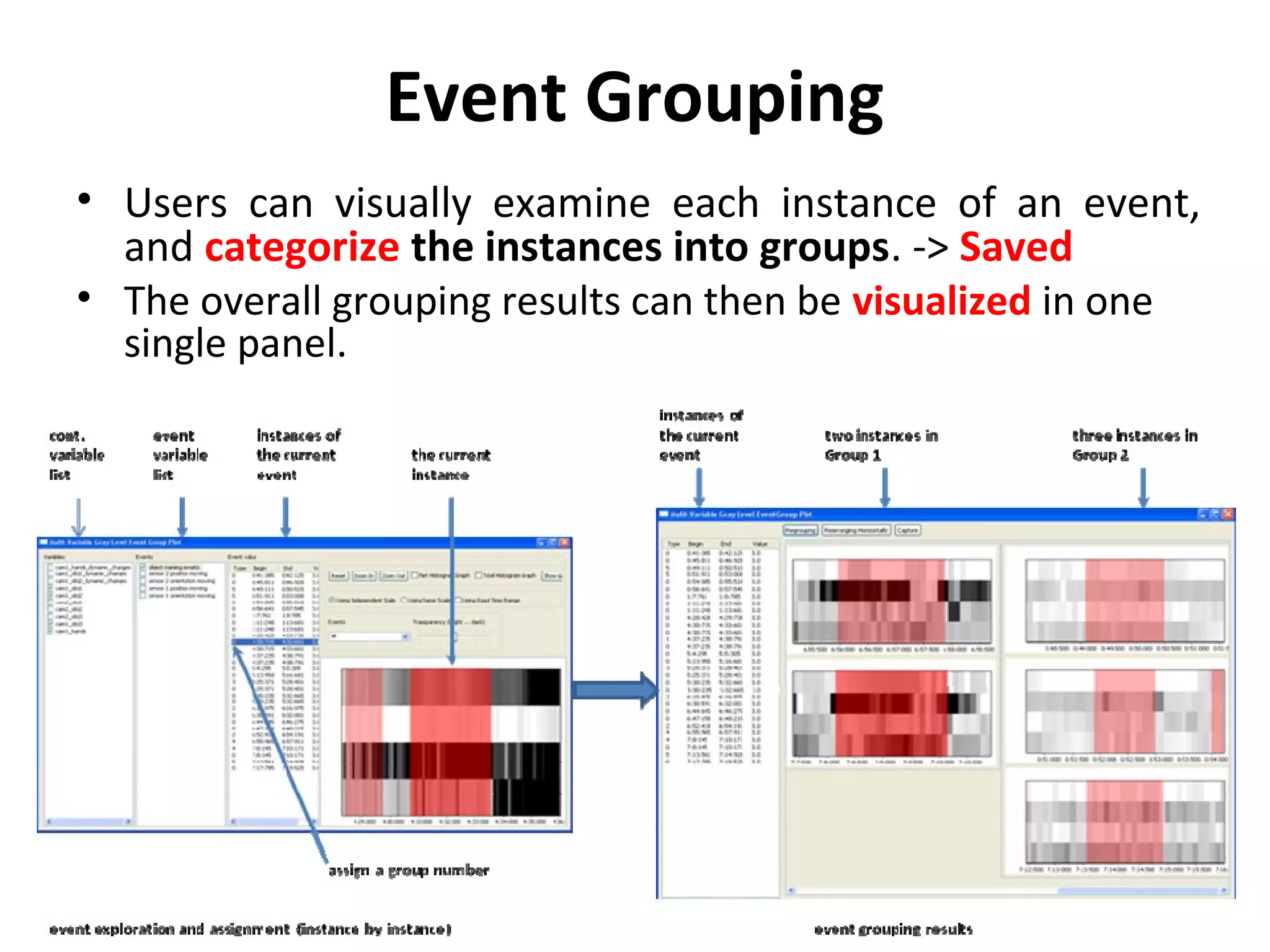












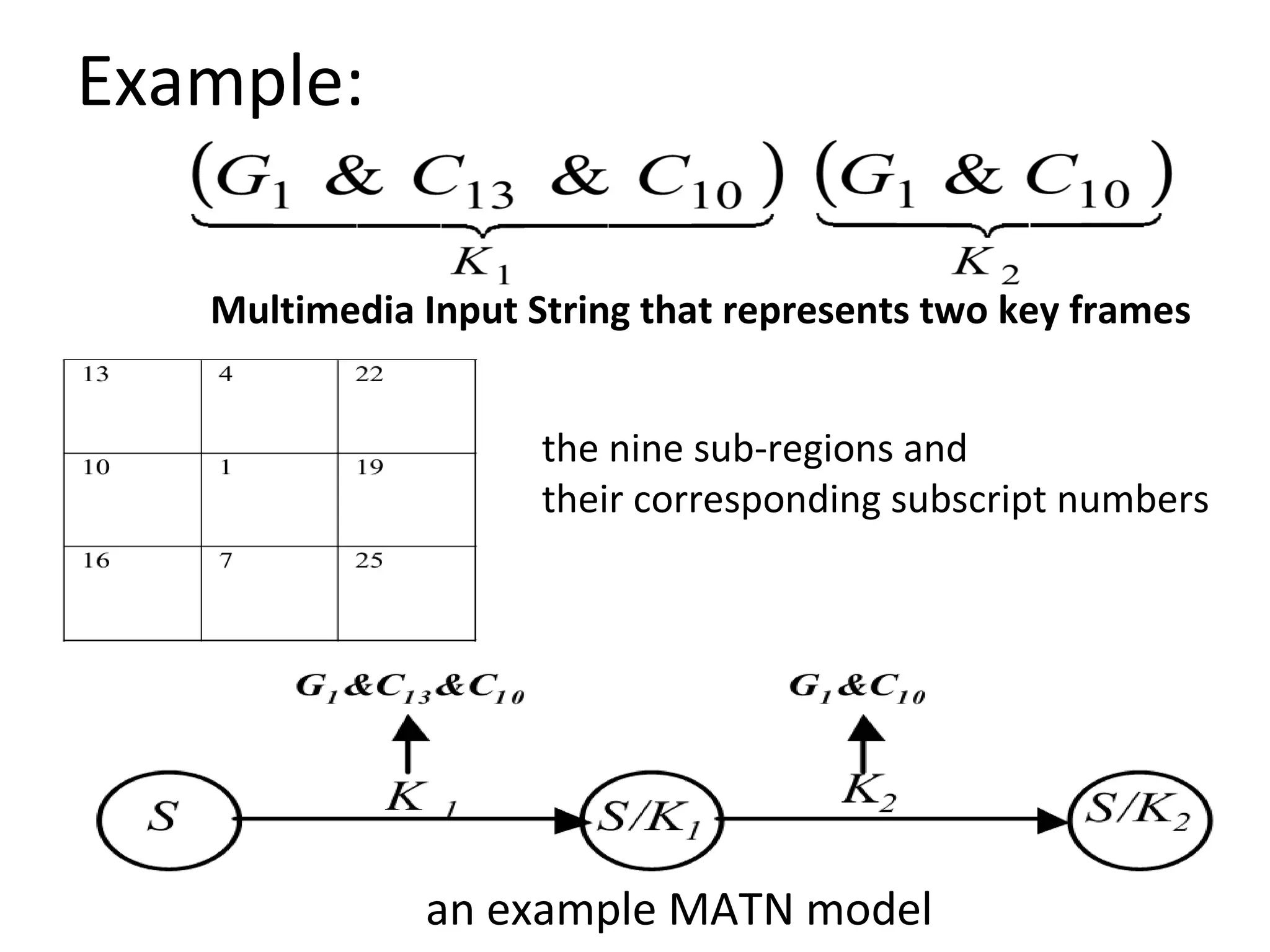


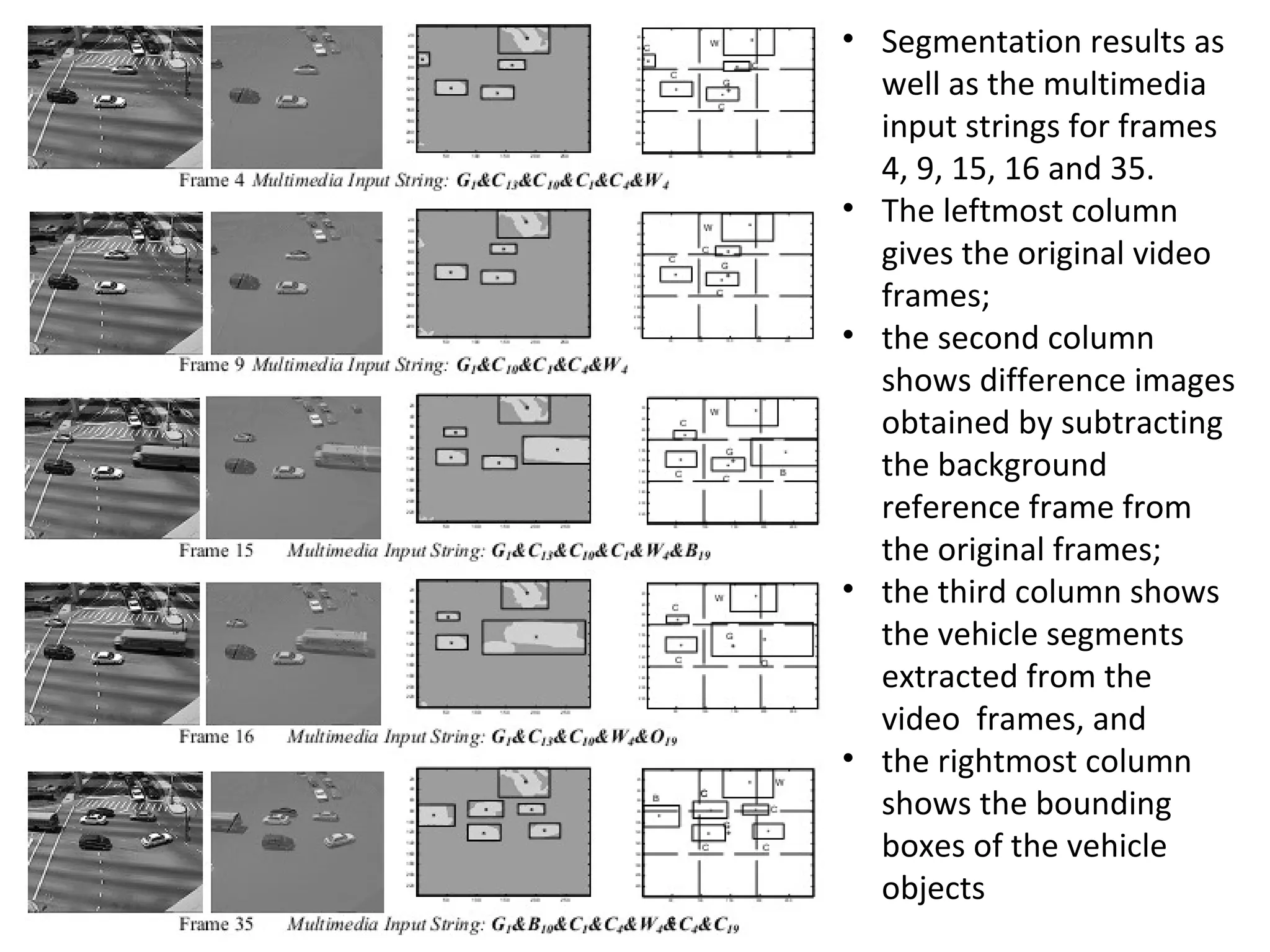










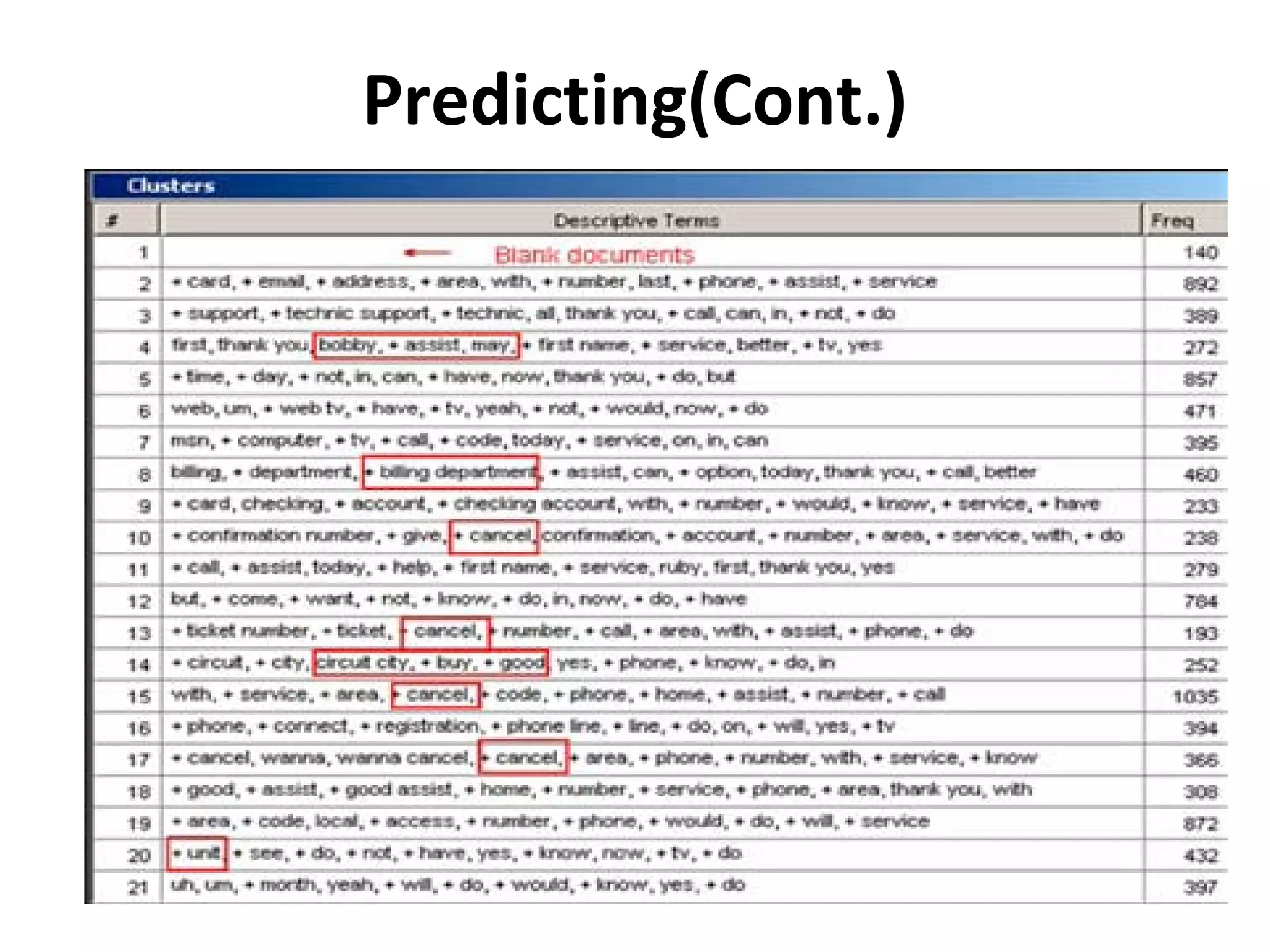









The document outlines a presentation on multimedia data mining. It discusses three articles: 1) a tool for visually mining multimedia data for social studies, 2) a framework for mining traffic video sequences, and 3) using voice mining to understand customer feedback. It also provides an introduction to multimedia data mining and recommendations.








































































